

In this example we will show how to perform electricity load forecasting considering a model capable of handling multiple seasonalities (MSTL).
Introduction
Some time series are generated from very low frequency data. These data generally exhibit multiple seasonalities. For example, hourly data may exhibit repeated patterns every hour (every 24 observations) or every day (every 24 * 7, hours per day, observations). This is the case for electricity load. Electricity load may vary hourly, e.g., during the evenings electricity consumption may be expected to increase. But also, the electricity load varies by week. Perhaps on weekends there is an increase in electrical activity. In this example we will show how to model the two seasonalities of the time series to generate accurate forecasts in a short time. We will use hourly PJM electricity load data. The original data can be found here.Libraries
In this example we will use the following libraries:StatsForecast. Lightning ⚡️ fast forecasting with statistical and econometric models. Includes the MSTL model for multiple seasonalities.Prophet. Benchmark model developed by Facebook.NeuralProphet. Deep Learning version ofProphet. Used as benchark.
Forecast using Multiple Seasonalities
Electricity Load Data
According to the dataset’s page,PJM Interconnection LLC (PJM) is a regional transmission organization (RTO) in the United States. It is part of the Eastern Interconnection grid operating an electric transmission system serving all or parts of Delaware, Illinois, Indiana, Kentucky, Maryland, Michigan, New Jersey, North Carolina, Ohio, Pennsylvania, Tennessee, Virginia, West Virginia, and the District of Columbia. The hourly power consumption data comes from PJM’s website and are in megawatts (MW).Let’s take a look to the data.
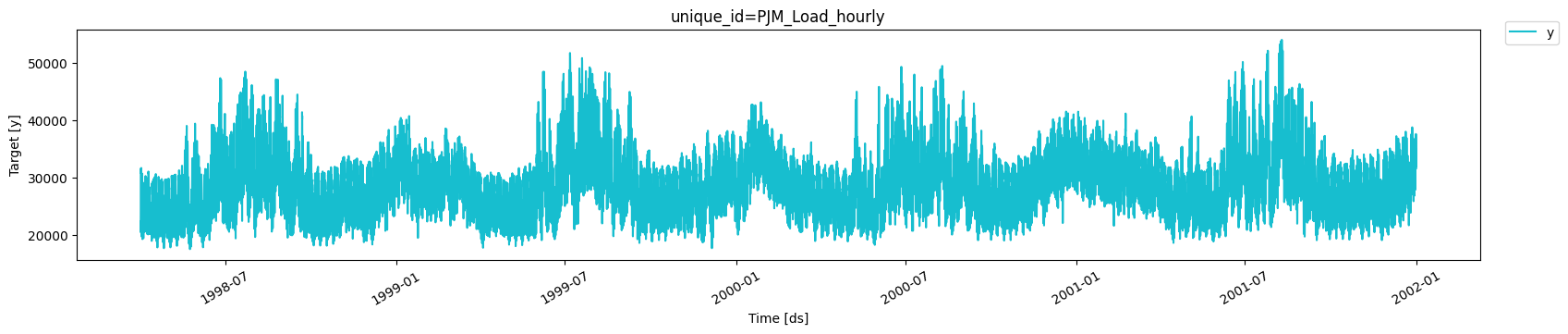
32,896 observations, so it is
necessary to use very computationally efficient methods to display them
in production.
MSTL model
The MSTL (Multiple Seasonal-Trend decomposition using LOESS) model, originally developed by Kasun Bandara, Rob J Hyndman and Christoph Bergmeir, decomposes the time series in multiple seasonalities using a Local Polynomial Regression (LOESS). Then it forecasts the trend using a custom non-seasonal model and each seasonality using a SeasonalNaive model.StatsForecast contains a fast implementation of the
MSTL model. Also,
the decomposition of the time series can be calculated.
[24, 24 * 7] as
the seasonalities that the
MSTL model receives.
We must also specify the manner in which the trend will be forecasted.
In this case we will use the
AutoARIMA model.
StatsForecast class to create forecasts.
Fit the model
Afer that, we just have to use thefit method to fit each model to
each time series.
Decompose the time series in multiple seasonalities
Once the model is fitted, we can access the decomposition using thefitted_ attribute of StatsForecast. This attribute stores all
relevant information of the fitted models for each of the time series.
In this case we are fitting a single model for a single time series, so
by accessing the fitted_ location [0, 0] we will find the relevant
information of our model. The MSTL
class generates a model_ attribute that contains the way the series
was decomposed.
