

Step-by-step guide on using theDuring this walkthrough, we will become familiar with the mainSeasonalExponentialSmoothing ModelwithStatsforecast.
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation in other.
The text in this article is largely taken from: 1. Changquan Huang •
Alla Petukhina. Springer series (2022). Applied Time Series Analysis and
Forecasting with
Python. 2.
Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic
Adaptive Model (ADAM) 3. James D.
Hamilton. Time Series Analysis Princeton University Press, Princeton,
New Jersey, 1st Edition,
1994.
4. Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting
Principles and Practice (3rd ed)”.
Table of Contents
- Introduction
- Seasonal Exponential Smoothing
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of SeasonalExponentialSmoothing with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
Simple Exponential Smoothing (SES) is a forecasting method that uses a weighted average of historical values to predict the next value. The weight is assigned to the most recent values, and the oldest values receive a lower weight. This is because SES assumes that more recent values are more relevant to predicting the future than older values. SES is implemented by a simple formula: The smoothing factor controls the amount of weight that is assigned to the most recent values. A higher α value means more weight will be assigned to newer values, while a lower α value means more weight will be assigned to older values. Seasonality in time series refers to the regular, repeating pattern of variation in a time series over a specified period of time. Seasonality can be a challenge to deal with in time series analysis, as it can obscure the underlying trend in the data. Seasonality is an important factor to consider when analyzing time series data. By understanding the seasonal patterns in the data, it is possible to make more accurate forecasts and better decisions.Seasonal Exponential Smoothing Model
The simplest of the exponentially smoothing methods is naturally called simple exponential smoothing (SES). This method is suitable for forecasting data with no clear trend or seasonal pattern. Using the naïve method, all forecasts for the future are equal to the last observed value of the series, for . Hence, the naïve method assumes that the most recent observation is the only important one, and all previous observations provide no information for the future. This can be thought of as a weighted average where all of the weight is given to the last observation. Using the average method, all future forecasts are equal to a simple average of the observed data, for Hence, the average method assumes that all observations are of equal importance, and gives them equal weights when generating forecasts. We often want something between these two extremes. For example, it may be sensible to attach larger weights to more recent observations than to observations from the distant past. This is exactly the concept behind simple exponential smoothing. Forecasts are calculated using weighted averages, where the weights decrease exponentially as observations come from further in the past — the smallest weights are associated with the oldest observations: where is the smoothing parameter. The one-step-ahead forecast for time is a weighted average of all of the observations in the series . The rate at which the weights decrease is controlled by the parameter . For any between 0 and 1, the weights attached to the observations decrease exponentially as we go back in time, hence the name “exponential smoothing”. If is small (i.e., close to 0), more weight is given to observations from the more distant past. If is large (i.e., close to 1), more weight is given to the more recent observations. For the extreme case where , and the forecasts are equal to the naïve forecasts.How do you know the value of the seasonal parameters?
To determine the value of the seasonal parameter s in the Seasonally AdjustedSimple Exponential Smoothing (SES Seasonally Adjusted) model,
different methods can be used, depending on the nature of the data and
the objective of the analysis.
Here are some common methods to determine the value of the seasonal
parameter :
- Visual Analysis: A visual analysis of the time series data can be performed to identify any seasonal patterns. If a clear seasonal pattern is observed in the data, the length of the seasonal period can be used as the value of .
- Statistical methods: Statistical techniques, such as autocorrelation, can be used to identify seasonal patterns in the data. The value of can be the number of periods in which a significant peak in the autocorrelation function is observed.
- Frequency Analysis: A frequency analysis of the data can be performed to identify seasonal patterns. The value of can be the number of periods in which a significant peak in the frequency spectrum is observed. see
- Trial and error: You can try different values of and select the value that results in the best fit of the model to the data.
accuracy of the seasonally adjusted SES model
predictions. Therefore, it is recommended to test different values of
and evaluate the performance of the model using appropriate
evaluation measures before selecting the final value of .
