

Step-by-step guide on using theIn this walkthrough, we will become familiar with the mainARCH ModelwithStatsforecast.
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation.
The text in this article is largely taken from Changquan Huang • Alla
Petukhina. Springer series (2022). Applied Time Series Analysis and
Forecasting with
Python.
Table of Contents
- Introduction
- ARCH Models
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of ARCH with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
Financial time series analysis has been one of the hottest research topics in the recent decades. In this guide, we illustrate the stylized facts of financial time series by real financial data. To characterize these facts, new models different from the Box- Jenkins ones are needed. And for this reason, ARCH models were firstly proposed by R. F. Engle in 1982 and have been extended by a great number of scholars since then. We also demonstrate how to use Python and its libraries to implementARCH.
As we have known, there are lot of time series that possess the ARCH
effect, that is, although the (modeling residual) series is white noise,
its squared series may be autocorrelated. What is more, in practice, a
large number of financial time series are found having this property so
that the ARCH effect has become one of the stylized facts from financial
time series.
Stylized Facts of Financial Time Series
Now we briefly list and describe several important stylized facts (features) of financial return series:- Fat (heavy) tails: The distribution density function of returns often has fatter (heavier) tails than the tails of the corresponding normal distribution density.
- ARCH effect: Although the return series can often be seen as a white noise, its squared (and absolute) series may usually be autocorrelated, and these autocorrelations are hardly negative.
- Volatility clustering: Large changes in returns tend to cluster in time, and small changes tend to be followed by small changes.
- Asymmetry: As we have know , the distribution of asset returns is slightly negatively skewed. One possible explanation could be that traders react more strongly to unfavorable information than favorable information.
Definition of ARCH Models
Specifically, we give the definition of the ARCH model as follows. Definition 1. An model with order is of the form where , and are constants, , and is independent of . A stochastic process is called an process if it satisfies Eq. (1). By Definition 1, (and ) is independent of . Besides, usually it is further assumed that . Sometimes, however, we need to further suppose that follows a standardized (skew) Student’s T distribution or a generalized error distribution in order to capture more features of a financial time series. Let denote the information set generated by , namely, the sigma field . It is easy to see that is independent of for any . According to Definition 1 and the properties of the conditional mathematical expectation, we have that and This implies that is the conditional variance of and it evolves according to the previous values of like an model. And so Model (1) is named an model. As an example of models, let us consider the model Explicitly, the unconditional mean Additionally, the ARCH(1) model can be expressed as that is, where . It can been shown that is a new white noise, which is left as an exercise for reader. Hence, if , Eq. (4) is a stationary model for the series Xt2. Thus, the unconditional variance that is, Moreover, for , in light of the properties of the conditional mathematical expectation and by (2), we have that In conclusion, if , we have that:- Any process defined by Eqs.(3) follows a white noise .
- Since is an process defined by (4), , which reveals the ARCH effect.
- It is clear that for any ,and with Eq.(4),for any :
Advantages and disadvantages of the Autoregressive Conditional Heteroskedasticity (ARCH) model:
Note:
The ARCH model is a useful tool for modeling volatility in financial
time series, but like any econometric model, it has limitations and
should be used with caution depending on the specific characteristics of
the data being modeled.
Autoregressive Conditional Heteroskedasticity (ARCH) Applications
- Finance - The ARCH model is widely used in finance to model volatility in financial time series, such as stock prices, exchange rates, interest rates, etc.
- Economics - The ARCH model can be used to model volatility in economic data, such as GDP, inflation, unemployment, among others.
- Engineering - The ARCH model can be used in engineering to model volatility in data related to energy, climate, pollution, industrial production, among others.
- Social Sciences - The ARCH model can be used in the social sciences to model volatility in data related to demography, health, education, among others.
- Biology - The ARCH model can be used in biology to model volatility in data related to evolution, genetics, epidemiology, among others.
Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
Read Data
Let’s pull the S&P500 stock data from the Yahoo Finance site.-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
Explore data with the plot method
Plot a series using the plot method from the StatsForecast class. This method prints a random series from the dataset and is useful for basic EDA.
