

Step-by-step guide on using theDuring this walkthrough, we will become familiar with the mainStandard Theta ModelwithStatsforecast.
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation in other.
The text in this article is largely taken from: 1. Jose A. Fiorucci,
Tiago R. Pellegrini, Francisco Louzada, Fotios Petropoulos, Anne B.
Koehler (2016). “Models for optimising the theta method and their
relationship to state space models”. International Journal of
Forecasting.
2. V. Assimakopoulos, K. Nikolopoulos, “The theta model: a
decomposition approach to
forecasting”
3. Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting
Principles and Practice (3rd ed)”.
Table of Contents
- Introduction
- Standard Theta
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of StandardTheta with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
The Theta method (Assimakopoulos & Nikolopoulos, 2000, hereafter A&N) is applied to non-seasonal or deseasonalised time series, where the deseasonalisation is usually performed via the multiplicative classical decomposition. The method decomposes the original time series into two new lines through the so-called theta coefficients, denoted by and for , which are applied to the second difference of the data. The second differences are reduced when , resulting in a better approximation of the long-term behaviour of the series (Assimakopoulos, 1995). If is equal to zero, the new line is a straight line. When the local curvatures are increased, magnifying the short-term movements of the time series (A&N). The new lines produced are called theta lines, denoted here by and . These lines have the same mean value and slope as the original data, but the local curvatures are either filtered out or enhanced, depending on the value of the coefficient. In other words, the decomposition process has the advantage of exploiting information in the data that usually cannot be captured and modelled completely through the extrapolation of the original time series. The theta lines can be regarded as new time series and are extrapolated separately using an appropriate forecasting method. Once the extrapolation of each theta line has been completed, recomposition takes place through a combination scheme in order to calculate the point forecasts of the original time series. Combining has long been considered as a useful practice in the forecasting literature (for example, Clemen, 1989, Makridakis and Winkler, 1983, Petropoulos et al., 2014), and therefore its application to the Theta method is expected to result in more accurate and robust forecasts. The Theta method is quite versatile in terms of choosing the number of theta lines, the theta coefficients and the extrapolation methods, and combining these to obtain robust forecasts. However, A&N proposed a simplified version involving the use of only two theta lines with prefixed coefficients that are extrapolated over time using a linear regression (LR) model for the theta line with and simple exponential smoothing (SES) for the theta line with . The final forecasts are produced by combining the forecasts of the two theta lines with equal weights. The performance of the Theta method has also been confirmed by other empirical studies (for example Nikolopoulos et al., 2012, Petropoulos and Nikolopoulos, 2013). Moreover, Hyndman and Billah (2003), hereafter H&B, showed that the simple exponential smoothing with drift model (SES-d) is a statistical model for the simplified version of the Theta method. More recently, Thomakos and Nikolopoulos (2014) provided additional theoretical insights, while Thomakos and Nikolopoulos (2015) derived new theoretical formulations for the application of the method to multivariate time series, and investigated the conditions under which the bivariate Theta method is expected to forecast better than the univariate one. Despite these advances, we believe that the Theta method deserves more attention from the forecasting community, given its simplicity and superior forecasting performance. One key aspect of the Theta method is that, by definition, it is dynamic. One can choose different theta lines and combine the produced forecasts using either equal or unequal weights. However, AN limit this important property by fixing the theta coefficients to have predefined values.Standard Theta Model
Assimakopoulos and Nikolopoulo for standard theta model proposed the Theta line as the solution of the equation where represent the original time series data and . The initial values and are obtained by minimizing . However, the analytical solution of (1) is given by where and are the minimum square coefficients of a simple linear regression over against which are only dependent on the original data and given as follow Theta lines can be understood as functions of the linear regression model directly applied to the data from this perspective. Indeed, the Theta method’s projections for h steps ahead are an ad hoc combination (50 percent - 50 percent) of the linear extrapolations of and .- When is applied to the second differences of the data, the decomposition process is defined by a theta coefficient, which reduces the second differences and improves the approximation of series behavior.
- If , the deconstructed line is turned into a constant straight line. (see Fig)
- If then the short term movements of the analyzed series show more local curvatures (see fig)
- Deseasonalisation: Firstly, the time series data is tested for statistically significant seasonal behaviour. A time series is seasonal if
-
Decomposition: The second step consits for the decomposition of
the seasonally adjusted time series into two Theta lines, the
linear regressionline and the theta line . -
Extrapolation: is extrapolated using
simple exponential smoothing (SES), while is extrapolated as a normallinear regressionline. - Combination: the final forecast is a combination of the forecasts of the two lines using equal weights.
