

In this notebook, we’ll implement models for intermittent or sparse dataIntermittent or sparse data has very few non-zero observations. This type of data is hard to forecast because the zero values increase the uncertainty about the underlying patterns in the data. Furthermore, once a non-zero observation occurs, there can be considerable variation in its size. Intermittent time series are common in many industries, including finance, retail, transportation, and energy. Given the ubiquity of this type of series, special methods have been developed to forecast them. The first was from Croston (1972), followed by several variants and by different aggregation frameworks. StatsForecast has implemented several models to forecast intermittent time series. By the end of this tutorial, you’ll have a good understanding of these models and how to use them. Outline:
- Install libraries
- Load and explore the data
- Train models for intermittent data
- Plot forecasts and compute accuracy
Tip You can use Colab to run this Notebook interactively
Tip For forecasting at scale, we recommend you check this notebook done on Databricks.
Install libraries
We assume that you have StatsForecast already installed. If not, check this guide for instructions on how to install StatsForecast Install the necessary packages usingpip install statsforecast
Load and explore the data
For this example, we’ll use a subset of the M5 Competition dataset. Each time series represents the unit sales of a particular product in a given Walmart store. At this level (product-store), most of the data is intermittent. We first need to import the data.plot_series function from
utilsforecast.plotting. This function has multiple parameters, and the
required ones to generate the plots in this notebook are explained
below.
df: Apandasdataframe with columns [unique_id,ds,y].forecasts_df: Apandasdataframe with columns [unique_id,ds] and models.plot_random: Plots the time series randomly.max_insample_length: The maximum number of train/insample observations to be plotted.engine: The library used to generate the plots. It can also bematplotlibfor static plots.
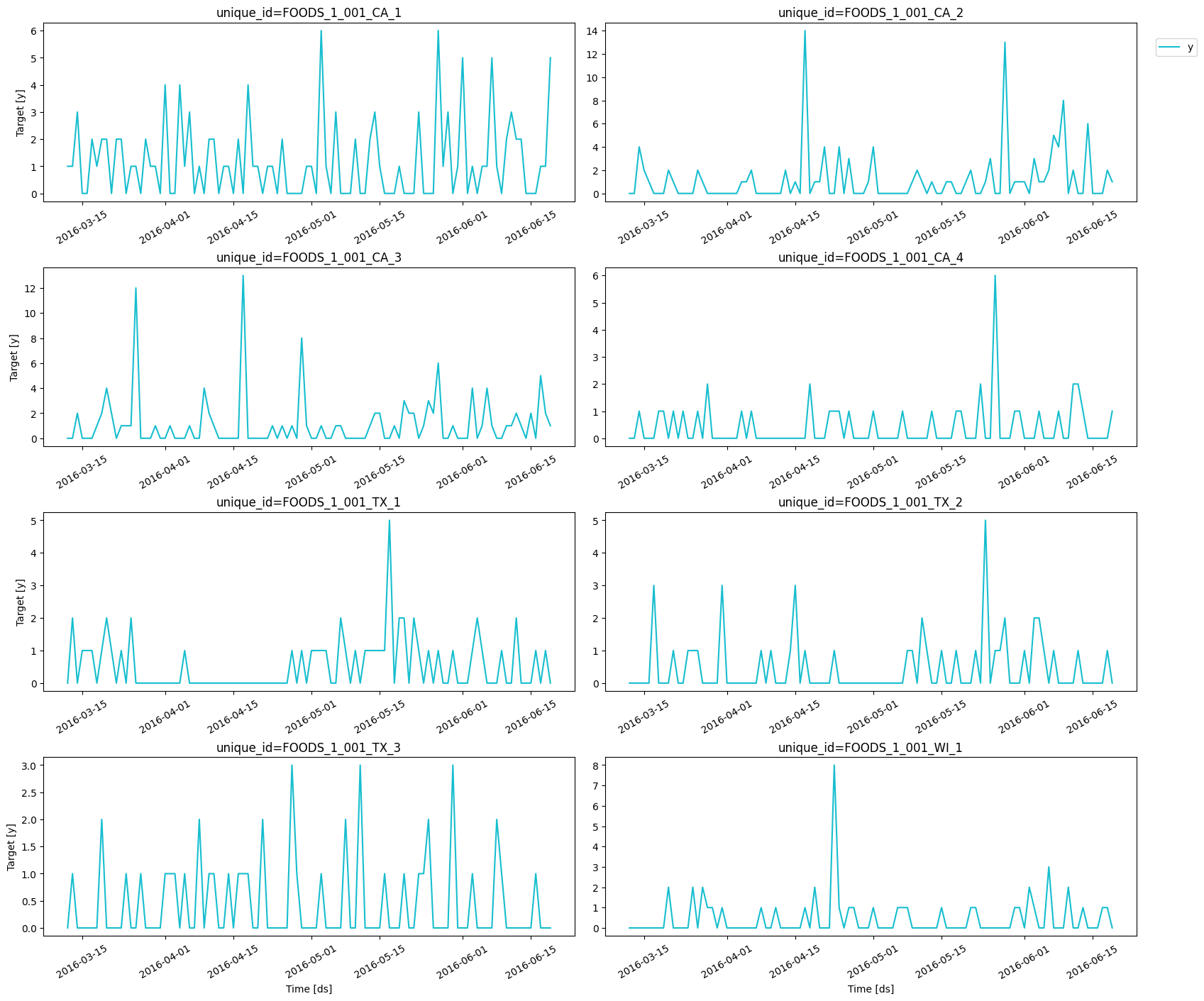
max_insample_length. From these plots, we
can confirm that the data is indeed intermittent since it has multiple
periods with zero sales. In fact, in all cases but one, the median value
is zero.