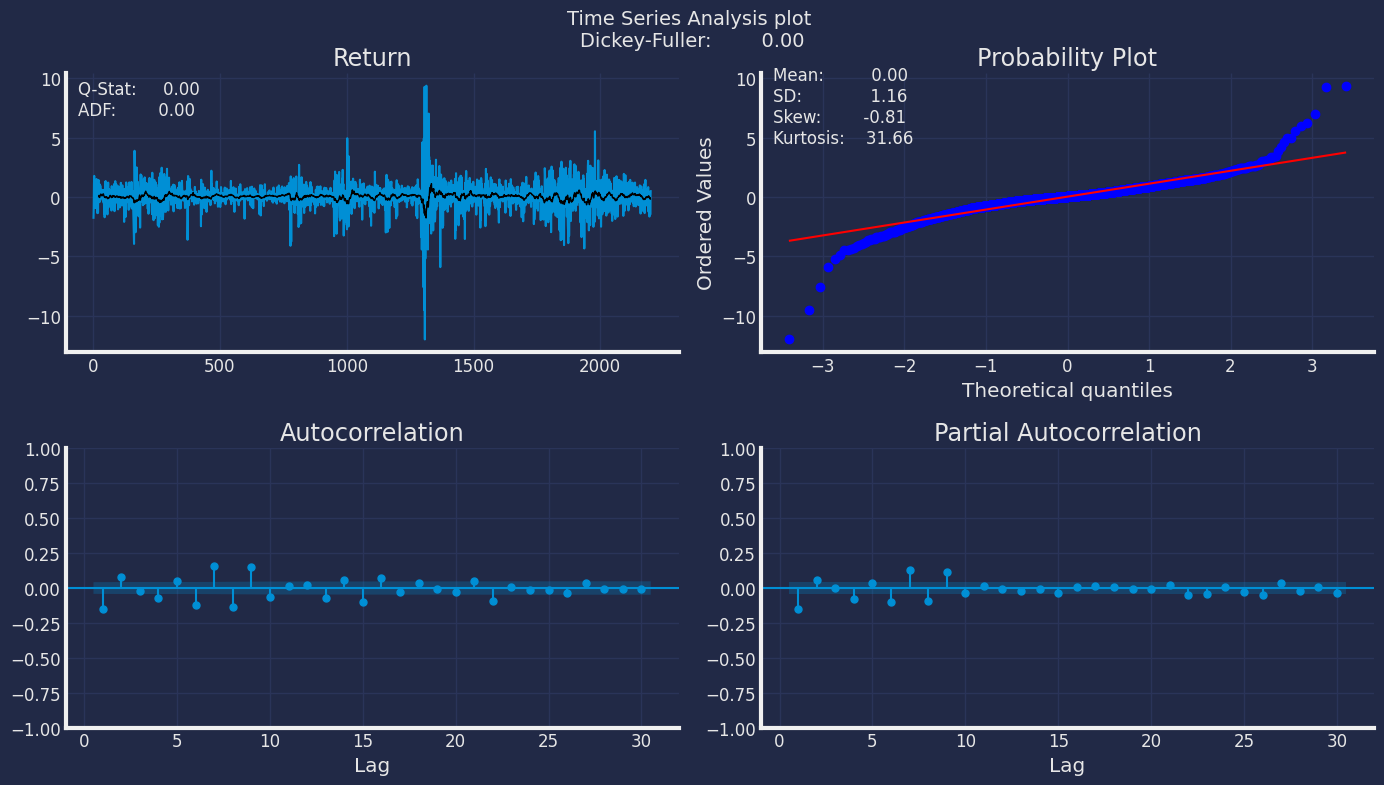
The Augmented Dickey-Fuller Test
An Augmented Dickey-Fuller (ADF) test is a type of statistical test that determines whether a unit root is present in time series data. Unit roots can cause unpredictable results in time series analysis. A null hypothesis is formed in the unit root test to determine how strongly time series data is affected by a trend. By accepting the null hypothesis, we accept the evidence that the time series data is not stationary. By rejecting the null hypothesis or accepting the alternative hypothesis, we accept the evidence that the time series data is generated by a stationary process. This process is also known as stationary trend. The values of the ADF test statistic are negative. Lower ADF values indicate a stronger rejection of the null hypothesis. Augmented Dickey-Fuller Test is a common statistical test used to test whether a given time series is stationary or not. We can achieve this by defining the null and alternate hypothesis. Null Hypothesis: Time Series is non-stationary. It gives a time-dependent trend. Alternate Hypothesis: Time Series is stationary. In another term, the series doesn’t depend on time. ADF or t Statistic < critical values: Reject the null hypothesis, time series is stationary. ADF or t Statistic > critical values: Failed to reject the null hypothesis, time series is non-stationary. Let’s check if our series that we are analyzing is a stationary series. Let’s create a function to check, using theDickey Fuller test
Augmented_Dickey_Fuller
test gives us a p-value of 0.864700, which tells us that the null
hypothesis cannot be rejected, and on the other hand the data of our
series are not stationary.
