

Step-by-step guide on using theDuring this walkthrough, we will become familiar with the mainAutoRegressive ModelwithStatsforecast.
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation in other.
The text in this article is largely taken from: 1. Changquan Huang •
Alla Petukhina. Springer series (2022). Applied Time Series Analysis and
Forecasting with
Python. 2.
Jose A. Fiorucci, Tiago R. Pellegrini, Francisco Louzada, Fotios
Petropoulos, Anne B. Koehler (2016). “Models for optimising the theta
method and their relationship to state space models”. International
Journal of
Forecasting.
3. Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting
Principles and Practice (3rd ed)”
Table of Contents
- Introduction
- Autoregressive Models
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of AutoRegressive with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
Theautoregressive time series model (AutoRegressive) is a
statistical technique used to analyze and predict univariate time
series. In essence, the autoregressive model is based on the idea that
previous values of the time series can be used to predict future values.
In this model, the dependent variable (the time series) returns to
itself at different moments in time, creating a dependency relationship
between past and present values. The idea is that past values can help
us understand and predict future values of the series.
The autoregressive model can be fitted to different orders, which
indicate how many past values are used to predict the present value. For
example, an autoregressive model of order 1 uses only the
immediately previous value to predict the current value, while an
autoregressive model of order uses the previous
values.
The autoregressive model is one of the basic models of time series
analysis and is widely used in a variety of fields, from finance and
economics to meteorology and social sciences. The model’s ability to
capture nonlinear dependencies in time series data makes it especially
useful for forecasting and long-term trend analysis.
In a multiple regression model, we forecast the variable of interest
using a linear combination of predictors. In an autoregression model,
we forecast the variable of interest using a linear combination of
past values of the variable. The term autoregression indicates that it
is a regression of the variable against itself.
Definition of Autoregressive Models
Before giving a formal definition of the ARCH model, let’s define the components of an ARCH model in a general way:- Autoregressive, a concept that we have already known, is the construction of a univariate time series model using statistical methods, which means that the current value of a variable is influenced by past values of itself in different periods.
- Heteroscedasticity means that the model can have different magnitudes or variability at different time points (variance changes over time).
- Conditional, since volatility is not fixed, the reference here is the constant that we put in the model to limit heteroscedasticity and make it conditionally dependent on the previous value or values of the variable.
- If a time series is stationary and satisfies such an equation as (1), then we call it an process.
- For simplicity, we often assume that the intercept (const term) ; otherwise, we can consider where .
- We distinguish the concept of models from the concept of processes. models may or may not be stationary and processes must be stationary.
- means that in the past has nothing to do with at the current time .
- Like the definition of MA models, sometimes εt in Eq.(1) is called the innovation or shock term.
Definition of PACF
Let be a stationary time series with . Here the assumption is for conciseness only. If , it is okay to replace by . Now consider the linear regression (prediction) of on for any integer . We use to denote this regression (prediction): where satisfy That is, are chosen by minimizing the mean squared error of prediction. Similarly, let denote the regression (prediction) of on : Note that if is stationary, then . Now let and . Then is the residual of removing the effect of the intervening variables from , and is the residual of removing the effect of from . Definition 2. The partial autocorrelation function(PACF) at lag of astationary time series with is and According to the property of correlation coefficient (see, e.g., P172, Casella and Berger 2002), |φkk| ≤ 1. On the other hand, the following theorem paves the way to estimate the PACF of a stationary time series, and its proof can be seen in Fan and Yao (2003). On the other hand, the following theorem paves the way to estimate the PACF of a stationary time series, and its proof can be seen in Fan and Yao (2003). Theorem 1. Let be a stationary time series with , and satisfy Then for .Properties of Autoregressive Models
From the model, namely, Eq. (1), we can see that it is in the same form as the multiple linear regression model. However, it explains current itself with its own past. Given the past we have This suggests that given the past, the right-hand side of this equation is a good estimate of . Besides Now we suppose that the AR(p) model, namely, Eq. (1), is stationary; then we have- The model mean .Thus,themodelmean if and only if .