- Reseasonalisation: In the presence of seasonality in first step, then the final forecasts are multiplied by the respective seasonal indices.
Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
Read Data
The input to StatsForecast is always a data frame in long format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
(ds) is in an object format, we need
to convert to a date format
Explore Data with the plot method
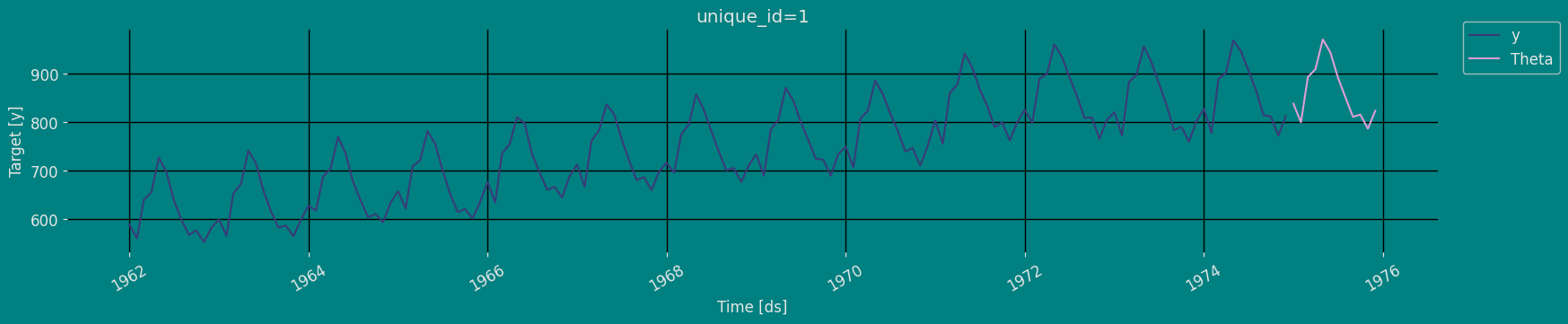
Plot some series using the plot method from the StatsForecast class. This method prints a random series from the dataset and is useful for basic EDA.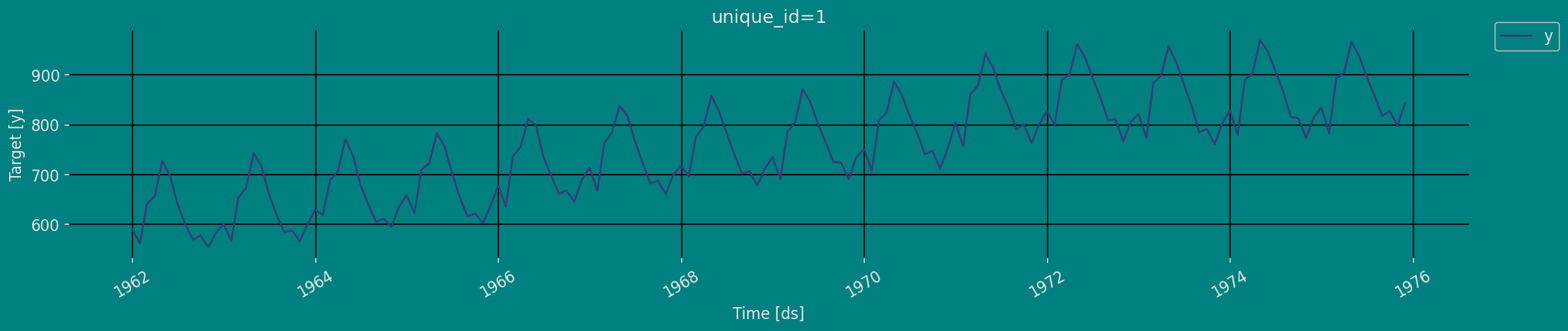