We need to differentiate our time series, in order to convert the data
to stationary.
Return Series
Since the 1970s, the financial industry has been very prosperous with advancement of computer and Internet technology. Trade of financial products (including various derivatives) generates a huge amount of data which form financial time series. For finance, the return on a financial product is most interesting, and so our attention focuses on the return series. If is the closing price at time t for a certain financial product, then the return on this product is It is return series that have been much independently studied. And important stylized features which are common across many instruments, markets, and time periods have been summarized. Note that if you purchase the financial product, then it becomes your asset, and its returns become your asset returns. Now let us look at the following examples. We can estimate the series of returns using the pandas,DataFrame.pct_change() function. The pct_change() function has a
periods parameter whose default value is 1. If you want to calculate a
30-day return, you must change the value to 30.
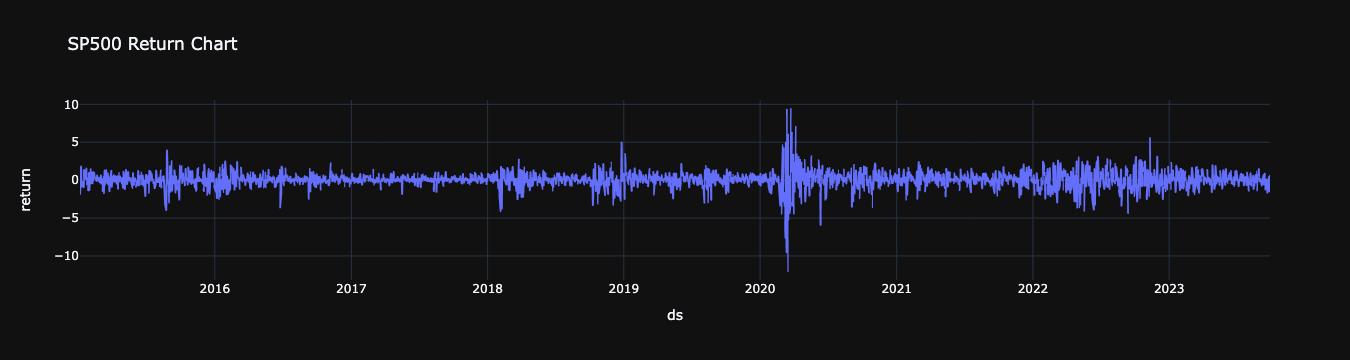
Creating Squared Returns
Returns vs Squared Returns
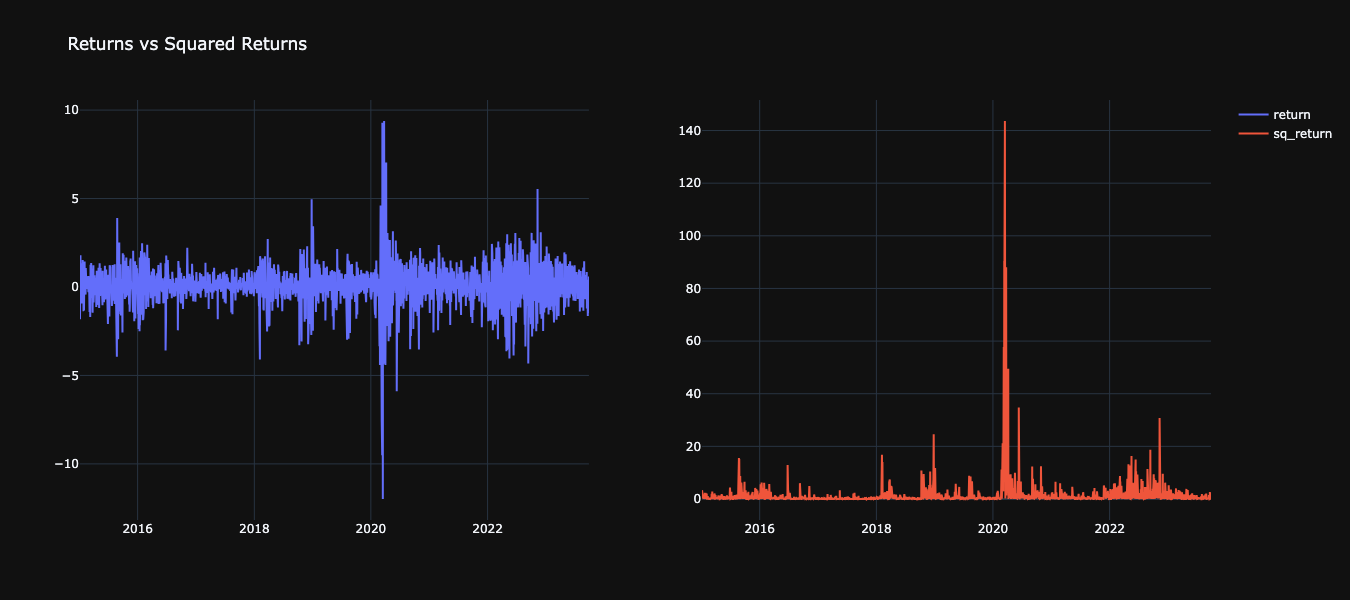
Ljung-Box Test