- If the mean is zero or ((3) and (4) below have the same assumption), noting that , we multiply Eq. (1) by , take expectations, and then get
- For all , the partial autocorrelation , that is, the PACF of models cuts off after lag , which is very helpful in identifying an model. In fact, at this point, the predictor or regression of on is
- We multiply Eq.(1)by ,take expectations,divide by ,and then obtain the recursive relationship between the autocorrelations:
- Since the model is a stationary now, naturally it satisfies . Hence . If the model is further Gaussian and a sample of size is given, then (a) as ; (b) according to Quenouille (1949), for asymptotically follows the standard normal(Gaussian) distribution , or is asymptotically distributed as .
Stationarity and Causality of AR Models
Consider the AR(1) model: For ,let and for ,let . It is easy to show that both and are stationary and satisfy Eq. (3). That is, both are the stationary solution of Eq. (3). This gives rise to a question: which one of both is preferable? Obviously, depends on future values of unobservable , and so it is unnatural. Hence we take and abandon . In other words, we require that the coefficient in Eq. (3) is less 1 in absolute value. At this point, the model is said to be causal and its causal expression is . In general, the definition of causality is given below. Definition 3 (1) A time series is causal if there exist coefficients such that where . At this point, we say that the time series has an representation.- We say that a model is causal if the time series generated by it is causal.
- A causal time series is surely a stationary one. So an model that satisfies the causal condition is naturally stationary. But a stationary model is not necessarily causal.
- If the time series generated by Eq. (1) is not from the remote past, namely,
- According to the relationship between the roots and the coefficients of the degree 2 polynomial , it may be proved that both of the roots of the polynomial exceed 1 in modulus if and only if
- It may be shown that for an model defined by Eq. (1), the coefficients in Definition 3 satisfy and
Autocorrelation: the past influences the present
The autoregressive model describes a relationship between the present of a variable and its past. Therefore, it is suitable for variables in which the past and present values are correlated. As an intuitive example, consider the waiting line at the doctor. Imagine that the doctor has a plan in which each patient has 20 minutes with him. If each patient takes exactly 20 minutes, this works well. But what if a patient takes a little longer? An autocorrelation could be present if the duration of one query has an impact on the duration of the next query. So if the doctor needs to speed up an appointment because the previous appointment took too long, look at a correlation between the past and the present. Past values influence future values.Positive and negative autocorrelation
Like “regular” correlation, autocorrelation can be positive or negative. Positive autocorrelation means that a high value now is likely to give a high value in the next period. This can be observed, for example, in stock trading: as soon as a lot of people want to buy a stock, its price goes up. This positive trend makes people want to buy this stock even more as it has positive returns. The more people buy the stock, the higher it goes and the more people will want to buy it. A positive correlation also works in downtrends. If today’s stock value is low, tomorrow’s value is likely to be