Train models for intermittent data
Before training any model, we need to separate the data in a train and a test set. The M5 Competition used the last 28 days as test set, so we’ll do the same.- Agregate-Dissagregate Intermittent Demand Approach (ADIDA)
- Croston Classic
- Intermittent Multiple Aggregation Prediction Algorithm (IMAPA)
- Teunter-Syntetos-Babai (TSB)
statsforecast.models and then we need to instantiate them.
models: The list of models defined in the previous step.freq: A string indicating the frequency of the data. See pandas’ available frequencies.n_jobs: An integer that indicates the number of jobs used in parallel processing. Use -1 to select all cores.
forecast method, which requires the forecasting horizon (in this case,
28 days) as argument.
The models for intermittent series that are currently available in
StatsForecast can only generate point-forecasts. If prediction intervals
are needed, then a probabilisitic model
should be used.
Finally, we’ll merge the forecast with the actual values.
Plot forecasts and compute accuracy
We can generate plots using theplot_series function described above.
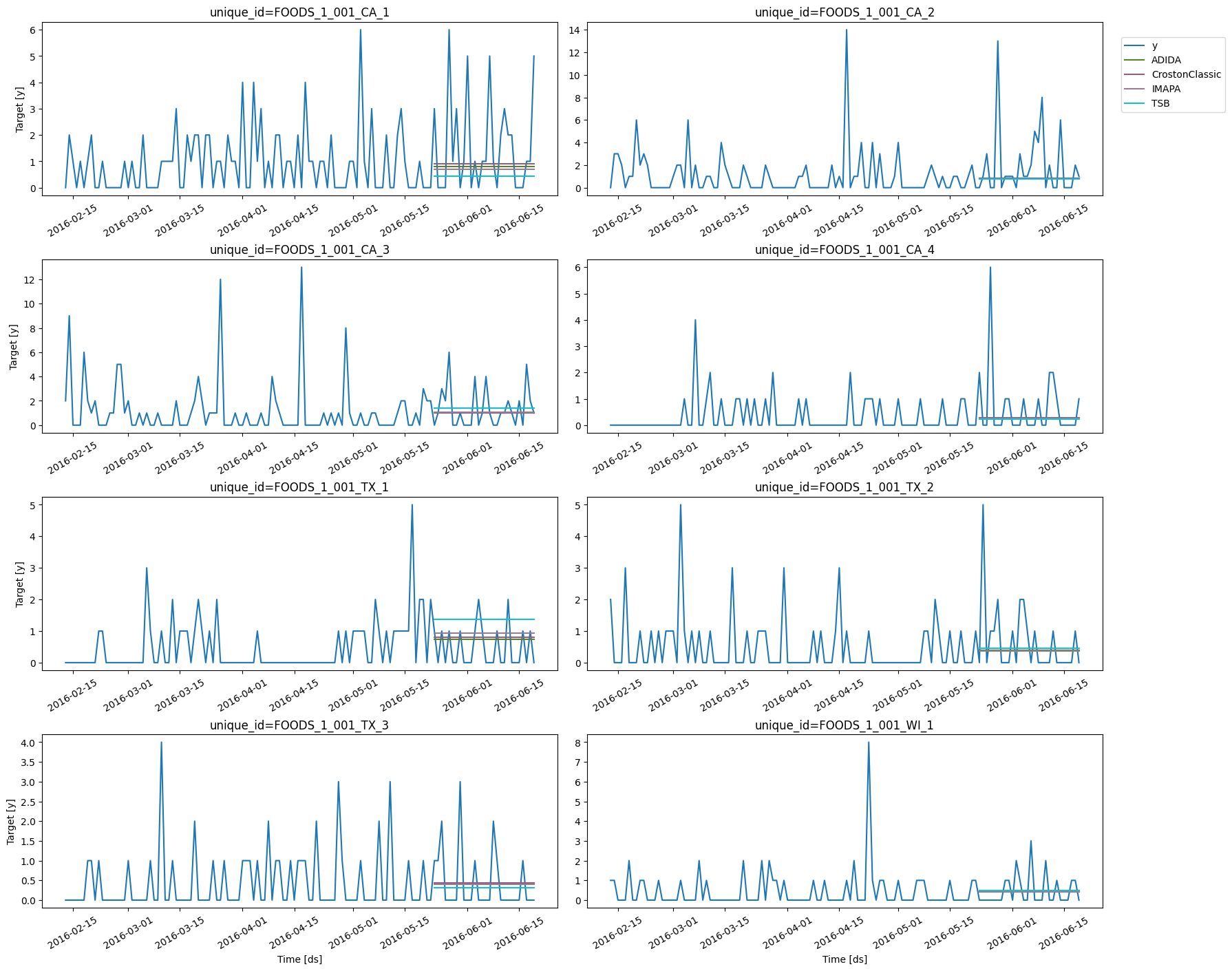
Hence, on average, the forecasts are one unit off.