

In this example we will show how to forecast data with multiple seasonalities using an MSTL.
Tip For this task, StatsForecast’s MSTL is 68% more accurate and 600% faster than Prophet and NeuralProphet. (Reproduce experiments here)Multiple seasonal data refers to time series that have more than one clear seasonality. Multiple seasonality is traditionally present in data that is sampled at a low frequency. For example, hourly electricity data exhibits daily and weekly seasonality. That means that there are clear patterns of electricity consumption for specific hours of the day like 6:00pm vs 3:00am or for specific days like Sunday vs Friday. Traditional statistical models are not able to model more than one seasonal length. In this example, we will show how to model the two seasonalities efficiently using Multiple Seasonal-Trend decompositions with LOESS (
MSTL).
For this example, we will use hourly electricity load data from
Pennsylvania, New Jersey, and Maryland (PJM). The original data can be
found
here.
(Click here for info on PJM)
First, we will load the data, then we will use the StatsForecast.fit
and StatsForecast.predict methods to predict the next 24 hours. We
will then decompose the different elements of the time series into
trends and its multiple seasonalities. At the end, you will use the
StatsForecast.forecast for production-ready forecasting.
Outline
- Install libraries
- Load and explore the data
- Fit a multiple-seasonality model
- Decompose the series in trend and seasonality
- Predict the next 24 hours
- Optional: Forecast in production
Tip You can use Colab to run this Notebook interactively
Install libraries
We assume you have StatsForecast already installed. Check this guide for instructions on how to install StatsForecast. Install the necessary packages usingpip install statsforecast
Load Data
The input to StatsForecast is always a data frame in long format with three columns:unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp or int) column should be either an integer indexing time or a datestamp ideally like YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast. We will rename the
StatsForecast can handle unsorted data, however, for plotting purposes,
it is convenient to sort the data frame.
Plot the series using the
plot method from the StatsForecast class.
This method prints up to 8 random series from the dataset and is useful
for basic EDA. In this case, it will print just one series given that we
have just one unique_id.
Note TheStatsForecast.plotmethod uses matplotlib as a default engine. You can change to plotly by settingengine="plotly".
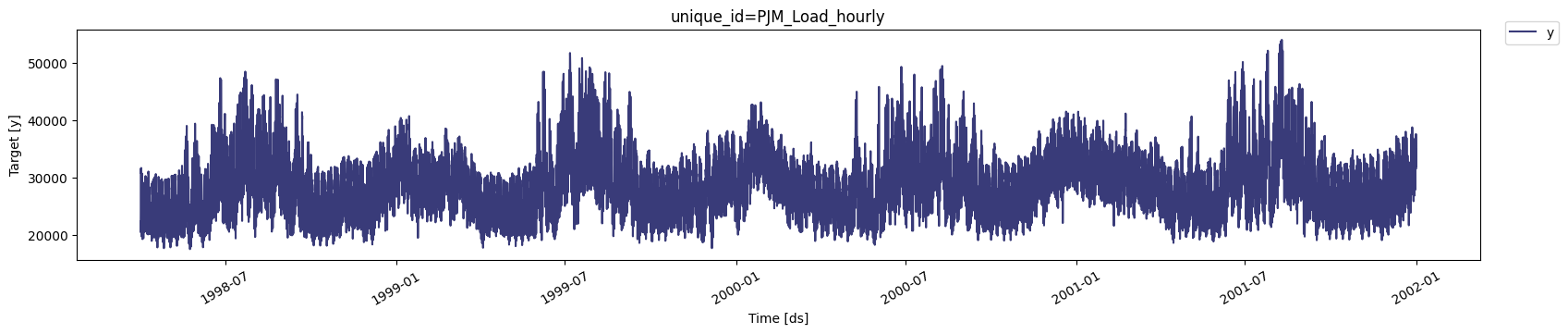
32,896 observations, so it is necessary to use very
computationally efficient methods.
Fit an MSTL model
The MSTL (Multiple Seasonal-Trend decompositions using LOESS) model, originally developed by Kasun Bandara, Rob J Hyndman and Christoph Bergmeir, decomposes the time series in multiple seasonalities using a Local Polynomial Regression (LOESS). Then it forecasts the trend using a non-seasonal model and each seasonality using a SeasonalNaive model. You can choose the non-seasonal model you want to use to forecast the trend component of the MSTL model. In this example, we will use an AutoARIMA. Import the models you need.[24, 24 * 7] for
season length. The trend component will be forecasted with an
AutoARIMA model. (You can also try with: AutoTheta, AutoCES, and
AutoETS)
StatsForecast object with the
following required parameters:
-
models: a list of models. Select the models you want from models and import them. -
freq: a string indicating the frequency of the data. (See panda’s available frequencies.)
