

Step-by-step guide on using theDuring this walkthrough, we will become familiar with the mainSimpleExponentialSmoothing ModelwithStatsforecast.
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation in other.
The text in this article is largely taken from: 1. Changquan Huang •
Alla Petukhina. Springer series (2022). Applied Time Series Analysis and
Forecasting with
Python. 2.
Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic
Adaptive Model (ADAM) 3. James D.
Hamilton. Time Series Analysis Princeton University Press, Princeton,
New Jersey, 1st Edition,
1994.
4. Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting
Principles and Practice (3rd ed)”.
Table of Contents
- Introduction
- Simple Exponential Smoothing
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of SimpleExponentialSmoothing with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
Exponential smoothing was proposed in the late 1950s (Brown, 1959; Holt, 1957; Winters, 1960), and has motivated some of the most successful forecasting methods. Forecasts produced using exponential smoothing methods are weighted averages of past observations, with the weights decaying exponentially as the observations get older. In other words, the more recent the observation the higher the associated weight. This framework generates reliable forecasts quickly and for a wide range of time series, which is a great advantage and of major importance to applications in industry. The simple exponential smoothing model is a method used in time series analysis to predict future values based on historical observations. This model is based on the idea that future values of a time series will be influenced by past values, and that the influence of past values will decrease exponentially as you go back in time. The simple exponential smoothing model uses a smoothing factor, which is a number between 0 and 1 that indicates the relative importance given to past observations in predicting future values. A value of 1 indicates that all past observations are given equal importance, while a value of 0 indicates that only the latest observation is considered. The simple exponential smoothing model can be expressed mathematically as: where is the observed value in period , is the predicted value for the next period, y is the observed value in the previous period, and is the smoothing factor. The simple exponential smoothing model is a widely used forecasting model due to its simplicity and ease of use. However, it also has its limitations, as it cannot capture complex patterns in the data and is not suitable for time series with trends or seasonal patterns.Building of Simple exponential smoothing model
