

Step-by-step guide on using theDuring this walkthrough, we will become familiar with the mainHolt ModelwithStatsforecast.
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation in other.
The text in this article is largely taken from: 1. Changquan Huang •
Alla Petukhina. Springer series (2022). Applied Time Series Analysis and
Forecasting with
Python. 2.
Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic
Adaptive Model (ADAM) 3. James D.
Hamilton. Time Series Analysis Princeton University Press, Princeton,
New Jersey, 1st Edition,
1994.
4. Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting
Principles and Practice (3rd ed)”.
Table of Contents
- Introduction
- Holt Model
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of Holt with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
The Holts model, also known as the double exponential smoothing method, is a forecasting technique widely used in time series analysis. It was developed by Charles Holt in 1957 as an improvement on Brown’s simple exponential smoothing method. The Holts model is used to predict future values of a time series that exhibits a trend. The model uses two smoothing parameters, one for estimating the trend and the other for estimating the level or base level of the time series. These parameters are called and , respectively. The Holts model is an extension of Brown’s simple exponential smoothing method, which uses only one smoothing parameter to estimate the trend and base level of the time series. The Holts model improves the accuracy of the forecasts by adding a second smoothing parameter for the trend. One of the main advantages of the Holts model is that it is easy to implement and does not require a large amount of historical data to generate accurate predictions. Furthermore, the model is highly adaptable and can be customized to fit a wide variety of time series. However, Holts’ model has some limitations. For example, the model assumes that the time series is stationary and that the trend is linear. If the time series is not stationary or has a non-linear trend, the Holts model may not be the most appropriate. In general, the Holts model is a useful and widely used technique in time series analysis, especially when the series is expected to exhibit a linear trend.Holt Method
Simple exponential smoothing does not function well when the data has
trends. In those cases, we can use double exponential smoothing. This
is a more reliable method for handling data that consumes trends without
seasonality than compared to other methods. This method adds a time
trend equation in the formulation. Two different weights, or smoothing
parameters, are used to update these two components at a time.
Holt’s exponential smoothing is also sometimes called double
exponential smoothing. The main idea here is to use SES and advance it
to capture the trend component.
Holt (1957) extended simple exponential smoothing to allow the
forecasting of data with a trend. This method involves a forecast
equation and two smoothing equations (one for the level and one for
the trend):
Assume that a series has the following:
- Level
- Trend
- No seasonality
- Noise
Innovations state space models for exponential smoothing
The exponential smoothing methods presented in Table 7.6 are algorithms which generate point forecasts. The statistical models in this tutorial generate the same point forecasts, but can also generate prediction (or forecast) intervals. A statistical model is a stochastic (or random) data generating process that can produce an entire forecast distribution. Each model consists of a measurement equation that describes the observed data, and some state equations that describe how the unobserved components or states (level, trend, seasonal) change over time. Hence, these are referred to as state space models. For each method there exist two models: one with additive errors and one with multiplicative errors. The point forecasts produced by the models are identical if they use the same smoothing parameter values. They will, however, generate different prediction intervals. To distinguish between a model with additive errors and one with multiplicative errors. We label each state space model as ETS( .,.,.) for (Error, Trend, Seasonal). This label can also be thought of as ExponenTial Smoothing. Using the same notation as in Table 7.5, the possibilities for each component are: , and For our case, the linear Holt model with a trend, we are going to see two cases, both for the additive and the multiplicativeETS(A,A,N): Holt’s linear method with additive errors
For this model, we assume that the one-step-ahead training errors are given by . Substituting this into the error correction equations for Holt’s linear method we obtain where, for simplicity, we have setETS(M,A,N): Holt’s linear method with multiplicative errors
Specifying one-step-ahead training errors as relative errors such that and following an approach similar to that used above, the innovations state space model underlying Holt’s linear method with multiplicative errors is specified as where again and .A taxonomy of exponential smoothing methods
Building on the idea of time series components, we can move to the ETS taxonomy. ETS stands for “Error-Trend-Seasonality” and defines how specifically the components interact with each other. Based on the type of error, trend and seasonality, Pegels (1969) proposed a taxonomy, which was then developed further by Hyndman et al. (2002) and refined by Hyndman et al. (2008). According to this taxonomy, error, trend and seasonality can be:- Error: “Additive” (A), or “Multiplicative” (M);
- Trend: “None” (N), or “Additive” (A), or “Additive damped” (Ad), or “Multiplicative” (M), or “Multiplicative damped” (Md);
- Seasonality: “None” (N), or “Additive” (A), or “Multiplicative” (M).