How can we validate the simple exponential smoothing model with seasonal adjustment?
To validate the Seasonally Adjusted Simple Exponential Smoothing (SES Seasonally Adjusted) model, different theorems and evaluation measures can be used, depending on the objective of the analysis and the nature of the data. Here are some common theorems used to validate the seasonally adjusted SES model:- Gauss-Markov Theorem: This theorem states that, if certain conditions are met, the least squares estimator is the best linear unbiased estimator. In the case of the seasonally adjusted SES, the model parameters are estimated using least squares, so the Gauss-Markov theorem can be used to assess the quality of model fit.
- Unit Root Theorem: This theorem is used to determine if a time series is stationary or not. If a time series is non-stationary, the seasonally adjusted SES model is not appropriate, since it assumes that the time series is stationary. Therefore, the unit root theorem is used to assess the stationarity of the time series and determine whether the seasonally adjusted SES model is appropriate.
- Ljung-Box Theorem: This theorem is used to assess the goodness of fit of the model and to determine if the model residuals are white noise. If the residuals are white noise, the model fits the data well and the model predictions are accurate. The Ljung-Box theorem is used to test whether the model residuals are independent and uncorrelated.
Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
Read Data
The input to StatsForecast is always a data frame in long format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
(ds) is in an object format, we need
to convert to a date format
Explore Data with the plot method
Plot some series using the plot method from the StatsForecast class. This method prints a random series from the dataset and is useful for basic EDA.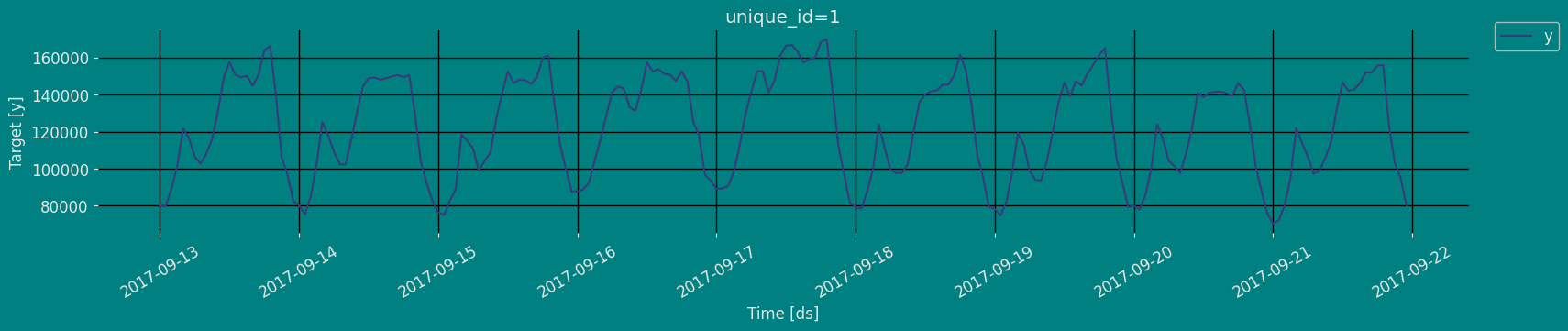
The Augmented Dickey-Fuller Test
An Augmented Dickey-Fuller (ADF) test is a type of statistical test that determines whether a unit root is present in time series data. Unit roots can cause unpredictable results in time series analysis. A null hypothesis is formed in the unit root test to determine how strongly time series data is affected by a trend. By accepting the null hypothesis, we accept the evidence that the time series data is not stationary. By rejecting the null hypothesis or accepting the alternative hypothesis, we accept the evidence that the time series data is generated by a stationary process. This process is also known as stationary trend. The values of the ADF test statistic are negative. Lower ADF values indicate a stronger rejection of the null hypothesis. Augmented Dickey-Fuller Test is a common statistical test used to test whether a given time series is stationary or not. We can achieve this by defining the null and alternate hypothesis. Null Hypothesis: Time Series is non-stationary. It gives a time-dependent trend. Alternate Hypothesis: Time Series is stationary. In another term, the series doesn’t depend on time. ADF or t Statistic < critical values: Reject the null hypothesis, time series is stationary. ADF or t Statistic > critical values: Failed to reject the null hypothesis, time series is non-stationary.Autocorrelation plots
The important characteristics of Autocorrelation (ACF) and Partial Autocorrelation (PACF) are as follows: Autocorrelation (ACF): 1. Identify patterns of temporal dependence: The ACF shows the correlation between an observation and its lagged values at different time intervals. Helps identify patterns of temporal dependency in a time series, such as the presence of trends or seasonality.- Indicates the “memory” of the series: The ACF allows us to determine how much past observations influence future ones. If the ACF shows significant autocorrelations in several lags, it indicates that the series has a long-term memory and that past observations are relevant to predict future ones.
