

Step-by-step guide on using theThe objective of the following article is to obtain a step-by-step guide on building the CES model usingAutoCES ModelwithStatsforecast.
AutoCES with Statsforecast.
During this walkthrough, we will become familiar with the main
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation in other.
The text in this article is largely taken from: 1. Ivan Svetunkov,
Nikolaos Kourentzes, John Keith Ord, “Complex exponential
smoothing”
2. Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting
Principles and Practice (3rd ed)”.
Table of Contents
- Introduction
- Complex Exponential Smoothing
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of AutoCES with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
Exponential smoothing has been one of the most popular forecasting methods used to support various decisions in organizations, in activities such as inventory management, scheduling, revenue management, and other areas. Although its relative simplicity and transparency have made it very attractive for research and practice, identifying the underlying trend remains challenging with significant impact on the resulting accuracy. This has resulted in the development of various modifications of trend models, introducing a model selection problem. With the aim of addressing this problem, we propose the complex exponential smoothing (CES), based on the theory of functions of complex variables. The basic CES approach involves only two parameters and does not require a model selection procedure. Despite these simplifications, CES proves to be competitive with, or even superior to existing methods. We show that CES has several advantages over conventional exponential smoothing models: it can model and forecast both stationary and non-stationary processes, and CES can capture both level and trend cases, as defined in the conventional exponential smoothing classification. CES is evaluated on several forecasting competition datasets, demonstrating better performance than established benchmarks. We conclude that CES has desirable features for time series modeling and opens new promising avenues for research.Complex Exponential Smoothing
Method and model
Using the complex valued representation of time series, we propose the CES in analogy to the conventional exponential smoothing methods. Consider the simple exponential smoothing method: where is the smoothing parameter and is the estimated value of series. The same method can be represented as a weighted average of previous actual observations if we substitute by the formula (1) with an index instead of (Brown, 1956): The idea of this representation is to demonstrate how the weights are distributed over time in our sample. If the smoothing parameter then the weights decline exponentially with the increase of . If it lies in the so called “admissible bounds” (Brenner et al., 1968), that is then the weights decline in oscillating manner. Both traditional and admissible bounds have been used efficiently in practice and in academic literature (for application of the latter see for example Gardner & Diaz-Saiz, 2008; Snyder et al., 2017). However, in real life the distribution of weights can be more complex, with harmonic rather than exponential decline, meaning that some of the past observation might have more importance than the recent ones. In order to implement such distribution of weights, we build upon (2) and introduce complex dynamic interactions by substituting the real variables with the complex ones in (2). First, we substitute by the complex variable , where is the error term of the model and is the imaginary unit (which satisfies the equation ). The idea behind this is to have the impact of both actual values and the error on each observation in the past on the final forecast. Second, we substitute with a complex variable and 1 by to introduce the harmonically declining weights. Depending on the values of the complex smoothing parameter, the weights distribution will exhibit a variety of trajectories over time, including exponential, oscillating, and harmonic. Finally, the result of multiplication of two complex numbers will be another complex number, so we substitute with , where is the proxy for the error term. The CES obtained as a result of this can be written as: Having arrived to the model with harmonically distributed weights, we can now move to the shorter form by substituting in (3) to get: Note that is not interesting for the time series analysis and forecasting purposes, but is used as a vessel containing the information about the previous errors of the method. Having the complex variables instead of the real ones in (4), allows taking the exponentially weighted values of both actuals and the forecast errors. By changing the value of , we can regulate what proportions of the actual and the forecast error should be carried out to the future in order to produce forecasts. Representing the complex-valued function as a system of two real-valued functions leads to: CES introduces an interaction between the real and imaginary parts, and the equations in (6) are connected via the previous values of each other, causing interactions over time, defined by complex smoothing parameter value. But the method itself is restrictive and does not allow easily producing prediction intervals and deriving the likelihood function. It is also important to understand what sort of statistical model underlies CES. This model can be written in the following state space form: where is the white noise error term, is the level component