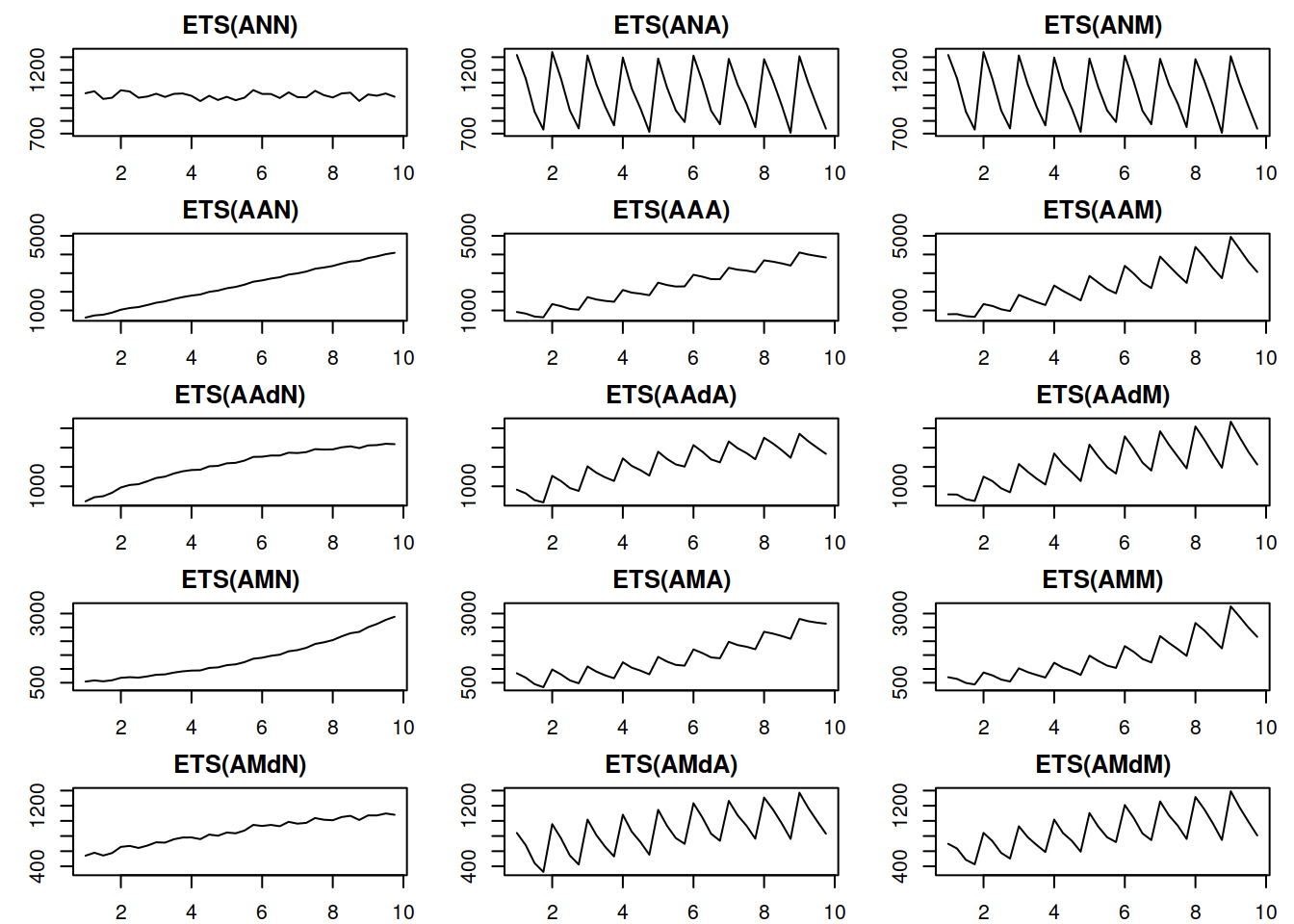 Figure 4.1: Time series corresponding to the additive error ETS models
Things to note from the plots in Figure.1:
Figure 4.1: Time series corresponding to the additive error ETS models
Things to note from the plots in Figure.1:
- When seasonality is multiplicative, its amplitude increases with the increase of the level of the data, while with additive seasonality, the amplitude is constant. Compare, for example, ETS(A,A,A) with ETS(A,A,M): for the former, the distance between the highest and the lowest points in the first year is roughly the same as in the last year. In the case of ETS(A,A,M) the distance increases with the increase in the level of series;
- When the trend is multiplicative, data exhibits exponential growth/decay;
- The damped trend slows down both additive and multiplicative trends;
- It is practically impossible to distinguish additive and multiplicative seasonality if the level of series does not change because the amplitude of seasonality will be constant in both cases (compare ETS(A,N,A) and ETS(A,N,M)).