- Helps identify MA (moving average) models: The shape of the ACF can reveal the presence of moving average components in the time series. Lags where the ACF shows a significant correlation may indicate the order of an MA model.
- Helps to identify AR (autoregressive) models: The shape of the PACF can reveal the presence of autoregressive components in the time series. Lags in which the PACF shows a significant correlation may indicate the order of an AR model.
- Used in conjunction with the ACF: The PACF is used in conjunction with the ACF to determine the order of an AR or MA model. By analyzing both the ACF and the PACF, significant lags can be identified and a model suitable for time series analysis and forecasting can be built.
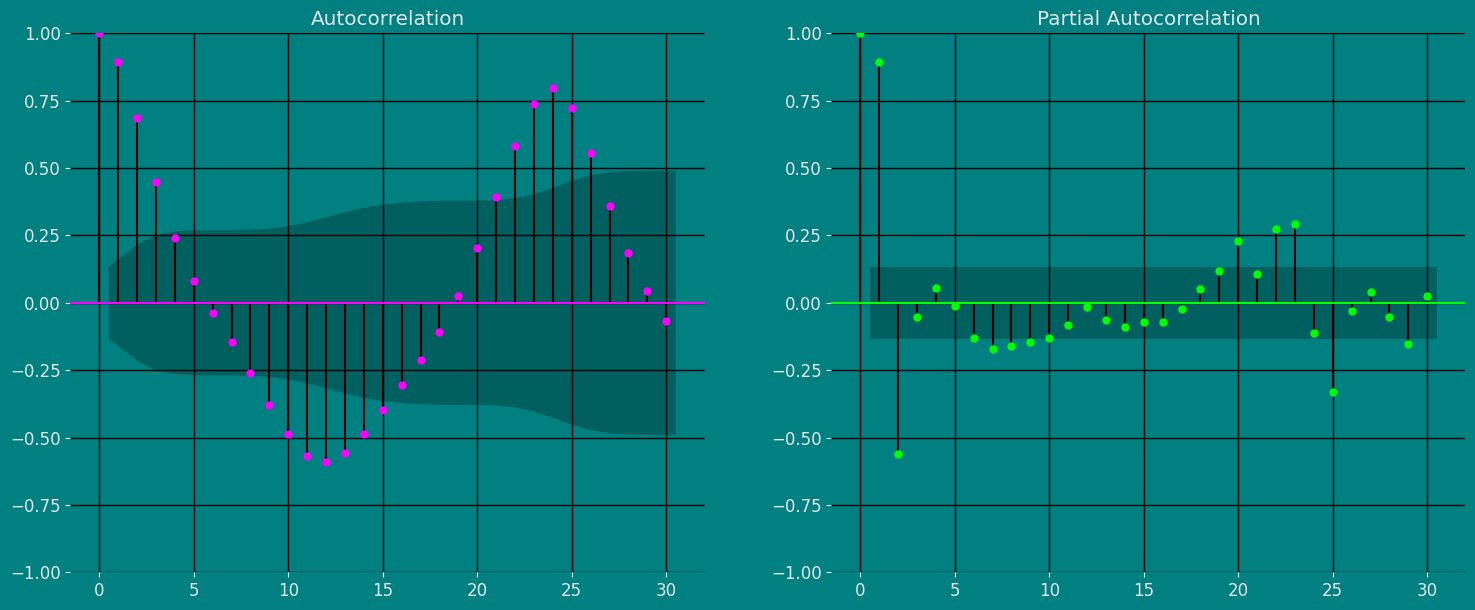
Decomposition of the time series
How to decompose a time series and why? In time series analysis to forecast new values, it is very important to know past data. More formally, we can say that it is very important to know the patterns that values follow over time. There can be many reasons that cause our forecast values to fall in the wrong direction. Basically, a time series consists of four components. The variation of those components causes the change in the pattern of the time series. These components are:- Level: This is the primary value that averages over time.