even lower as people start selling. When many people sell, the value falls, and even more people will want to sell. This is also a case of positive autocorrelation since the past and the present go in the same direction. If the past is low, the present is low; and if the past is high, the present is high. There is negative autocorrelation if two trends are opposite. This is the case in the example of the duration of the doctor’s visit. If one query takes longer, the next one will be shorter. If one visit takes less time, the doctor may take a little longer for the next one.Stationarity and the ADF test
The problem of having a trend in our data is general in univariate time series modeling. The stationarity of a time series means that a time series does not have a (long-term) trend: it is stable around the same average. Otherwise, a time series is said to be non-stationary. In theory, AR models can have a trend coefficient in the model, but since stationarity is an important concept in general time series theory, it’s best to learn to deal with it right away. Many models can only work on stationary time series. A time series that is growing or falling strongly over time is obvious to spot. But sometimes it’s hard to tell if a time series is stationary. This is where the Augmented Dickey Fuller (ADF) test comes in handy.Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
Read Data
The input to StatsForecast is always a data frame in long format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
ds is in an object format, we need
to convert to a date format
Explore data with the plot method
Plot some series using the plot method from the StatsForecast class. This method prints 8 random series from the dataset and is useful for basic EDA.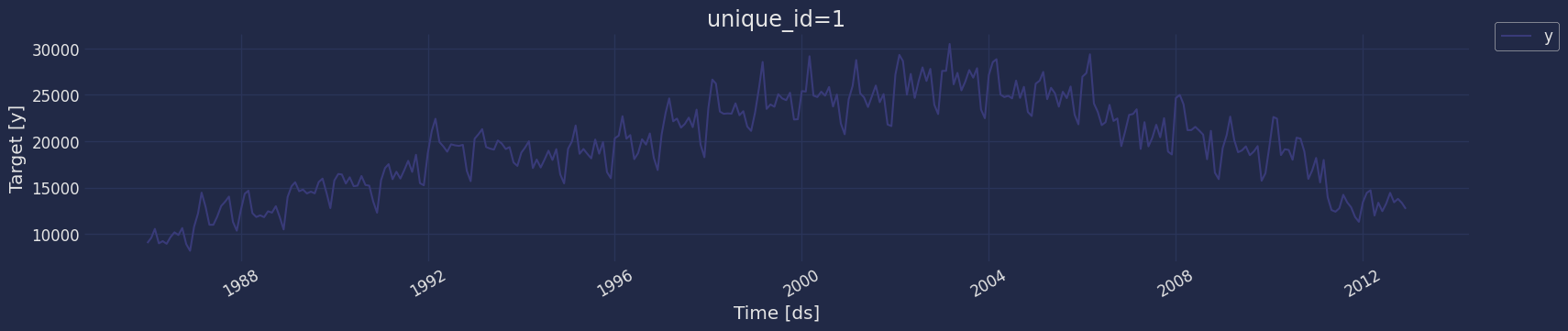
The Augmented Dickey-Fuller Test
An Augmented Dickey-Fuller (ADF) test is a type of statistical test that determines whether a unit root is present in time series data. Unit roots can cause unpredictable results in time series analysis. A null hypothesis is formed in the unit root test to determine how strongly time series data is affected by a trend. By accepting the null hypothesis, we accept the evidence that the time series data is not stationary. By rejecting the null hypothesis or accepting the alternative hypothesis, we accept the evidence that the time series data is generated by a stationary process. This process is also known as stationary trend. The values of the ADF test statistic are negative. Lower ADF values indicate a stronger rejection of the null hypothesis. Augmented Dickey-Fuller Test is a common statistical test used to test whether a given time series is stationary or not. We can achieve this by defining the null and alternate hypothesis. Null Hypothesis: Time Series is non-stationary. It gives a time-dependent trend. Alternate Hypothesis: Time Series is stationary. In another term, the series doesn’t depend on time. ADF or t Statistic < critical values: Reject the null hypothesis, time series is stationary. ADF or t Statistic > critical values: Failed to reject the null hypothesis, time series is non-stationary. Let’s check if our series that we are analyzing is a stationary series. Let’s create a function to check, using theDickey Fuller test
Augmented_Dickey_Fuller
test gives us a p-value of 0.488664, which tells us that the null
hypothesis cannot be rejected, and on the other hand the data of our
series are not stationary.
We need to differentiate our time series, in order to convert the data
to stationary.