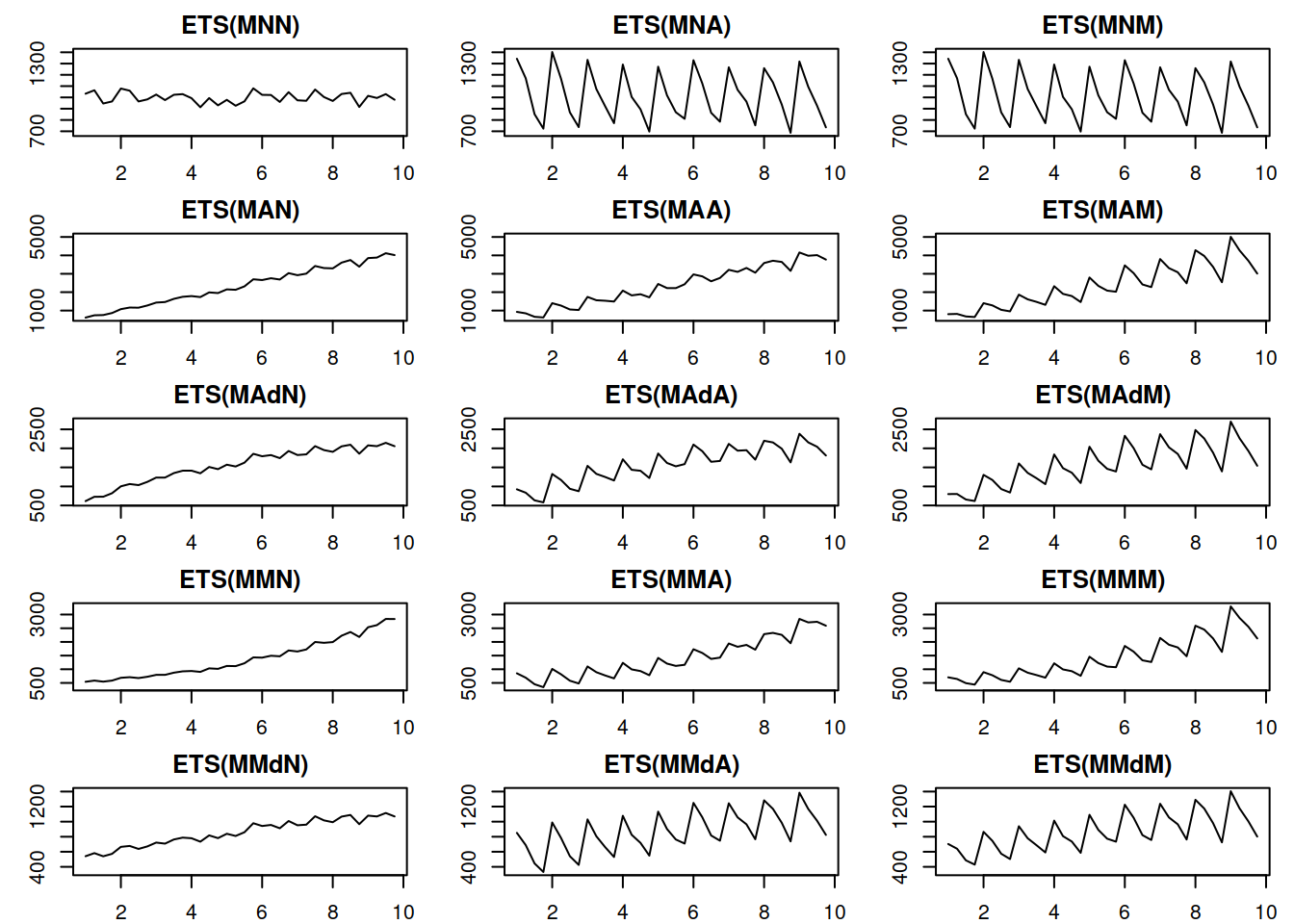 Figure 2: Time series corresponding to the multiplicative error ETS
models
The graphs in Figure 2 show approximately the same idea as the additive
case, the main difference is that the error variance increases with
increasing data level; this becomes clearer in ETS(M,A,N) and ETS(M,M,N)
data. This property is called heteroskedasticity in statistics, and
Hyndman et al. (2008) argue that the main benefit of multiplicative
error models is to capture this characteristic.
Figure 2: Time series corresponding to the multiplicative error ETS
models
The graphs in Figure 2 show approximately the same idea as the additive
case, the main difference is that the error variance increases with
increasing data level; this becomes clearer in ETS(M,A,N) and ETS(M,M,N)
data. This property is called heteroskedasticity in statistics, and
Hyndman et al. (2008) argue that the main benefit of multiplicative
error models is to capture this characteristic.
Mathematical models in the ETS taxonomy
I hope that it becomes more apparent to the reader how the ETS framework is built upon the idea of time series decomposition. By introducing different components, defining their types, and adding the equations for their update, we can construct models that would work better in capturing the key features of the time series. But we should also consider the potential change in components over time. The “transition” or “state” equations are supposed to reflect this change: they explain how the level, trend or seasonal components evolve. As discussed in Section 2.2, given different types of components and their interactions, we end up with 30 models in the taxonomy. Tables 1 and 2 summarise mathematically all 30 ETS models shown graphically on Figures 1 and 2, presenting formulae for measurement and transition equations. Table 1: Additive error ETS models
Table 2: Multiplicative error ETS models
From a statistical point of view, formulae in Tables 1 and 2 correspond
to the “true models”, they explain the models underlying potential data,
but when it comes to their construction and estimation, the
is substituted by the estimated (which is calculated differently
depending on the error type), and time series components and smoothing
parameters are also replaced by their estimates (e.g.
instead of ). However, if the values of these models’ parameters
were known, it would be possible to produce point forecasts and
conditional h steps ahead expectations from these models.
Properties Holt’s linear trend method
Holt’s linear trend method is a time series forecasting technique that uses exponential smoothing to estimate the level and trend components of a time series. The method has several properties, including:- Additive model: Holt’s linear trend method assumes that the time series can be decomposed into an additive model, where the observed values are the sum of the level, trend, and error components.
- Smoothing parameters: The method uses two smoothing parameters, α and β, to estimate the level and trend components of the time series. These parameters control the amount of smoothing applied to the level and trend components, respectively.
- Linear trend: Holt’s linear trend method assumes that the trend component of the time series follows a straight line. This means that the method is suitable for time series data that exhibit a constant linear trend over time.
- Forecasting: The method uses the estimated level and trend components to forecast future values of the time series. The forecast for the next period is given by the sum of the level and trend components.
- Optimization: The smoothing parameters α and β are estimated through a process of optimization that minimizes the sum of squared errors between the predicted and observed values. This involves iterating over different values of the smoothing parameters until the optimal values are found.