- Trend: The trend is the value that causes increasing or decreasing patterns in a time series.
- Seasonality: This is a cyclical event that occurs in a time series for a short time and causes short-term increasing or decreasing patterns in a time series.
- Residual/Noise: These are the random variations in the time series.
Additive time series
If the components of the time series are added to make the time series. Then the time series is called the additive time series. By visualization, we can say that the time series is additive if the increasing or decreasing pattern of the time series is similar throughout the series. The mathematical function of any additive time series can be represented by:Multiplicative time series
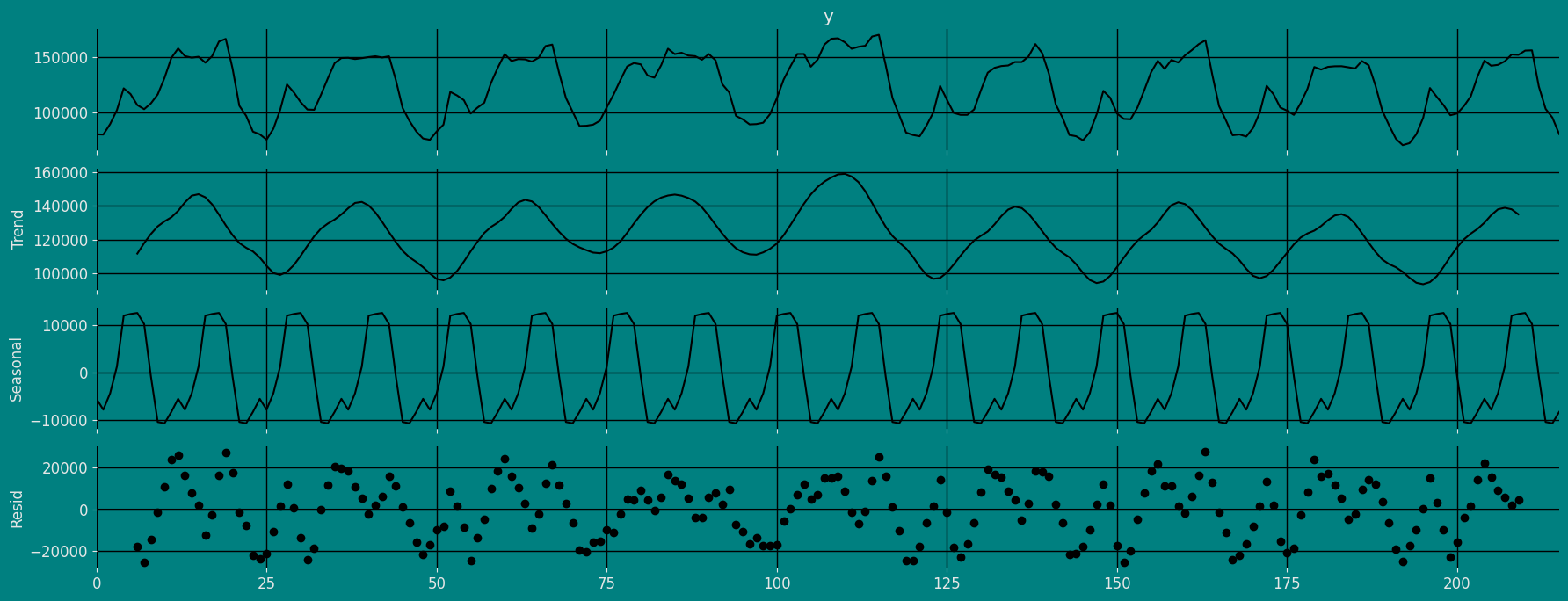