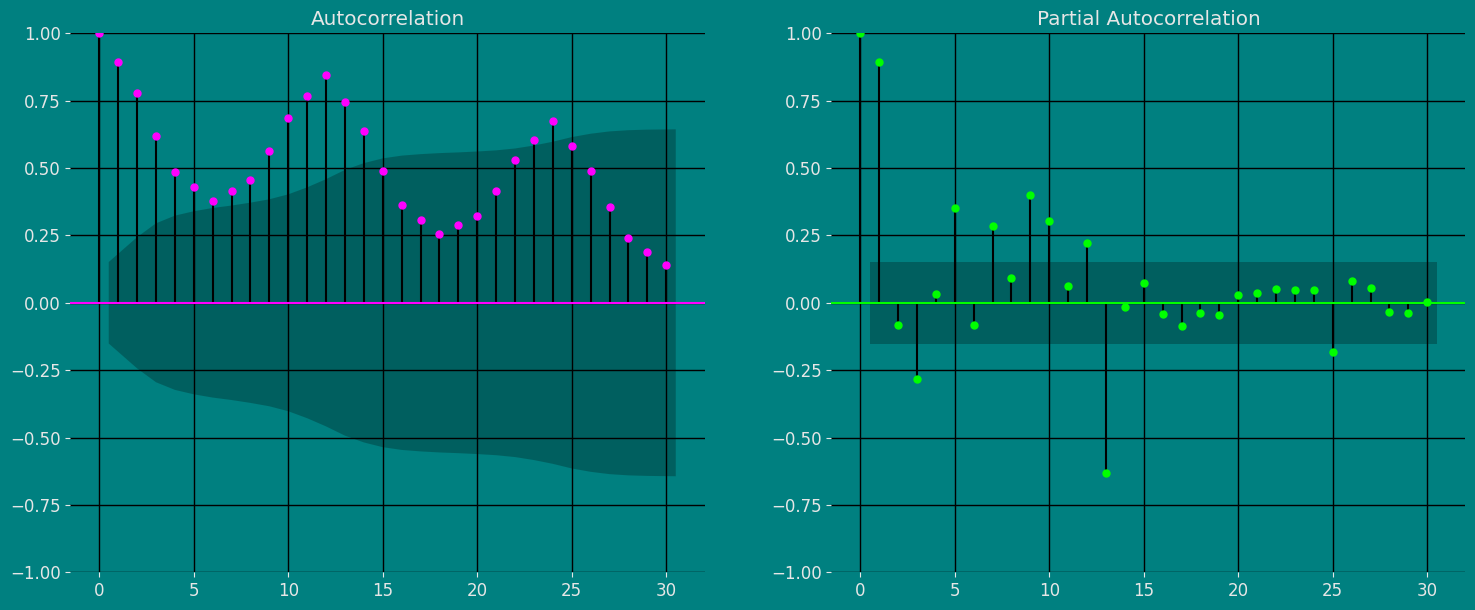
Autocorrelation plots
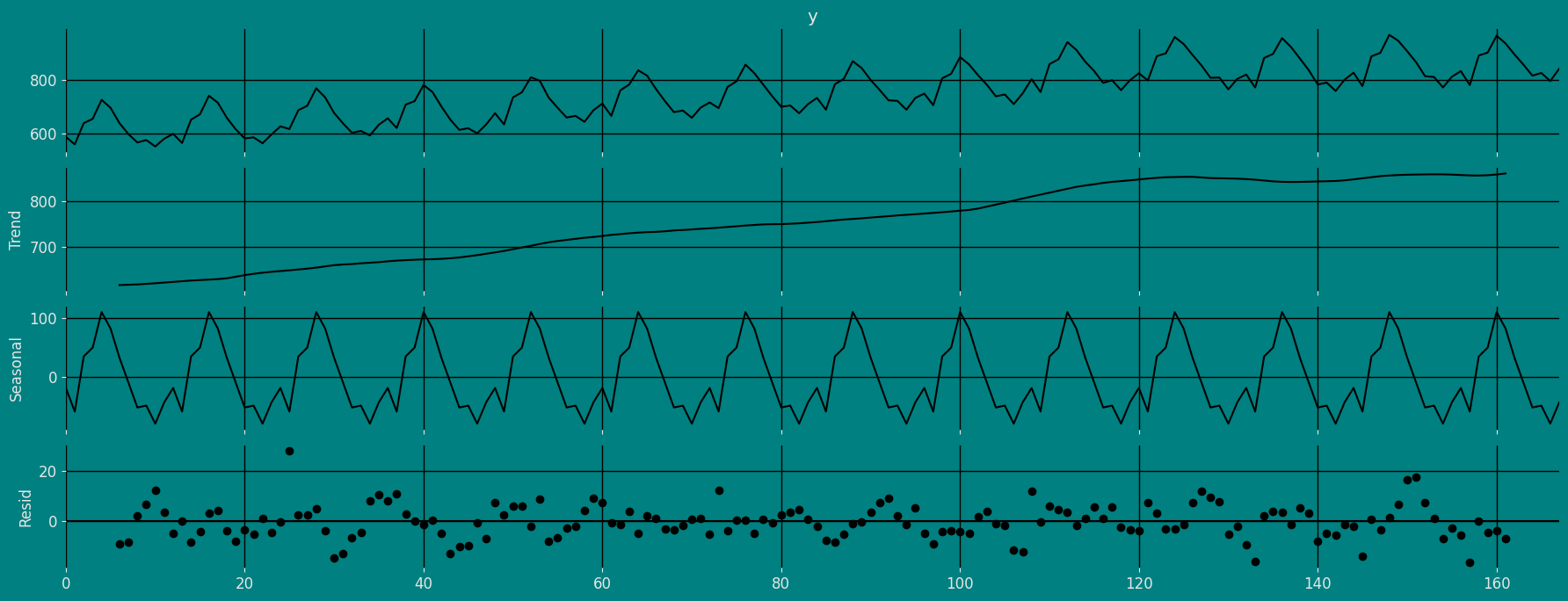
Decomposition of the time series
How to decompose a time series and why? In time series analysis to forecast new values, it is very important to know past data. More formally, we can say that it is very important to know the patterns that values follow over time. There can be many reasons that cause our forecast values to fall in the wrong direction. Basically, a time series consists of four components. The variation of those components causes the change in the pattern of the time series. These components are:- Level: This is the primary value that averages over time.