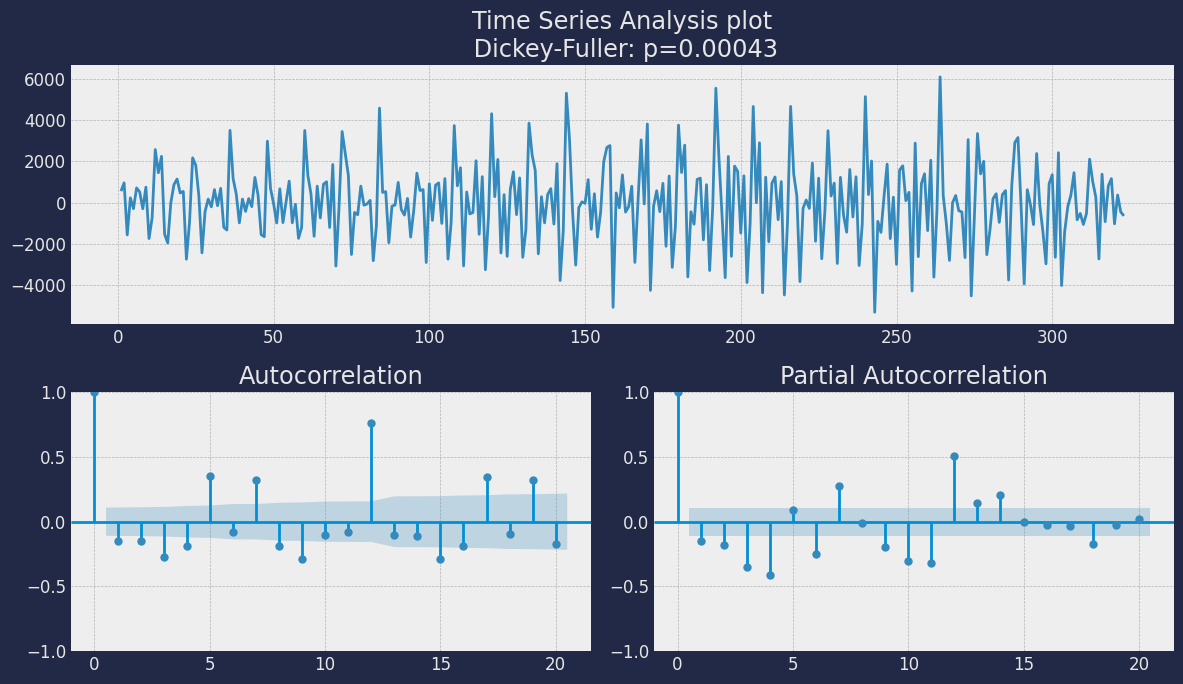
How many lags should we include?
Now, the big question in time series analysis is always how many lags to include. This is called the order of the time series. The notation is AR(1) for order 1 and AR(p) for order p. The order is up to you. Theoretically speaking, you can base your order on the PACF chart. Theory tells you to take the number of lags before you get an autocorrelation of 0. All other lags should be 0. In theory, you often see great charts where the first peak is very high and the rest equal zero. In those cases, the choice is easy: you are working with a very “pure” example of AR(1). Another common case is when your autocorrelation starts high and slowly decreases to zero. In this case, you should use all delays where the PACF is not yet zero. However, in practice, it is not always that simple. Remember the famous saying “all models are wrong, but some are useful”. It is very rare to find cases that fit an AR model perfectly. In general, the autoregression process can help explain part of the variation of a variable, but not all. In practice, you will try to select the number of lags that gives your model the best predictive performance. The best predictive performance is often not defined