If the components of the time series are multiplicative together, then the time series is called a multiplicative time series. For visualization, if the time series is having exponential growth or decline with time, then the time series can be considered as the multiplicative time series. The mathematical function of the multiplicative time series can be represented as.Additive
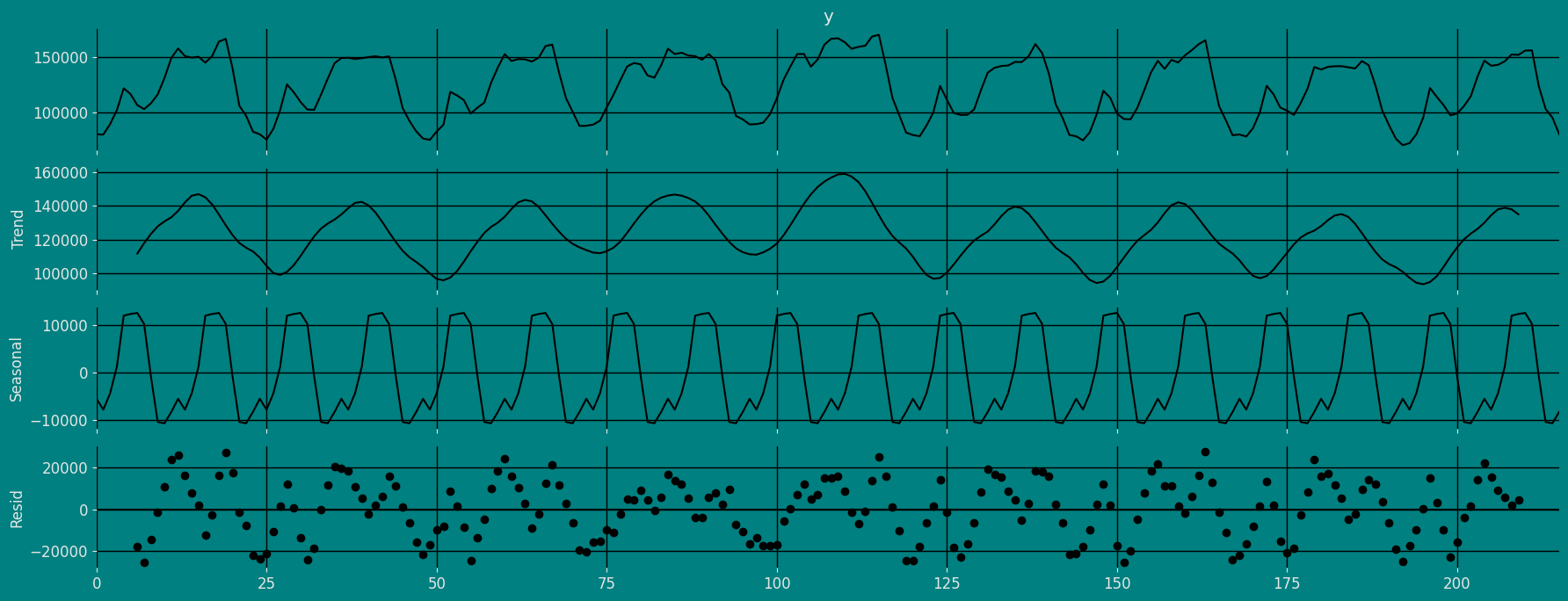
Multiplicative
Split the data into training and testing
Let’s divide our data into sets- Data to train our
Seasonal Exponential Smoothing Model. - Data to test our model
Implementation of SeasonalExponentialSmoothing with StatsForecast
Load libraries
Instantiating Model
Import and instantiate the models. Setting the argument is sometimes tricky. This article on Seasonal periods by the master, Rob Hyndmann, can be useful forseason_length.