Tip StatsForecast also supports this optional parameter.Use the
n_jobs: n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. (Default: 1)fallback_model: a model to be used if a model fails. (Default: none)
fit method to fit each model to each time series. In this
case, we are just fitting one model to one series. Check this guide to
learn how to fit many models to many
series.
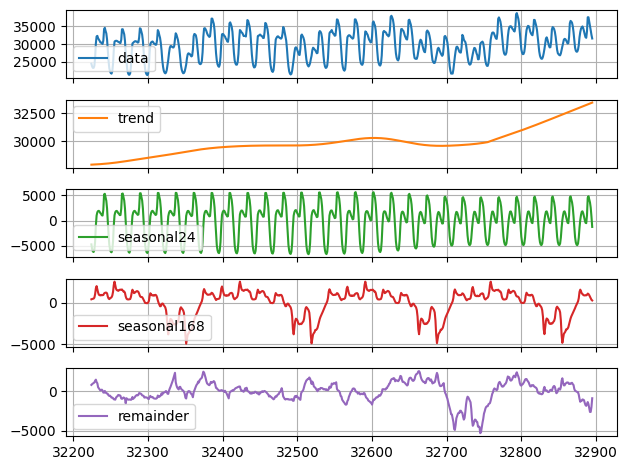
Decompose the series
Once the model is fitted, access the decomposition using thefitted_
attribute of StatsForecast. This attribute stores all relevant
information of the fitted models for each of the time series.
In this case, we are fitting a single model for a single time series, so
by accessing the fitted_ location [0, 0] we will find the relevant
information of our model. The MSTL class generates a model_
attribute that contains the way the series was decomposed.
We will use matplotlib, to visualize the different components of the
series.
Predict the next 24 hours
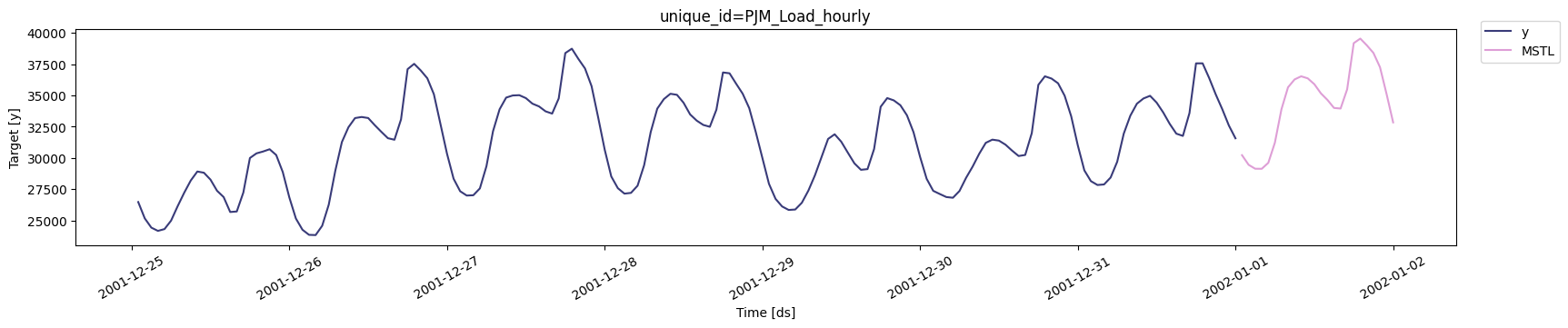
Probabilistic forecasting with levelsTo generate forecasts use the
predict method.
The predict method takes two arguments: forecasts the next h (for
horizon) and level.
-
h(int): represents the forecast h steps into the future. In this case, 12 months ahead. -
level(list of floats): this optional parameter is used for probabilistic forecasting. Set thelevel(or confidence percentile) of your prediction interval. For example,level=[90]means that the model expects the real value to be inside that interval 90% of the times.
You can plot the forecast by calling the
StatsForecast.plot method and
passing in your forecast dataframe.
Forecast in production
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the .forecast doest not store the fitted
values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
-
h(int): represents the forecast h steps into the future. In this case, 12 months ahead. -
level(list of floats): this optional parameter is used for probabilistic forecasting. Set thelevel(or confidence percentile) of your prediction interval. For example,level=[90]means that the model expects the real value to be inside that interval 90% of the times.