- Seasonality: Holt’s linear trend method can be extended to incorporate seasonality components. This involves adding a seasonal component to the model, which captures any systematic variations in the time series that occur on a regular basis.
Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
Read Data
The input to StatsForecast is always a data frame in long format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
(ds) is in an object format, we need
to convert to a date format
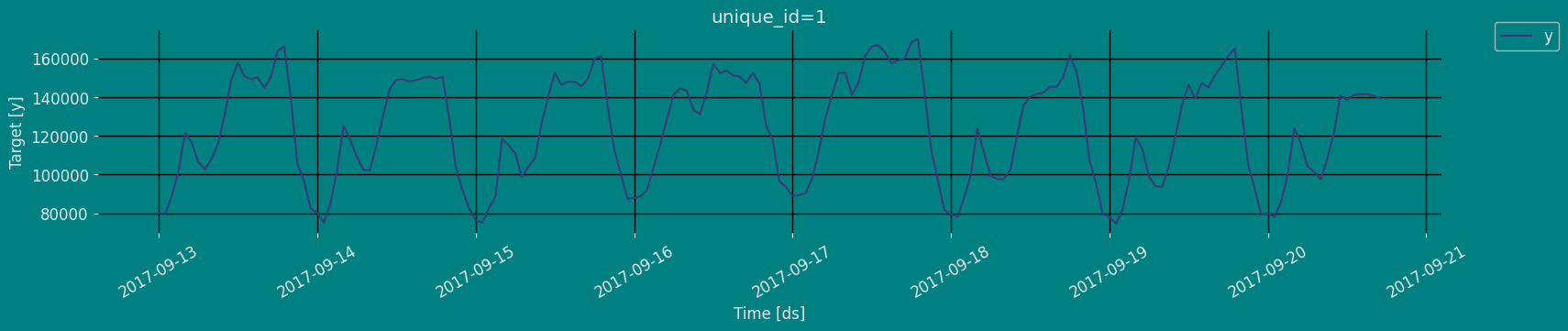
Explore Data with the plot method
Plot some series using the plot method from the StatsForecast class. This method prints a random series from the dataset and is useful for basic EDA.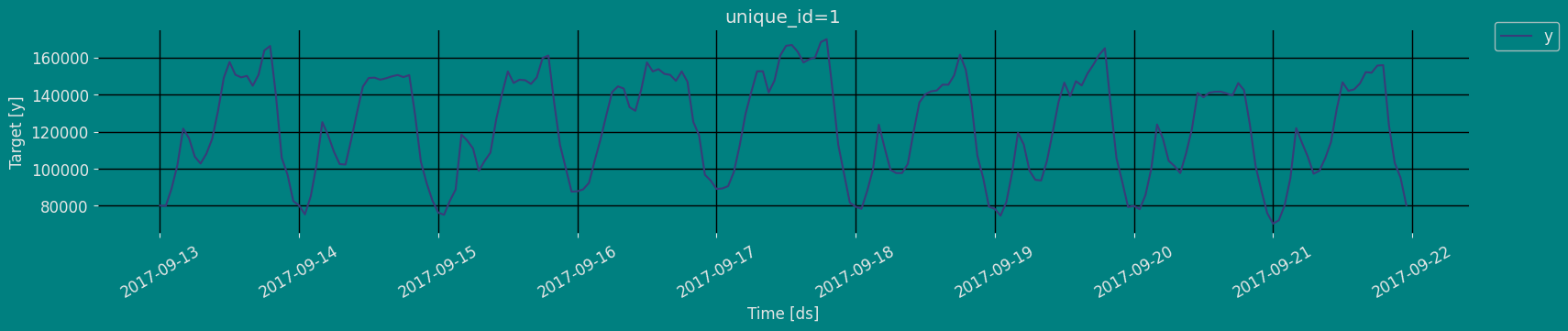
The Augmented Dickey-Fuller Test
An Augmented Dickey-Fuller (ADF) test is a type of statistical test that determines whether a unit root is present in time series data. Unit roots can cause unpredictable results in time series analysis. A null hypothesis is formed in the unit root test to determine how strongly time series data is affected by a trend. By accepting the null hypothesis, we accept the evidence that the time series data is not stationary. By rejecting the null hypothesis or accepting the alternative hypothesis, we accept the evidence that the time series data is generated by a stationary process. This process is also known as stationary trend. The values of the ADF test statistic are negative. Lower ADF values indicate a stronger rejection of the null hypothesis. Augmented Dickey-Fuller Test is a common statistical test used to test whether a given time series is stationary or not. We can achieve this by defining the null and alternate hypothesis.- Null Hypothesis: Time Series is non-stationary. It gives a time-dependent trend.
- Alternate Hypothesis: Time Series is stationary. In another term, the series doesn’t depend on time.
- ADF or t Statistic < critical values: Reject the null hypothesis, time series is stationary.
- ADF or t Statistic > critical values: Failed to reject the null hypothesis, time series is non-stationary.