and is the nonlinear trend component at observation . Observe that dependencies in time series have an interactive structure and no explicit trend component is present in the time series as this model does not need to artificially break the series into level and trend, as ETS does. Although we call the component as “nonlinear trend,” it does not correspond to the conventional trend component, because it contains the information of both previous and the level . Also, note that we use instead of in (6), which means that the CES has (6) as an underlying statistical model only when there is no misspecification error. In the case of the estimation of this model, the will be substituted by , which will then lead us to the original formulation (4). This idea allows rewriting (6) in a shorter more generic way, resembling the general single source of error (SSOE) state space framework: where is the state vector is the transition matrix is the persistence vector and is the measurement vector. The state space form (7) permits extending CES in a similar ways to ETS to include additional states for seasonality or exogenous variables. The main difference between model (7) and the conventional ETS is that the transition matrix in (7) includes smoothing parameters which is not a standard feature of ETS models. Furthermore persistence vector includes the interaction of complex smoothing parameters, rather than smoothing parameters themselves. The error term in (6) is additive, so the likelihood function for CES is trivial and is similar to the one in the additive exponential smoothing models (Hyndman et al., 2008, p. 68): where is the vector of initial states, is the variance of the error term and is the vector of all the in-sample observations.Stationarity and stability conditions for CES
In order to understand the properties of CES, we need to study its stationarity and stability conditions. The former holds for general exponential smoothing in the state space form (8) when all the eigenvalues of lie inside the unit circle (Hyndman et al., 2008, p. 38). CES can be either stationary or not, depending on the complex smoothing parameter value, in contrast to ETS models that are always non-stationary. Calculating eigenvalues of for CES gives the following roots: If the absolute values of both roots are less than 1 then the estimated CES is stationary. When one of the eigenvalues will always be greater than one. In this case both eigenvalues will be real numbers and CES produces a non-stationary trajectory. When CES becomes equivalent to ETS(A,N,N). Finally, the model becomes stationary when: Note that we are not restricting CES with the conditions (10), we merely show, how the model will behave depending on the value of the complex smoothing parameter. This property of CES means that it is able to model either stationary or non-stationary processes, without the need to switch between them. The property of CES for each separate time series depends on the value of the smoothing parameters. The other important property that arises from (7) is the stability condition for CES. With the following is obtained: The matrix is called the discount matrix and can be written in the general form: The model is said to be stable if all the eigenvalues of (12) lie inside the unit circle. This is more important condition than the stationarity for the model, because it ensures that the complex weights decline over time and that the older observations have smaller weights than the new ones, which is one of the main features of the conventional ETS models. The eigenvalues are given by the following formula: CES will be stable when the following system of inequalities is satisfied: Both the stationarity and stability regions are shown in Figure 1. The stationarity region (10) corresponds to the triangle. All the combinations of smoothing parameters lying below the curve in the triangle will produce the stationary harmonic trajectories, while the rest lead to the exponential trajectories. The stability condition (14) corresponds to the dark region. The stability region intersects the stationarity region, but in general stable CES can produce both stationary and non-stationary forecastsConditional mean and variance of CES
The conditional mean of CES for steps ahead with known and can be calculated using the state space model (6): where while and re the matrices from (7). The forecasting trajectories of (15) will differ depending on the values of , and the complex smoothing parameter. The analysis of stationarity condition shows that there are several types of forecasting trajectories of CES depending on the particular value of the complex smoothing parameter:- When all the values of forecast will be equal to the last obtained forecast, which corresponds to a flat line. This trajectory is shown in Figure 2A.
- When the model produces trajectory with exponential growth which is shown in Figure 2B.
- When trajectory becomes stationary and CES produces exponential decline shown in Figure 2C.
- When trajectory becomes harmonic and will converge to zero Figure 2D.
- Finally, when the diverging harmonic trajectory is produced, the model becomes non-stationary. This trajectory is of no use in forecasting, that is why we do not show it on graphs.
Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
Read Data
The input to StatsForecast is always a data frame in long format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
Now, let’s now check the last few rows of our time series using the
.tail() function.
ds from object type to datetime.