Ljung-Box is a test for autocorrelation that we can use in tandem with our ACF and PACF plots. The Ljung-Box test takes our data, optionally either lag values to test, or the largest lag value to consider, and whether to compute the Box-Pierce statistic. Ljung-Box and Box-Pierce are two similar test statisitcs, Q , that are compared against a chi-squared distribution to determine if the series is white noise. We might use the Ljung-Box test on the residuals of our model to look for autocorrelation, ideally our residuals would be white noise.- Ho : The data are independently distributed, no autocorrelation.
- Ha : The data are not independently distributed; they exhibit serial correlation.
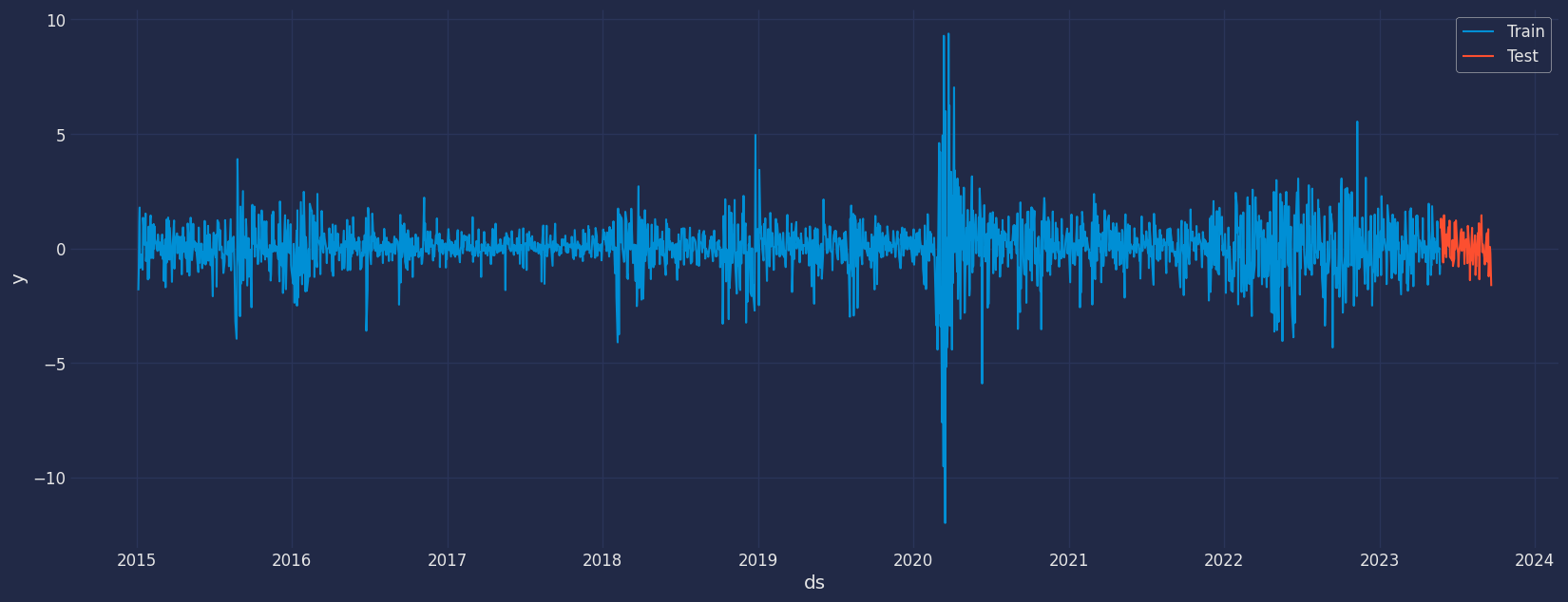
Split the data into training and testing
Let’s divide our data into sets- Data to train our
ARCHmodel - Data to test our model
Implementation of ARCH with StatsForecast
To also know more about the parameters of the functions of theARCH Model, they are listed below. For more information, visit the
documentation
Load libraries
Building Model
Import and instantiate the models. Setting the argument is sometimes tricky. This article on Seasonal periods by the master, Rob Hyndmann, can be useful.season_length.-
freq:a string indicating the frequency of the data. (See pandas’ available frequencies.) -
n_jobs:n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model:a model to be used if a model fails.