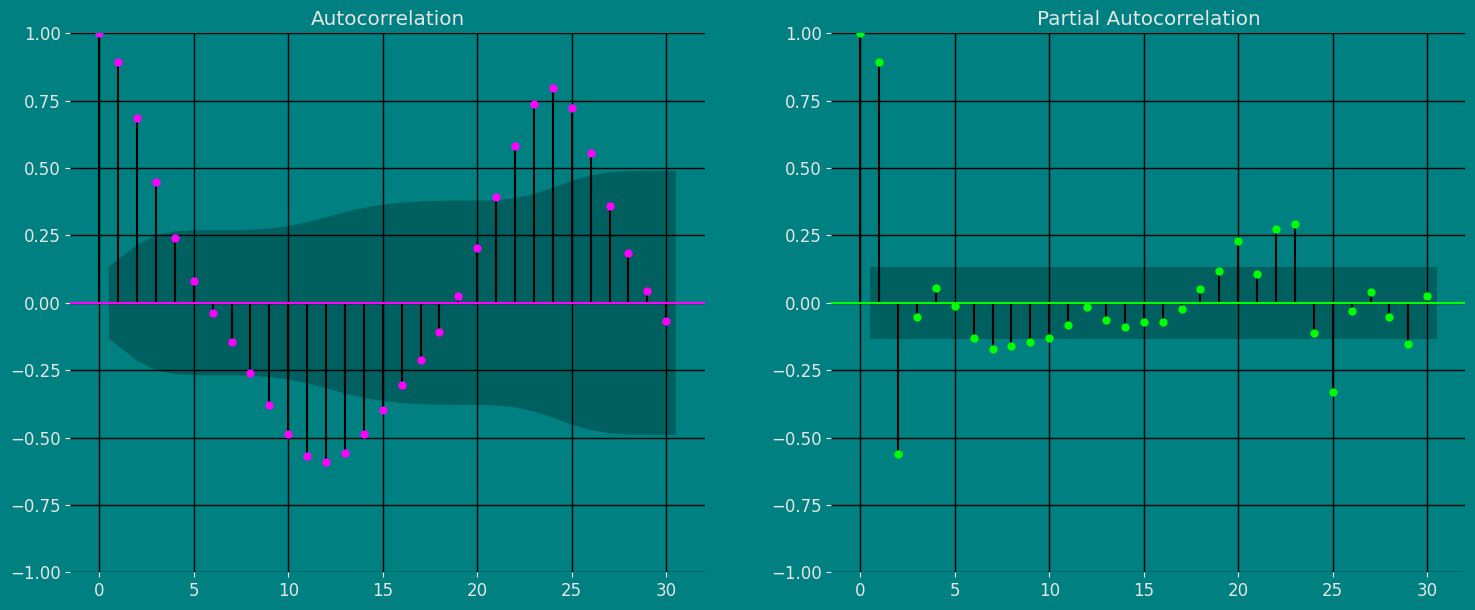
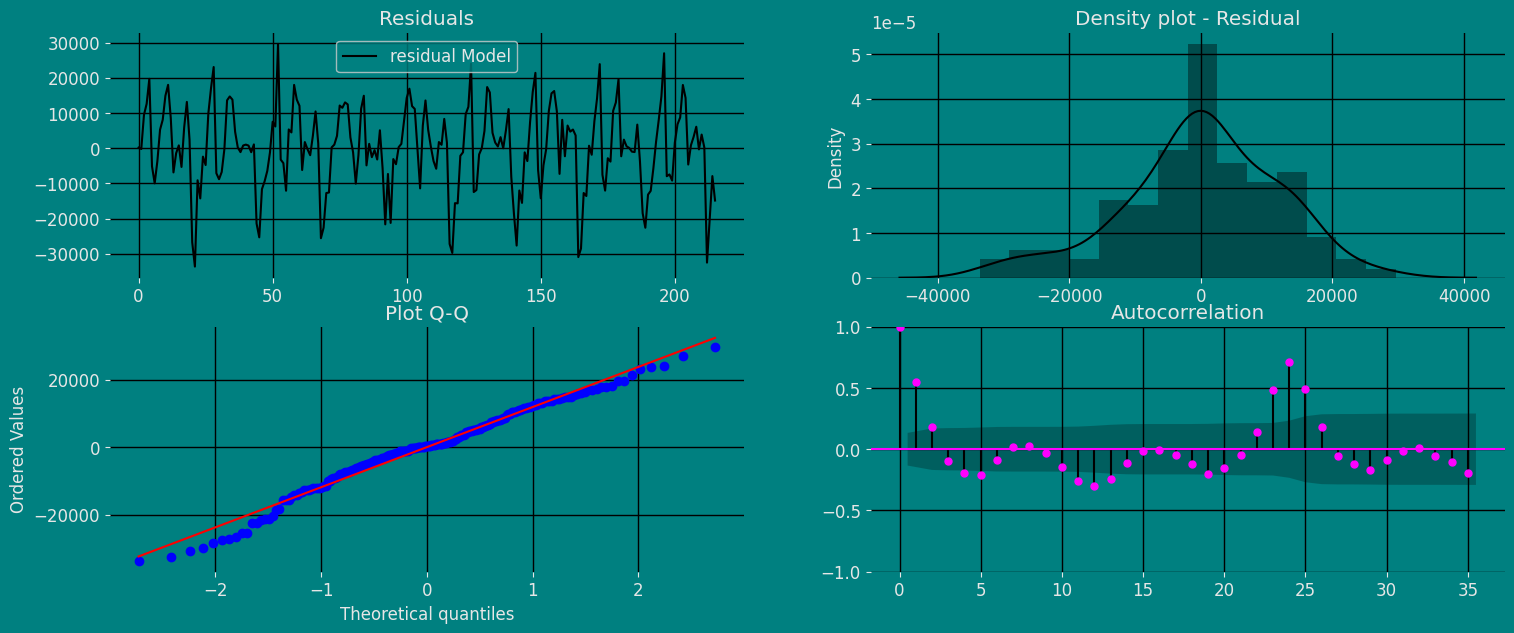
Autocorrelation plots
Autocorrelation Function Definition 1. Let be a time series sample of size n from . 1. is called the sample mean of . 2. is known as the sample autocovariance function of . 3. is said to be the sample autocorrelation function of . Note the following remarks about this definition:- Like most literature, this guide uses ACF to denote the sample autocorrelation function as well as the autocorrelation function. What is denoted by ACF can easily be identified in context.