Let’s look graphically at the different components of the time series.
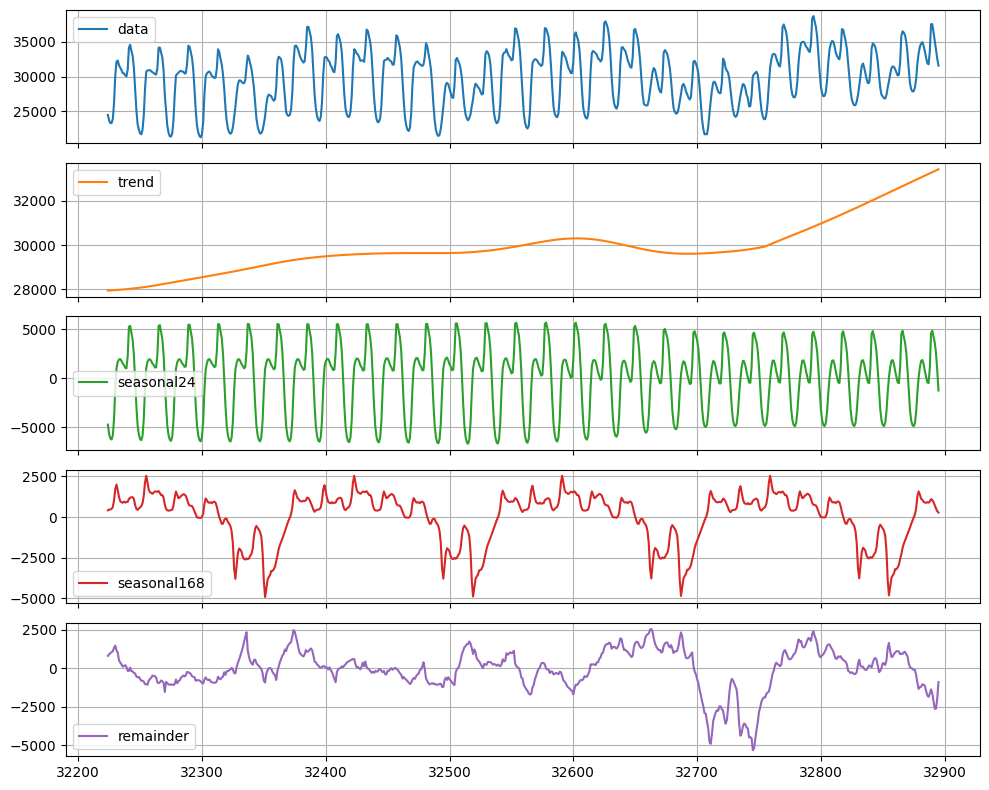
24 * 7 hours there is a very
well defined pattern. These two components will be forecast separately
using a SeasonalNaive model.
Produce forecasts
To generate forecasts we only have to use thepredict method
specifying the forecast horizon (h). In addition, to calculate
prediction intervals associated to the forecasts, we can include the
parameter level that receives a list of levels of the prediction
intervals we want to build. In this case we will only calculate the 90%
forecast interval (level=[90]).
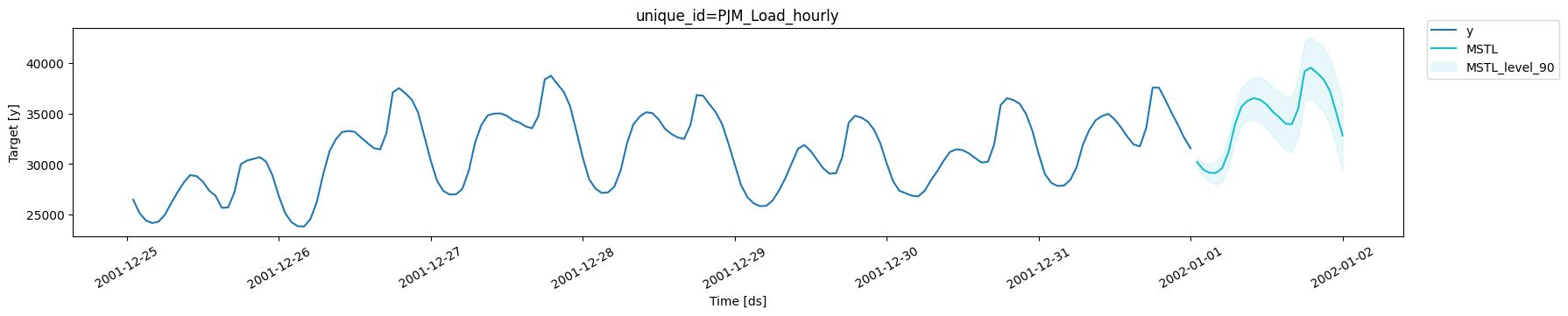
Let’s look at our forecasts graphically.