The simplest of the exponentially smoothing methods is naturally called simple exponential smoothing (SES). This method is suitable for forecasting data with no clear trend or seasonal pattern. Using the naïve method, all forecasts for the future are equal to the last observed value of the series, for . Hence, the naïve method assumes that the most recent observation is the only important one, and all previous observations provide no information for the future. This can be thought of as a weighted average where all of the weight is given to the last observation. Using the average method, all future forecasts are equal to a simple average of the observed data, for Hence, the average method assumes that all observations are of equal importance, and gives them equal weights when generating forecasts. We often want something between these two extremes. For example, it may be sensible to attach larger weights to more recent observations than to observations from the distant past. This is exactly the concept behind simple exponential smoothing. Forecasts are calculated using weighted averages, where the weights decrease exponentially as observations come from further in the past — the smallest weights are associated with the oldest observations: where is the smoothing parameter. The one-step-ahead forecast for time is a weighted average of all of the observations in the series . The rate at which the weights decrease is controlled by the parameter . For any between 0 and 1, the weights attached to the observations decrease exponentially as we go back in time, hence the name “exponential smoothing”. If is small (i.e., close to 0), more weight is given to observations from the more distant past. If is large (i.e., close to 1), more weight is given to the more recent observations. For the extreme case where , and the forecasts are equal to the naïve forecasts. We present two equivalent forms of simple exponential smoothing, each of which leads to the forecast Equation (1).Weighted average form
The forecast at time is equal to a weighted average between the most recent observation and the previous forecast : where is the smoothing parameter. Similarly, we can write the fitted values as for . (Recall that fitted values are simply one-step forecasts of the training data.) The process has to start somewhere, so we let the first fitted value at time 1 be denoted by (which we will have to estimate). Then Substituting each equation into the following equation, we obtain The last term becomes tiny for large . So, the weighted average form leads to the same forecast Equation (1).Component form