- Trend: The trend is the value that causes increasing or decreasing patterns in a time series.
- Seasonality: This is a cyclical event that occurs in a time series for a short time and causes short-term increasing or decreasing patterns in a time series.
- Residual/Noise: These are the random variations in the time series.
Additive time series
If the components of the time series are added to make the time series. Then the time series is called the additive time series. By visualization, we can say that the time series is additive if the increasing or decreasing pattern of the time series is similar throughout the series. The mathematical function of any additive time series can be represented by:Multiplicative time series
If the components of the time series are multiplicative together, then the time series is called a multiplicative time series. For visualization, if the time series is having exponential growth or decline with time, then the time series can be considered as the multiplicative time series. The mathematical function of the multiplicative time series can be represented as.Additive
Multiplicative
Split the data into training and testing
Let’s divide our data into sets 1. Data to train ourTheta model 2.
Data to test our model
For the test data we will use the last 12 months to test and evaluate
the performance of our model.
Implementation of StandardTheta with StatsForecast
Load libraries
Instantiating Model
Import and instantiate the models. Setting the argument is sometimes tricky. This article on Seasonal periods by the master, Rob Hyndmann, can be useful forseason_length.
-
freq:a string indicating the frequency of the data. (See panda’s available frequencies.) -
n_jobs:n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model:a model to be used if a model fails.
Fit Model
.get() function to extract the element and then we are going to save
it in a pd.DataFrame().
Forecast Method
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the .forecast doest not store the fitted
values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[90]means that the model expects the real value to be inside that interval 90% of the times.
Adding 95% confidence interval with the forecast method
Predict method with confidence interval
To generate forecasts use the predict method. The predict method takes two arguments: forecasts the nexth (for
horizon) and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[95]means that the model expects the real value to be inside that interval 95% of the times.

Cross-validation
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:
Perform time series cross-validation
Cross-validation of time series models is considered a best practice but most implementations are very slow. The statsforecast library implements cross-validation as a distributed operation, making the process less time-consuming to perform. If you have big datasets you can also perform Cross Validation in a distributed cluster using Ray, Dask or Spark. In this case, we want to evaluate the performance of each model for the last 5 months(n_windows=5), forecasting every second months
(step_size=12). Depending on your computer, this step should take
around 1 min.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df:training data frame -
h (int):represents h steps into the future that are being forecasted. In this case, 12 months ahead. -
step_size (int):step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int):number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_id:series identifierds:datestamp or temporal indexcutoff:the last datestamp or temporal index for the n_windows.y:true value"model":columns with the model’s name and fitted value.
Model Evaluation
Now we are going to evaluate our model with the results of the predictions, we will use different types of metrics MAE, MAPE, MASE, RMSE, SMAPE to evaluate the accuracy.Acknowledgements
We would like to thank Naren Castellon for writing this tutorial.References
- Jose A. Fiorucci, Tiago R. Pellegrini, Francisco Louzada, Fotios Petropoulos, Anne B. Koehler (2016). “Models for optimising the theta method and their relationship to state space models”. International Journal of Forecasting.
- V. Assimakopoulos, K. Nikolopoulos, “The theta model: a decomposition approach to forecasting”
- Nixtla StandardTheta API
- Pandas available frequencies.
- Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting Principles and Practice (3rd ed)”.
- Seasonal periods- Rob J Hyndman.