by looking at autocorrelation plots: those plots give you a theoretical estimate. However, predictive performance is best defined by model evaluation and benchmarking, using the techniques you have seen in Module 2. Later in this module, we will see how to use model evaluation to choose a performance order for the AR model. But before we get into that, it’s time to dig into the exact definition of the AR model.Split the data into training and testing
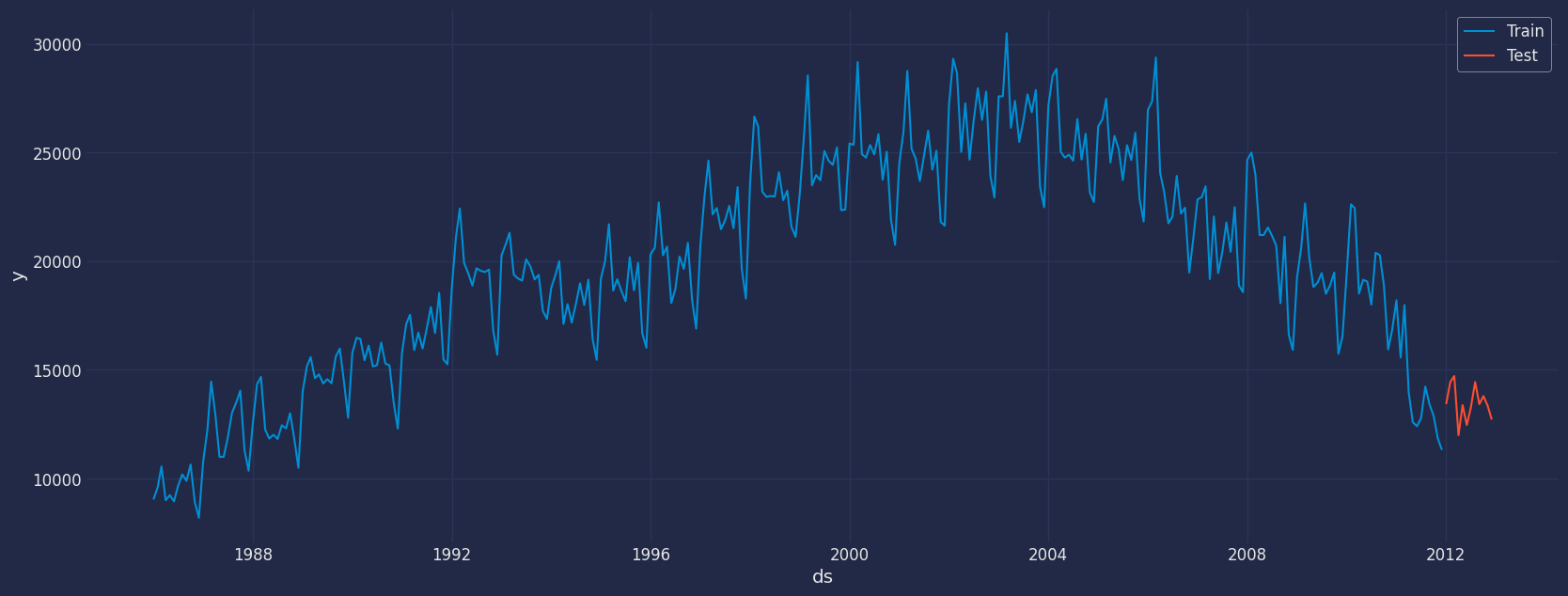
Let’s divide our data into sets 1. Data to train ourAutoRegressive
model 2. Data to test our model
For the test data we will use the last 12 months to test and evaluate
the performance of our model.
Implementation of AutoRegressive with StatsForecast
Load libraries
Instantiating Model
Import and instantiate the models. Setting the argument is sometimes tricky. This article on Seasonal periods by the master, Rob Hyndmann, can be useful.season_length. Method 1: We use the lags parameter in an integer format, that is, we put the lags we want to evaluate in the model.-
freq:a string indicating the frequency of the data. (See pandas’s available frequencies.) -
n_jobs:n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model:a model to be used if a model fails.