-
freq:a string indicating the frequency of the data. (See pandas’ available frequencies.) -
n_jobs:n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model:a model to be used if a model fails.
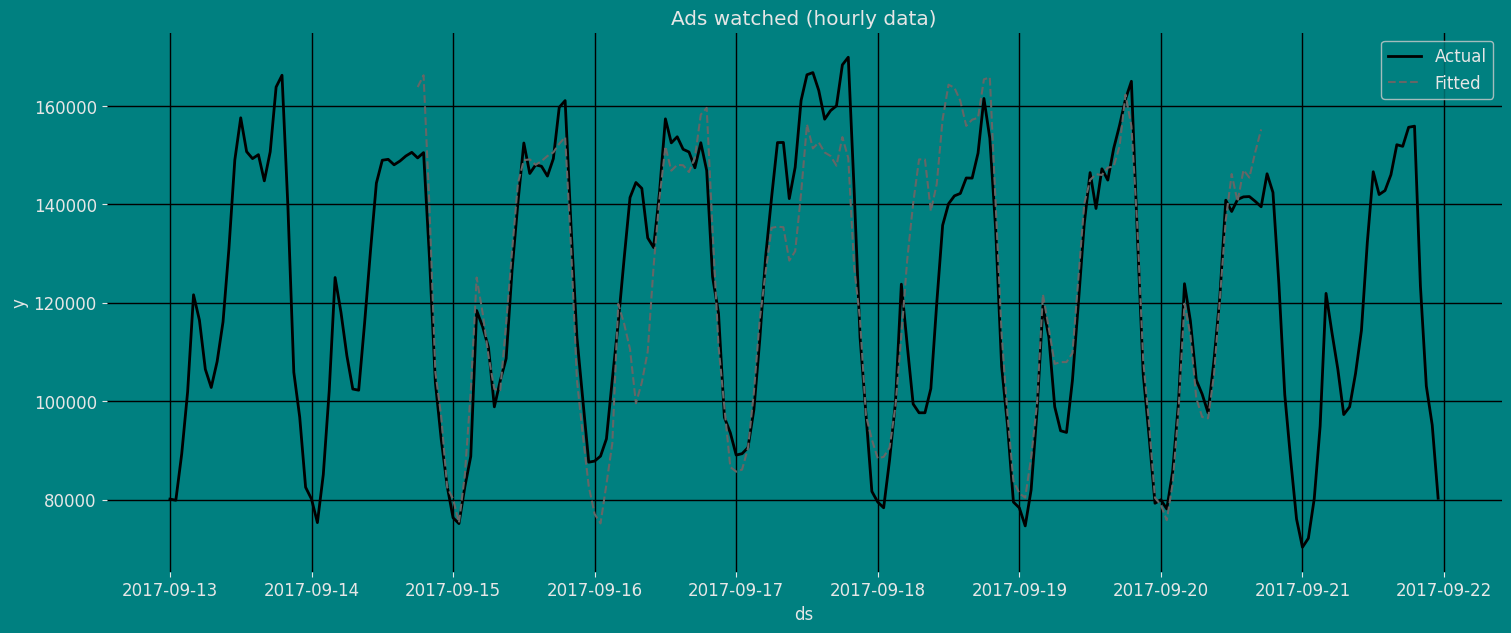
Fit the Model
Seasonal Exponential Smoothing Model. We
can observe it with the following instruction:
.get() function to extract the element and then we are going to save
it in a pd.DataFrame().