An alternative representation is the component form. For simple exponential smoothing, the only component included is the level, . Component form representations of exponential smoothing methods comprise a forecast equation and a smoothing equation for each of the components included in the method. The component form of simple exponential smoothing is given by: where is the level (or the smoothed value) of the series at time . Setting gives the fitted values, while setting gives the true forecasts beyond the training data. The forecast equation shows that the forecast value at time is the estimated level at time . The smoothing equation for the level (usually referred to as the level equation) gives the estimated level of the series at each period . If we replace with and with in the smoothing equation, we will recover the weighted average form of simple exponential smoothing. The component form of simple exponential smoothing is not particularly useful on its own, but it will be the easiest form to use when we start adding other components.Flat forecasts
Simple exponential smoothing has a “flat” forecast function: That is, all forecasts take the same value, equal to the last level component. Remember that these forecasts will only be suitable if the time series has no trend or seasonal component.Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
The input to StatsForecast is always a data frame in long format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
Explore Data with the plot method
Plot some series using the plot method from the StatsForecast class. This method prints a random series from the dataset and is useful for basic EDA.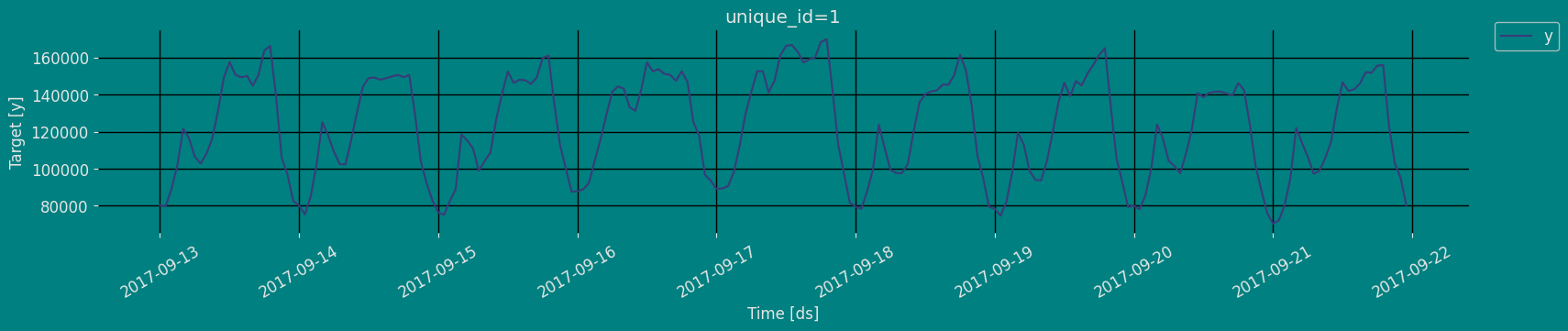
Autocorrelation plots
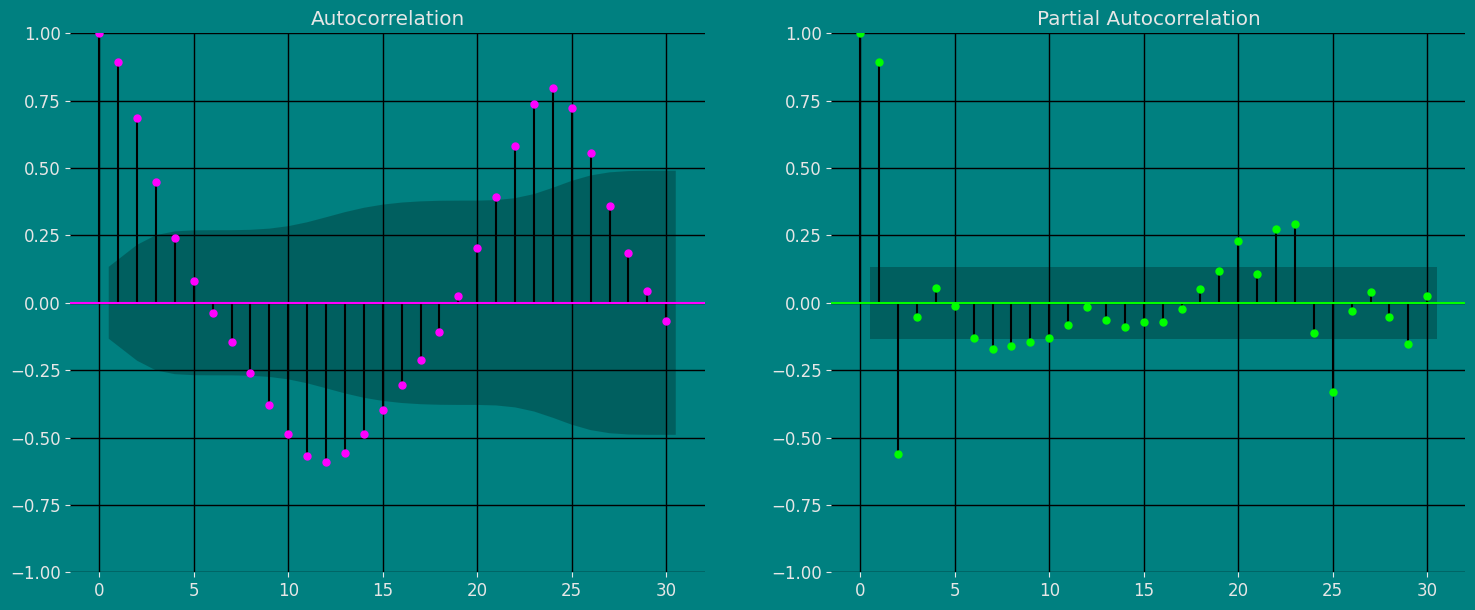
Split the data into training and testing
Let’s divide our data into sets- Data to train our
Simple Exponential Smoothing (SES). - Data to test our model
Implementation of SimpleExponentialSmoothing with StatsForecast
Load libraries
Instantiating Model
We are going to build different models, for different values of alpha.-
freq:a string indicating the frequency of the data. (See panda’s available frequencies.) -
n_jobs:n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model:a model to be used if a model fails.
Fit the Model
Simple Exponential Smoothing model (SES). We can observe it with the
following instruction:
.get() function to extract the element and then we are going to save
it in a pd.DataFrame().
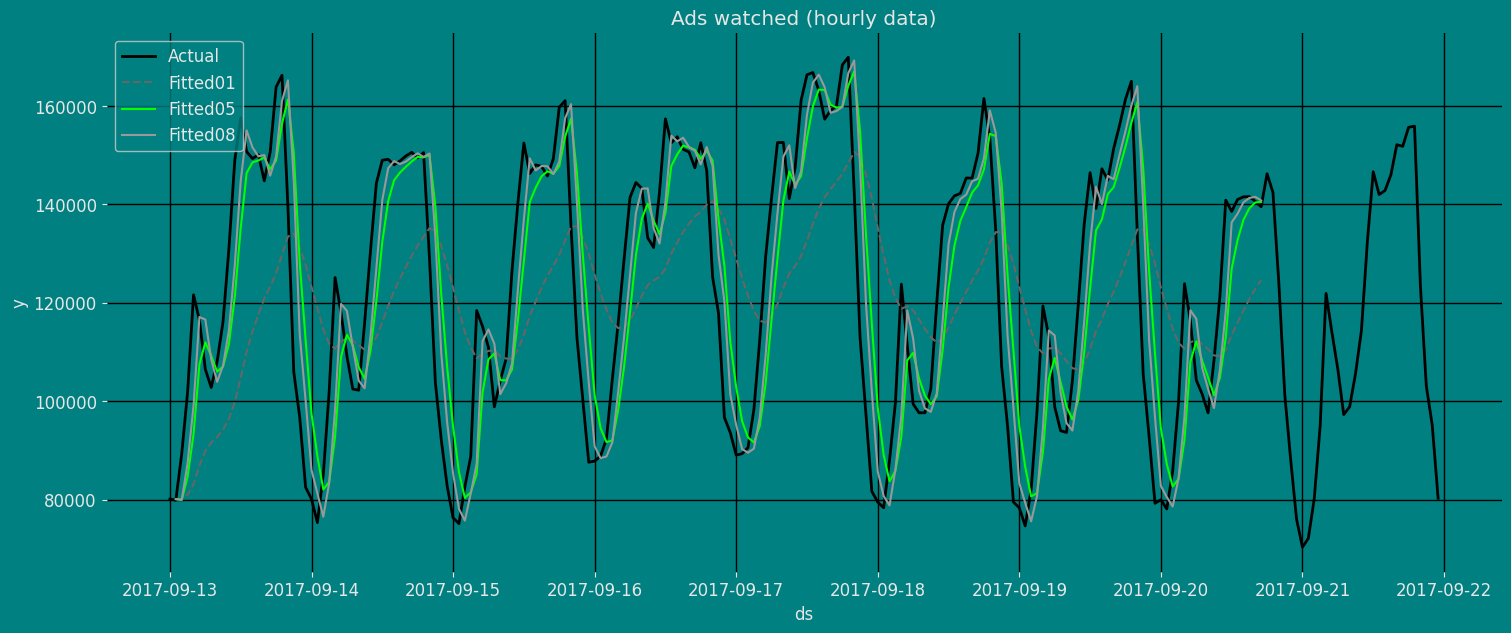
Forecast Method
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the .forecast doest not store the fitted
values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
h (int):represents the forecast h steps into the future. In this case, 30 hours ahead.