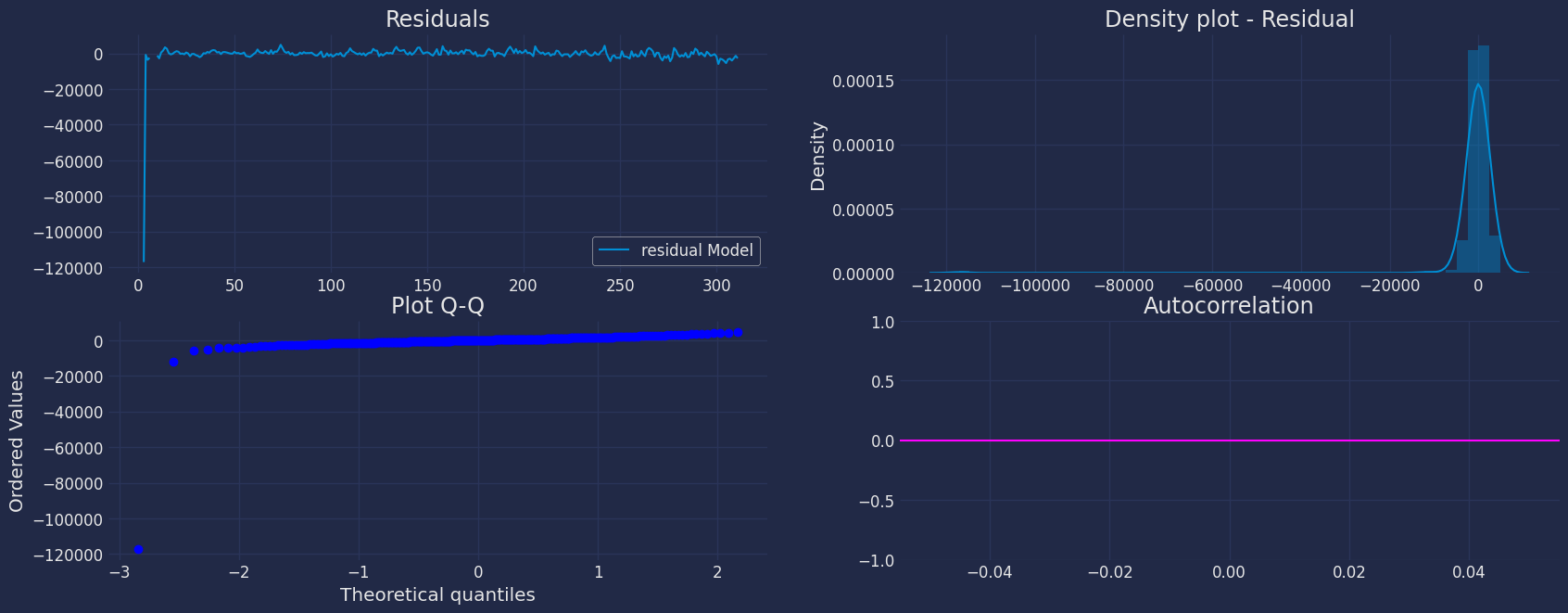
Fit Model
.get() function to extract the element and then we are going to save
it in a pd.DataFrame().
Forecast Method
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the .forecast doest not store the fitted
values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[90]means that the model expects the real value to be inside that interval 90% of the times.
ARIMA and Theta)
Adding 95% confidence interval with the forecast method

Predict method with confidence interval
To generate forecasts use the predict method. The predict method takes two arguments: forecasts the nexth (for
horizon) and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[95]means that the model expects the real value to be inside that interval 95% of the times.

Cross-validation
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:
Perform time series cross-validation
Cross-validation of time series models is considered a best practice but most implementations are very slow. The statsforecast library implements cross-validation as a distributed operation, making the process less time-consuming to perform. If you have big datasets you can also perform Cross Validation in a distributed cluster using Ray, Dask or Spark. In this case, we want to evaluate the performance of each model for the last 5 months(n_windows=5), forecasting every second months
(step_size=12). Depending on your computer, this step should take
around 1 min.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df:training data frame -
h (int):represents h steps into the future that are being forecasted. In this case, 12 months ahead. -
step_size (int):step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int):number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_id:series identifierds:datestamp or temporal indexcutoff:the last datestamp or temporal index for the n_windows.y:true value"model":columns with the model’s name and fitted value.
We’ll now plot the forecast for each cutoff period. To make the plots
clearer, we’ll rename the actual values in each period.





Model Evaluation
Now we are going to evaluate our model with the results of the predictions, we will use different types of metrics MAE, MAPE, MASE, RMSE, SMAPE to evaluate the accuracy.References
- Changquan Huang • Alla Petukhina. Springer series (2022). Applied Time Series Analysis and Forecasting with Python.
- Jose A. Fiorucci, Tiago R. Pellegrini, Francisco Louzada, Fotios Petropoulos, Anne B. Koehler (2016). “Models for optimising the theta method and their relationship to state space models”. International Journal of Forecasting.
- Nixtla AutoRegressive API
- Pandas available frequencies.
- Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting Principles and Practice (3rd ed)”
- Seasonal periods- Rob J Hyndman.