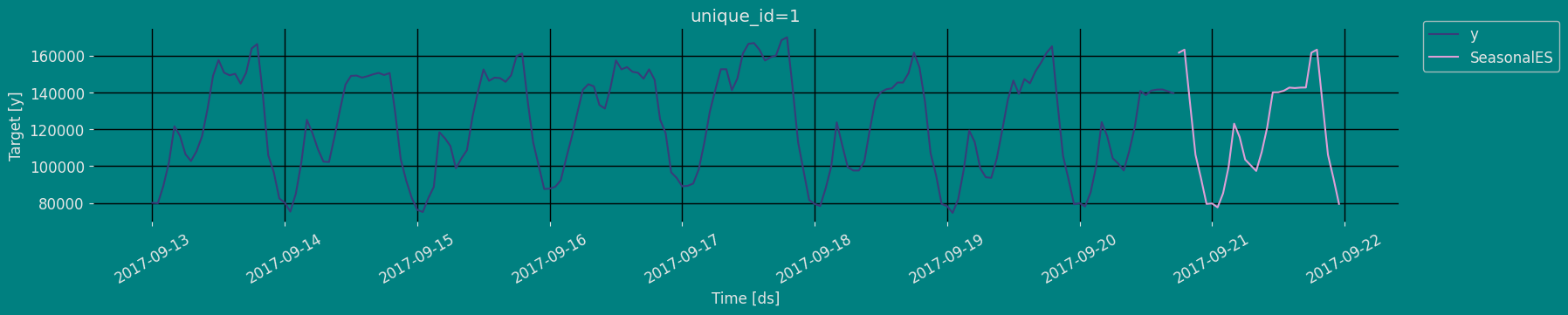
Forecast Method
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the .forecast doest not store the fitted
values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
h (int):represents the forecast h steps into the future. In this case, 30 hours ahead.
Predict method with confidence interval
To generate forecasts use the predict method. The predict method takes two arguments: forecasts the nexth (for
horizon) and level.
h (int):represents the forecast h steps into the future. In this case, 30 hourly ahead.
Cross-validation
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:
Perform time series cross-validation
Cross-validation of time series models is considered a best practice but most implementations are very slow. The statsforecast library implements cross-validation as a distributed operation, making the process less time-consuming to perform. If you have big datasets you can also perform Cross Validation in a distributed cluster using Ray, Dask or Spark. In this case, we want to evaluate the performance of each model for the last 5 months(n_windows=5), forecasting every second months
(step_size=12). Depending on your computer, this step should take
around 1 min.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df:training data frame -
h (int):represents h steps into the future that are being forecasted. In this case, 30 hourly ahead. -
step_size (int):step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int):number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_id:series identifier.ds:datestamp or temporal indexcutoff:the last datestamp or temporal index for the n_windows.y:true value"model":columns with the model’s name and fitted value.
Model Evaluation
Now we are going to evaluate our model with the results of the predictions, we will use different types of metrics MAE, MAPE, MASE, RMSE, SMAPE to evaluate the accuracy.Acknowledgements
We would like to thank Naren Castellon for writing this tutorial.References
- Changquan Huang • Alla Petukhina. Springer series (2022). Applied Time Series Analysis and Forecasting with Python.
- Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic Adaptive Model (ADAM)
- James D. Hamilton. Time Series Analysis Princeton University Press, Princeton, New Jersey, 1st Edition, 1994.
- Nixtla SeasonalExponentialSmoothing API
- Pandas available frequencies.
- Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting Principles and Practice (3rd ed)”.
- Seasonal periods- Rob J Hyndman.