Explore data with the plot method
Plot some series using the plot method from the StatsForecast class. This method prints a random series from the dataset and is useful for basic EDA.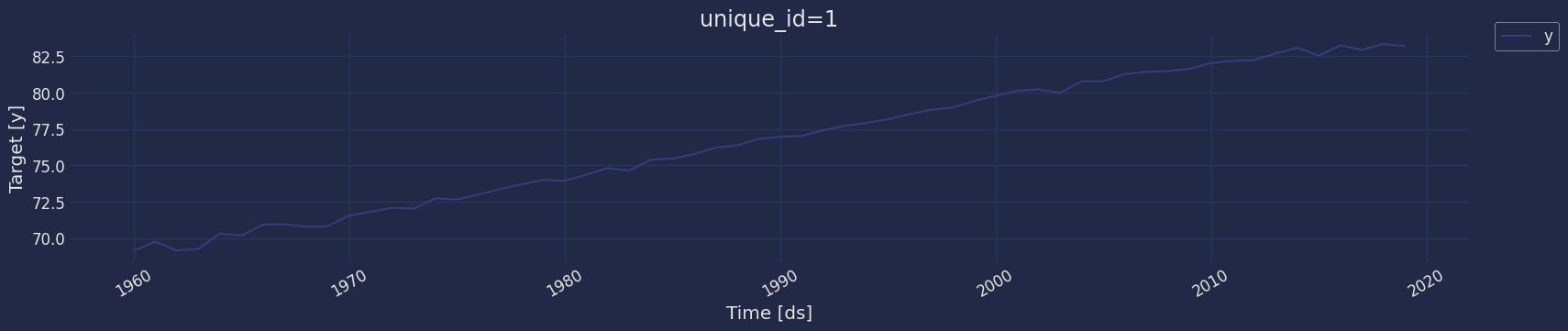
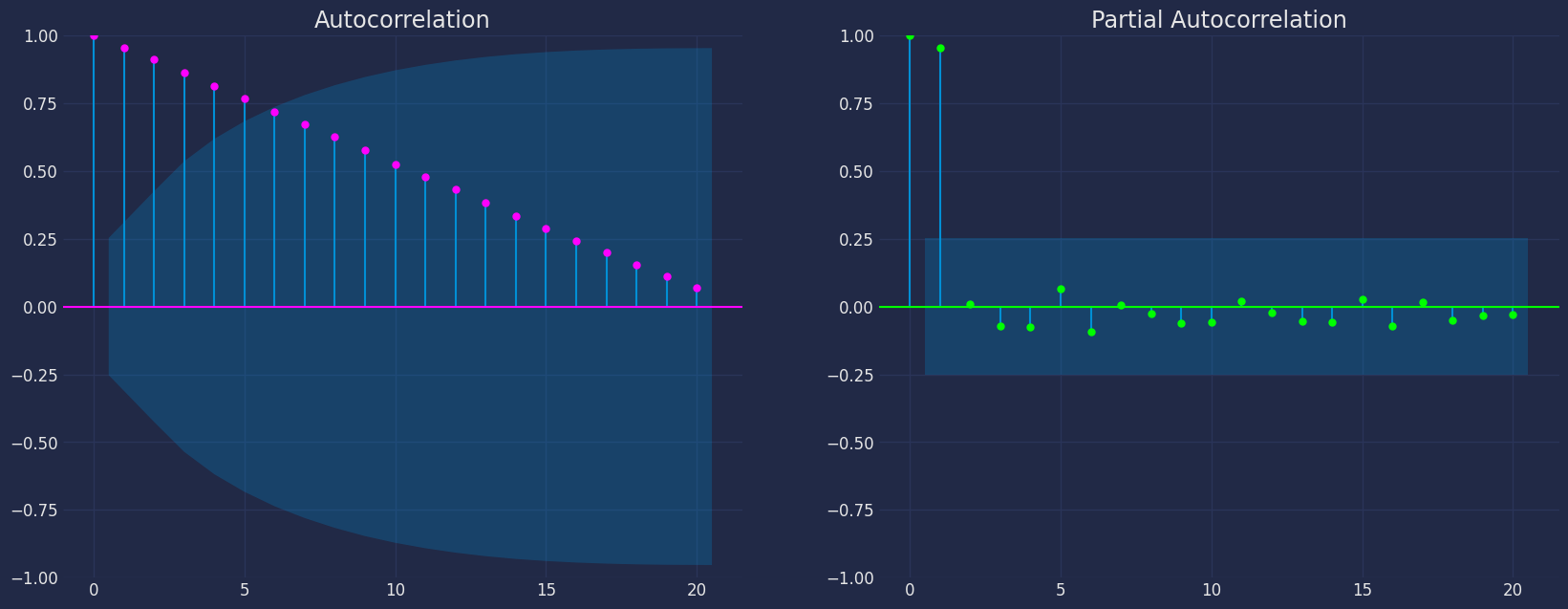
Autocorrelation plots
Decomposition of the time series
How to decompose a time series and why? In time series analysis to forecast new values, it is very important to know past data. More formally, we can say that it is very important to know the patterns that values follow over time. There can be many reasons that cause our forecast values to fall in the wrong direction. Basically, a time series consists of four components. The variation of those components causes the change in the pattern of the time series. These components are:- Level: This is the primary value that averages over time.