- Clearly c0 is the sample variance of . Besides, and for any integer .
- When we compute the ACF of any sample series with a fixed length , we cannot put too much confidence in the values of for large k’s, since fewer pairs of are available for calculating as is large. One rule of thumb is not to estimate for , and another is . In any case, it is always a good idea to be careful.
- We also compute the ACF of a nonstationary time series sample by Definition 1. In this case, however, the ACF or very slowly or hardly tapers off as increases.
- Plotting the ACF against lag is easy but very helpful in analyzing time series sample. Such an ACF plot is known as a correlogram.
- If is stationary with and for all ,thatis,itisa white noise series, then the sampling distribution of is asymptotically normal with the mean 0 and the variance of . Hence, there is about 95% chance that falls in the interval .
Decomposition of the time series
How to decompose a time series and why? In time series analysis to forecast new values, it is very important to know past data. More formally, we can say that it is very important to know the patterns that values follow over time. There can be many reasons that cause our forecast values to fall in the wrong direction. Basically, a time series consists of four components. The variation of those components causes the change in the pattern of the time series. These components are:- Level: This is the primary value that averages over time.
- Trend: The trend is the value that causes increasing or decreasing patterns in a time series.
- Seasonality: This is a cyclical event that occurs in a time series for a short time and causes short-term increasing or decreasing patterns in a time series.
- Residual/Noise: These are the random variations in the time series.
Additive time series
If the components of the time series are added to make the time series. Then the time series is called the additive time series. By visualization, we can say that the time series is additive if the increasing or decreasing pattern of the time series is similar throughout the series. The mathematical function of any additive time series can be represented by:Multiplicative time series
If the components of the time series are multiplicative together, then the time series is called a multiplicative time series. For visualization, if the time series is having exponential growth or decline with time, then the time series can be considered as the multiplicative time series. The mathematical function of the multiplicative time series can be represented as.Additive
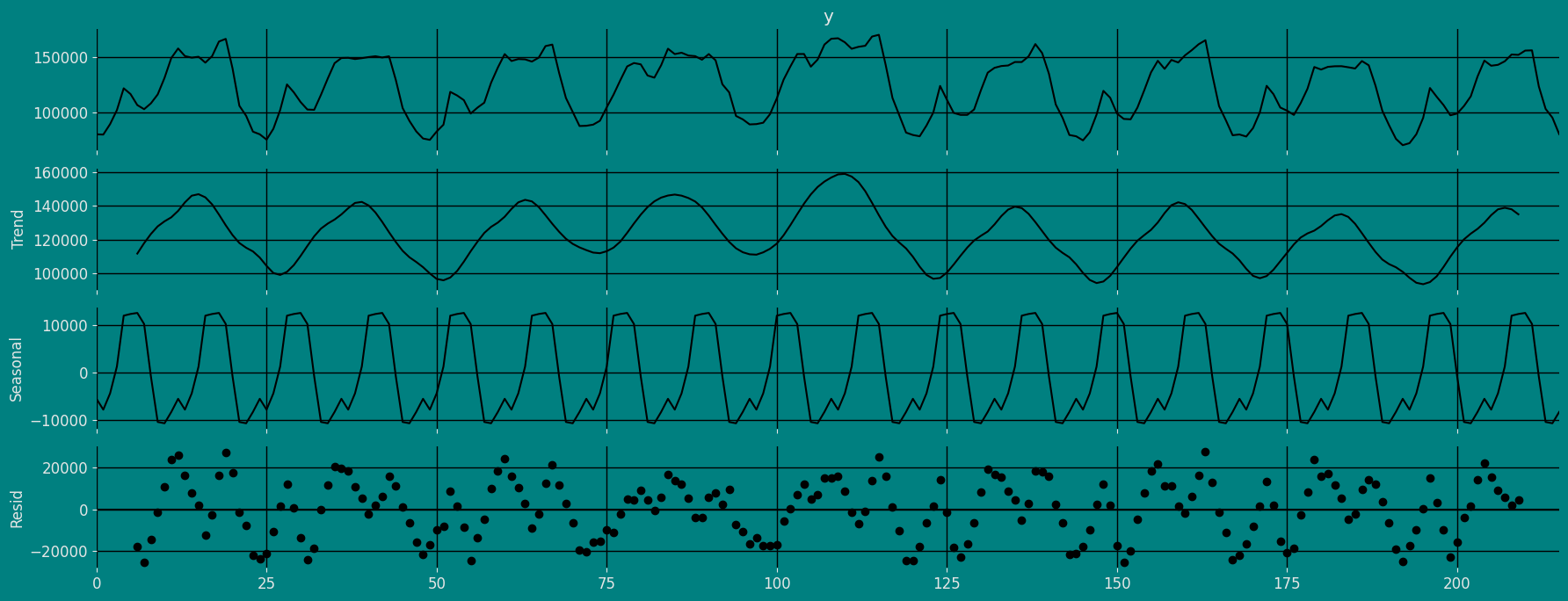
Multiplicative
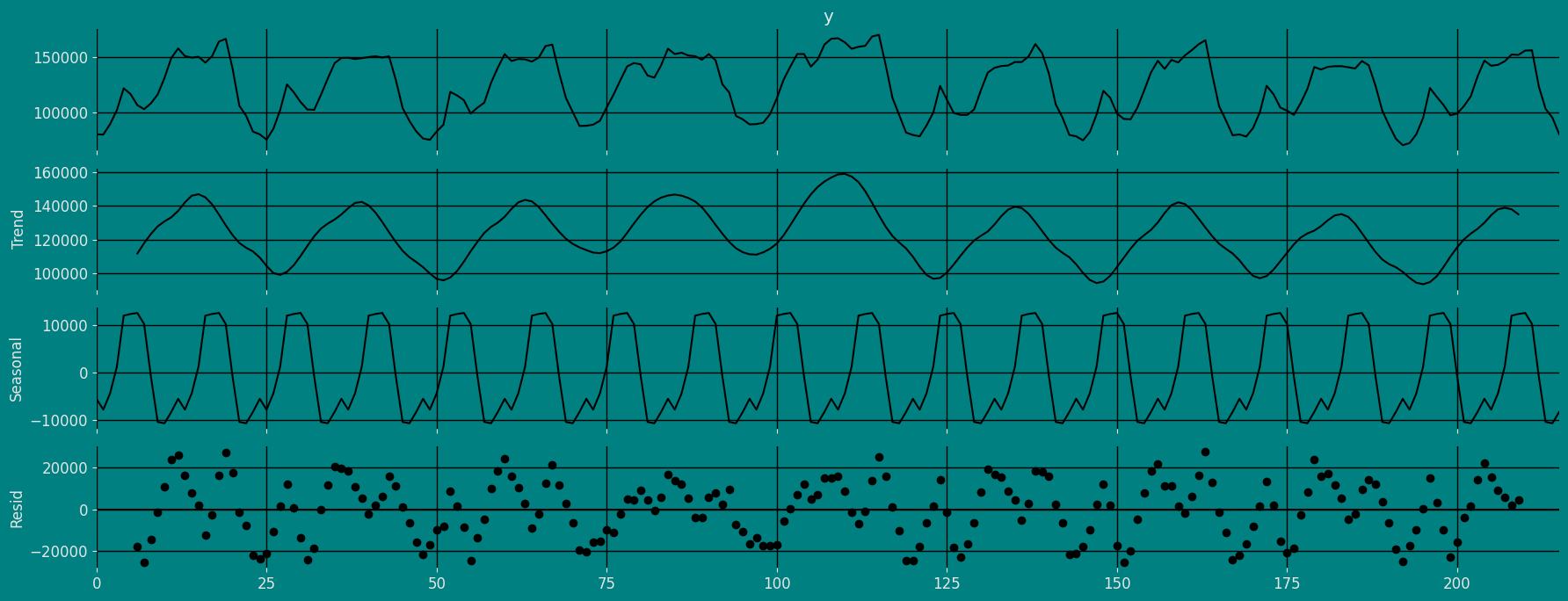
Split the data into training and testing
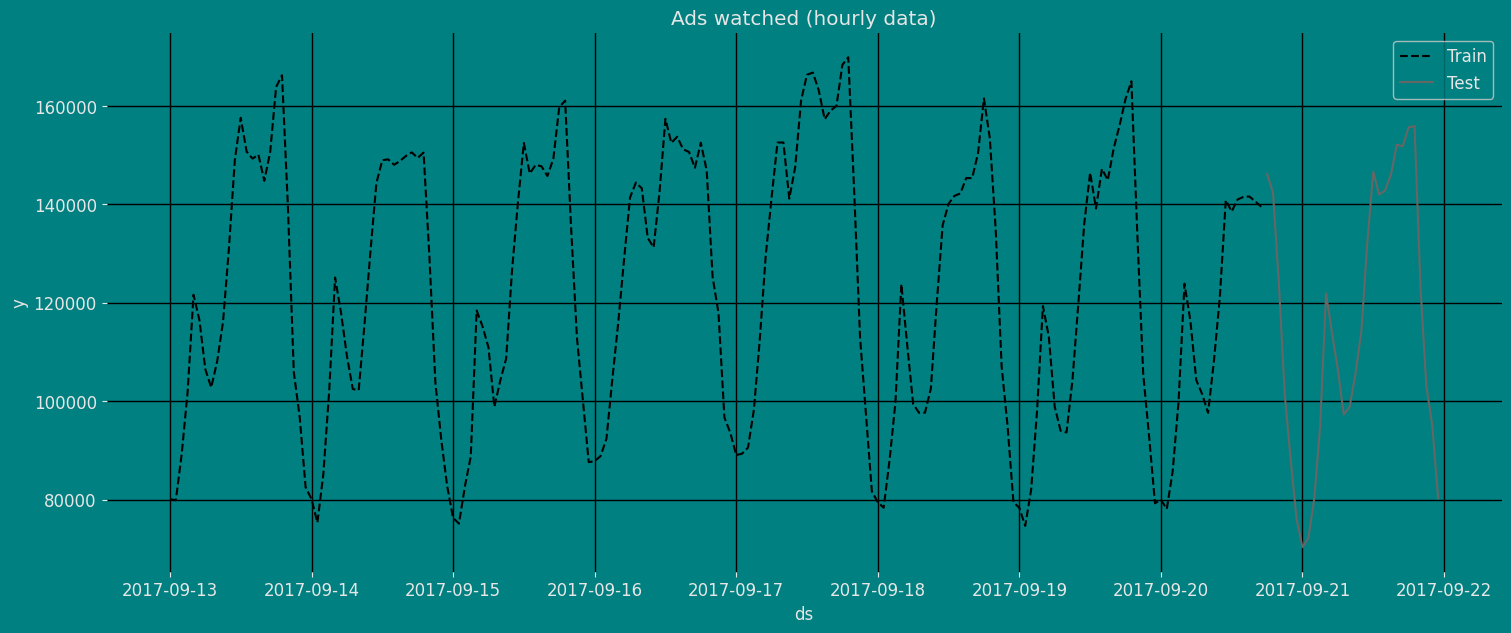
Let’s divide our data into sets 1. Data to train ourHolt Model. 2.