Fit the Model
.get() function to extract the element and then we are going to save
it in a pd.DataFrame().
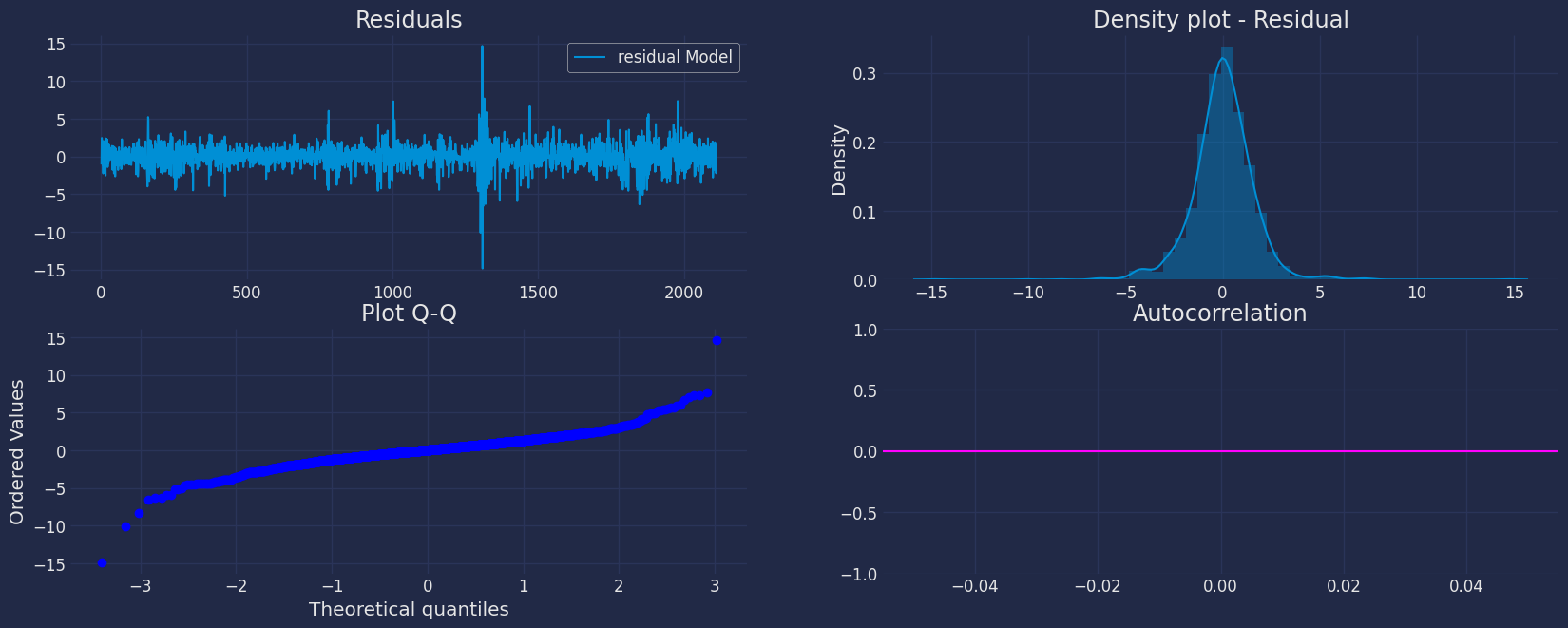
Forecast Method
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the .forecast doest not store the fitted
values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[90]means that the model expects the real value to be inside that interval 90% of the times.