Performance of the MSTL model
Split Train/Test sets
To validate the accuracy of theMSTL model, we will show its
performance on unseen data. We will use a classical time series
technique that consists of dividing the data into a training set and a
test set. We will leave the last 24 observations (the last day) as the
test set. So the model will train on 32,872 observations.
MSTL model
In addition to theMSTL model, we will include the
SeasonalNaive model as a
benchmark to validate the added value of the MSTL model. Including
StatsForecast models is as simple as adding them to the list of models
to be fitted.
time module.

MSTL.
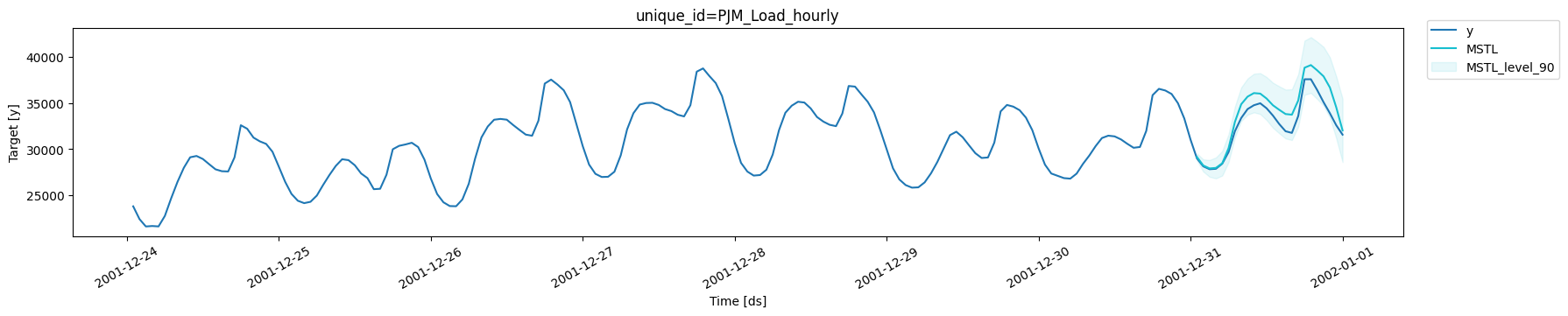
MSTL produces very accurate forecasts that follow the
behavior of the time series. Now let us calculate numerically the
accuracy of the model. We will use the following metrics: MAE, MAPE,
MASE, RMSE, SMAPE.
MSTL has an improvement of about 35% over the
SeasonalNaive method in the test set measured in MASE.
Comparison with Prophet
One of the most widely used models for time series forecasting isProphet. This model is known for its ability to model different
seasonalities (weekly, daily yearly). We will use this model as a
benchmark to see if the MSTL adds value for this time series.
We observe that the time required for
Prophet to perform the fit and
predict pipeline is greater than MSTL. Let’s look at the forecasts
produced by Prophet.

Prophet is able to capture the overall behavior of the
time series. However, in some cases it produces forecasts well below the
actual value. It also does not correctly adjust the valleys.
Prophet is not able to produce better forecasts
than the SeasonalNaive model, however, the MSTL model improves
Prophet’s forecasts by 45% (MASE).
Comparison with NeuralProphet
NeuralProphet is the version of Prophet using deep learning. This
model is also capable of handling different seasonalities so we will
also use it as a benchmark.
We observe that
NeuralProphet requires a longer processing time than
Prophet and MSTL.

NeuralProphet generates very similar
results to Prophet, as expected.
NeuralProphet improves the
results of Prophet, as expected, however, MSTL improves over
NeuralProphet’s foreacasts by 44% (MASE).
Important
The performance of NeuralProphet can be improved using
hyperparameter optimization, which can increase the fitting time
significantly. In this example we show its performance with the
default version.
Conclusion
In this post we introducedMSTL, a model originally developed by
Kasun Bandara, Rob Hyndman and Christoph
Bergmeir capable of handling time
series with multiple seasonalities. We also showed that for the PJM
electricity load time series offers better performance in time and
accuracy than the Prophet and NeuralProphet models.