Data to test our model
For the test data we will use the last 30 hours to test and evaluate the
performance of our model.
Implementation of Holt Method with StatsForecast
Load libraries
Instantiate Model
Import and instantiate the models. Setting the argument is sometimes tricky. This article on Seasonal periods by the master, Rob Hyndmann, can be useful forseason_length.
-
freq:a string indicating the frequency of the data. (See pandas’ available frequencies.) -
n_jobs:n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model:a model to be used if a model fails.
Fit the Model
Holt Model. We can observe it with the
following instruction:
.get() function to extract the element and then we are going to save
it in a pd.DataFrame().
Forecast Method
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the .forecast doest not store the fitted
values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[90]means that the model expects the real value to be inside that interval 90% of the times.
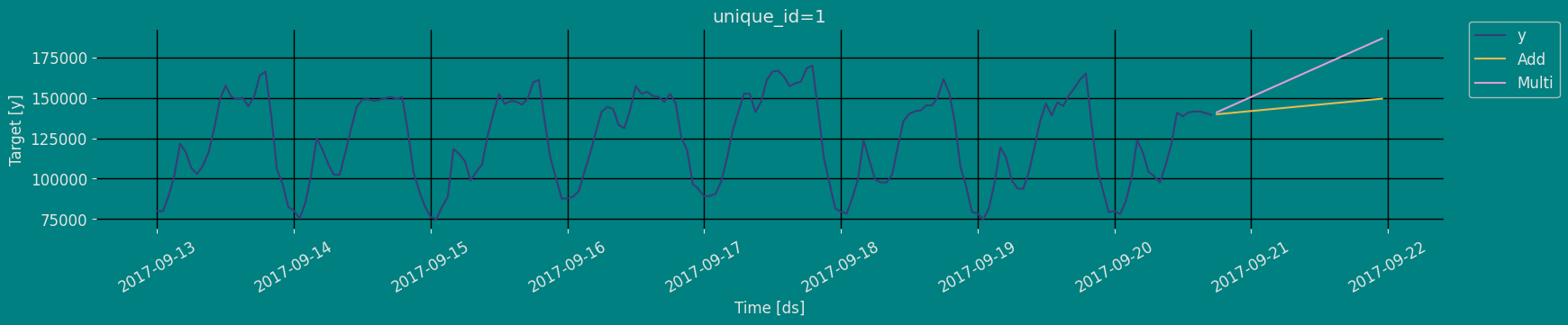
Predict method with confidence interval
To generate forecasts use the predict method. The predict method takes two arguments: forecasts the nexth (for
horizon) and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[95]means that the model expects the real value to be inside that interval 95% of the times.

Cross-validation
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:
Perform time series cross-validation
Cross-validation of time series models is considered a best practice but most implementations are very slow. The statsforecast library implements cross-validation as a distributed operation, making the process less time-consuming to perform. If you have big datasets you can also perform Cross Validation in a distributed cluster using Ray, Dask or Spark. In this case, we want to evaluate the performance of each model for the last 5 months(n_windows=), forecasting every second months
(step_size=12). Depending on your computer, this step should take
around 1 min.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df:training data frame -
h (int):represents h steps into the future that are being forecasted. In this case, 30 hours ahead. -
step_size (int):step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int):number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_id:series identifier.ds:datestamp or temporal indexcutoff:the last datestamp or temporal index for then_windows.y:true valuemodel:columns with the model’s name and fitted value.
Model Evaluation
Now we are going to evaluate our model with the results of the predictions, we will use different types of metrics MAE, MAPE, MASE, RMSE, SMAPE to evaluate the accuracy.References
- Changquan Huang • Alla Petukhina. Springer series (2022). Applied Time Series Analysis and Forecasting with Python.
- Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic Adaptive Model (ADAM)
- James D. Hamilton. Time Series Analysis Princeton University Press, Princeton, New Jersey, 1st Edition, 1994.
- Nixtla Holt API
- Pandas available frequencies.
- Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting Principles and Practice (3rd ed)”.
- Seasonal periods- Rob J Hyndman.