Adding 95% confidence interval with the forecast method
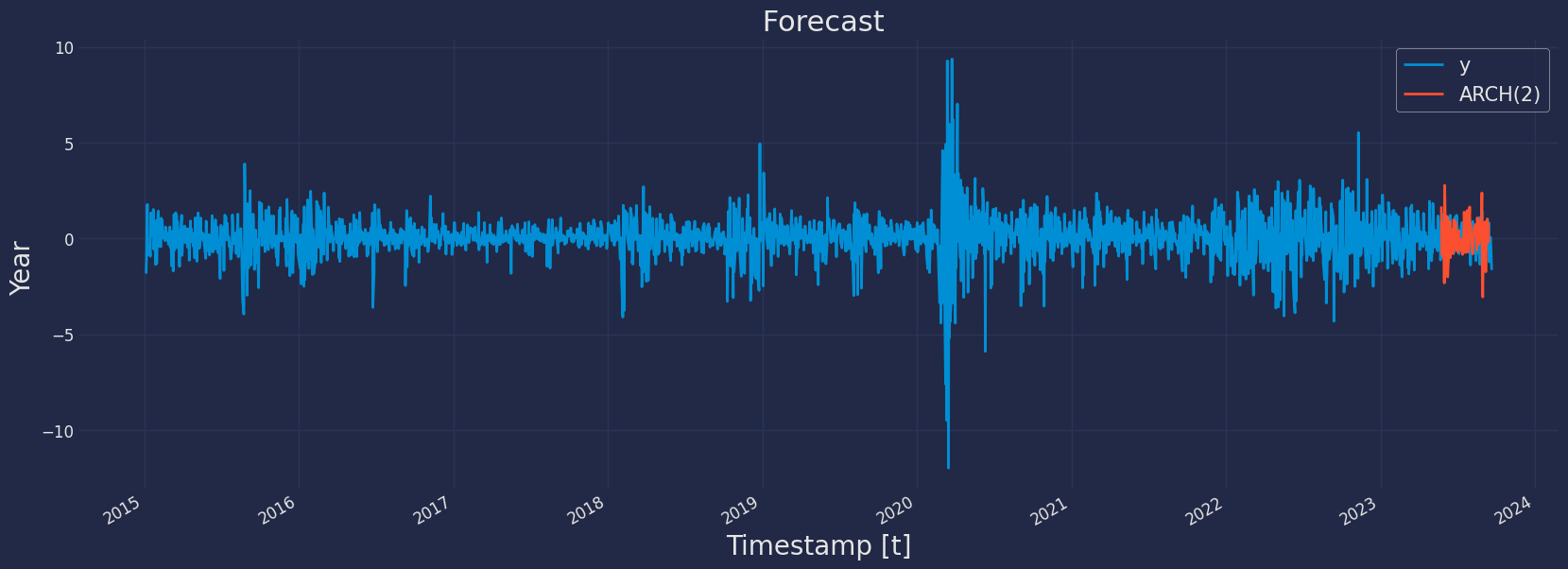
Predict method with confidence interval
To generate forecasts use the predict method. The predict method takes two arguments: forecasts the nexth (for
horizon) and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[95]means that the model expects the real value to be inside that interval 95% of the times.
We can join the forecast result with the historical data using the
pandas function
pd.concat(), and then be able to use this result for
graphing.

Statsforecast, as shown below.
Cross-validation
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:
Perform time series cross-validation
Cross-validation of time series models is considered a best practice but most implementations are very slow. The statsforecast library implements cross-validation as a distributed operation, making the process less time-consuming to perform. If you have big datasets you can also perform Cross Validation in a distributed cluster using Ray, Dask or Spark. In this case, we want to evaluate the performance of each model for the last 5 months(n_windows=5), forecasting every second months
(step_size=12). Depending on your computer, this step should take
around 1 min.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df:training data frame -
h (int):represents h steps into the future that are being forecasted. In this case, 12 months ahead. -
step_size (int):step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int):number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_id:series identifierds:datestamp or temporal indexcutoff:the last datestamp or temporal index for the n_windows.y:true value"model":columns with the model’s name and fitted value.
Model Evaluation
Now we are going to evaluate our model with the results of the predictions, we will use different types of metrics MAE, MAPE, MASE, RMSE, SMAPE to evaluate the accuracy.References
- Changquan Huang • Alla Petukhina. Springer series (2022). Applied Time Series Analysis and Forecasting with Python.
- Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica: Journal of the econometric society, 987-1007..
- James D. Hamilton. Time Series Analysis Princeton University Press, Princeton, New Jersey, 1st Edition, 1994.
- Nixtla ARCH API
- Pandas available frequencies.
- Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting Principles and Practice (3rd ed)”.
- Seasonal periods- Rob J Hyndman.