Predict method
To generate forecasts use the predict method. The predict method takes two arguments: forecasts the nexth (for
horizon). * h (int): represents the forecast steps into the
future. In this case, 30 hours ahead.
The forecast object here is a new data frame that includes a column with
the name of the model and the y hat values, as well as columns for the
uncertainty intervals.
This step should take less than 1 second.
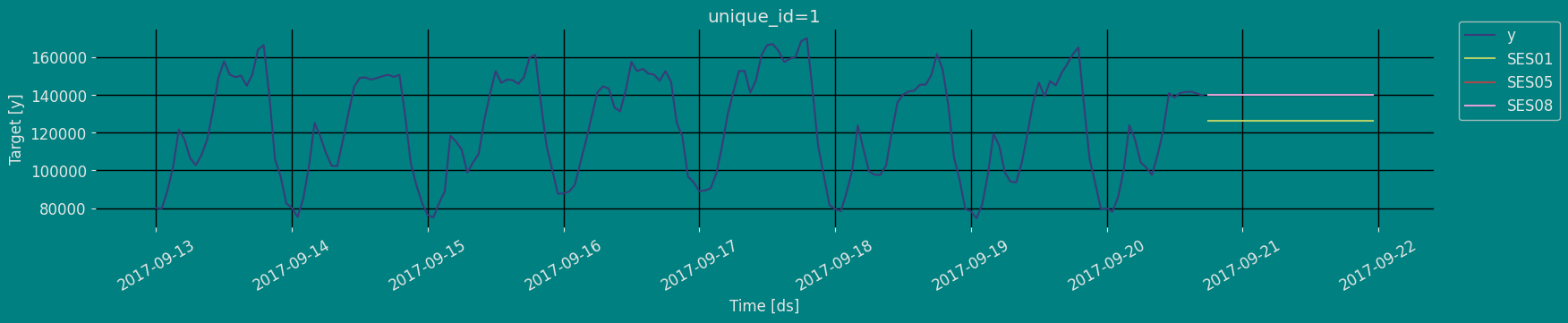
Cross-validation
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:
Perform time series cross-validation
Cross-validation of time series models is considered a best practice but most implementations are very slow. The statsforecast library implements cross-validation as a distributed operation, making the process less time-consuming to perform. If you have big datasets you can also perform Cross Validation in a distributed cluster using Ray, Dask or Spark. In this case, we want to evaluate the performance of each model for the last 30 hourly(n_windows=), forecasting every second months
(step_size=30). Depending on your computer, this step should take
around 1 min.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df:training data frame -
h (int):represents h steps into the future that are being forecasted. In this case, 30 hours ahead. -
step_size (int):step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int):number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_id:series identifierds:datestamp or temporal indexcutoff:the last datestamp or temporal index for then_windows.y:true valuemodel:columns with the model’s name and fitted value.
Model Evaluation
Now we are going to evaluate our model with the results of the predictions, we will use different types of metrics MAE, MAPE, MASE, RMSE, SMAPE to evaluate the accuracy.References
- Changquan Huang • Alla Petukhina. Springer series (2022). Applied Time Series Analysis and Forecasting with Python.
- Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic Adaptive Model (ADAM)
- James D. Hamilton. Time Series Analysis Princeton University Press, Princeton, New Jersey, 1st Edition, 1994.
- Nixtla SeasonalExponentialSmoothing API
- Pandas available frequencies.
- Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting Principles and Practice (3rd ed)”.
- Seasonal periods- Rob J Hyndman.