- Trend: The trend is the value that causes increasing or decreasing patterns in a time series.
- Seasonality: This is a cyclical event that occurs in a time series for a short time and causes short-term increasing or decreasing patterns in a time series.
- Residual/Noise: These are the random variations in the time series.
Additive time series
If the components of the time series are added to make the time series. Then the time series is called the additive time series. By visualization, we can say that the time series is additive if the increasing or decreasing pattern of the time series is similar throughout the series. The mathematical function of any additive time series can be represented by:Multiplicative time series
If the components of the time series are multiplicative together, then the time series is called a multiplicative time series. For visualization, if the time series is having exponential growth or decline with time, then the time series can be considered as the multiplicative time series. The mathematical function of the multiplicative time series can be represented as.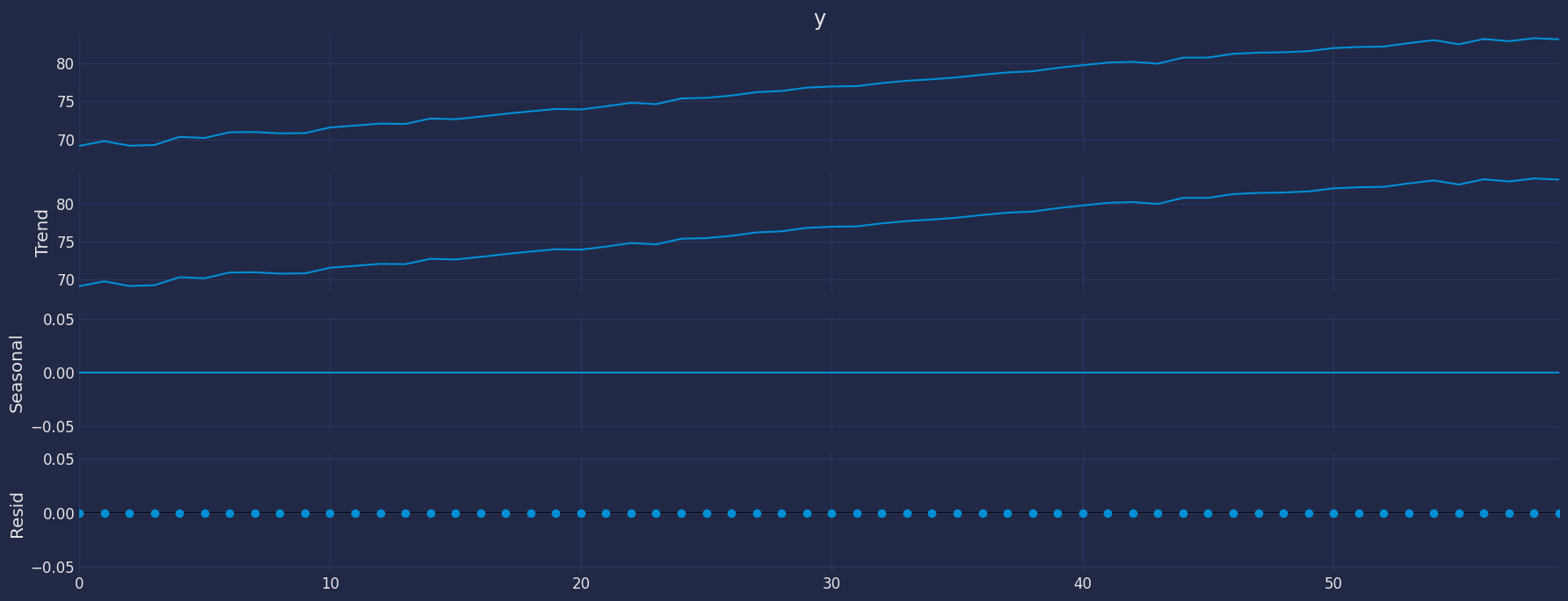
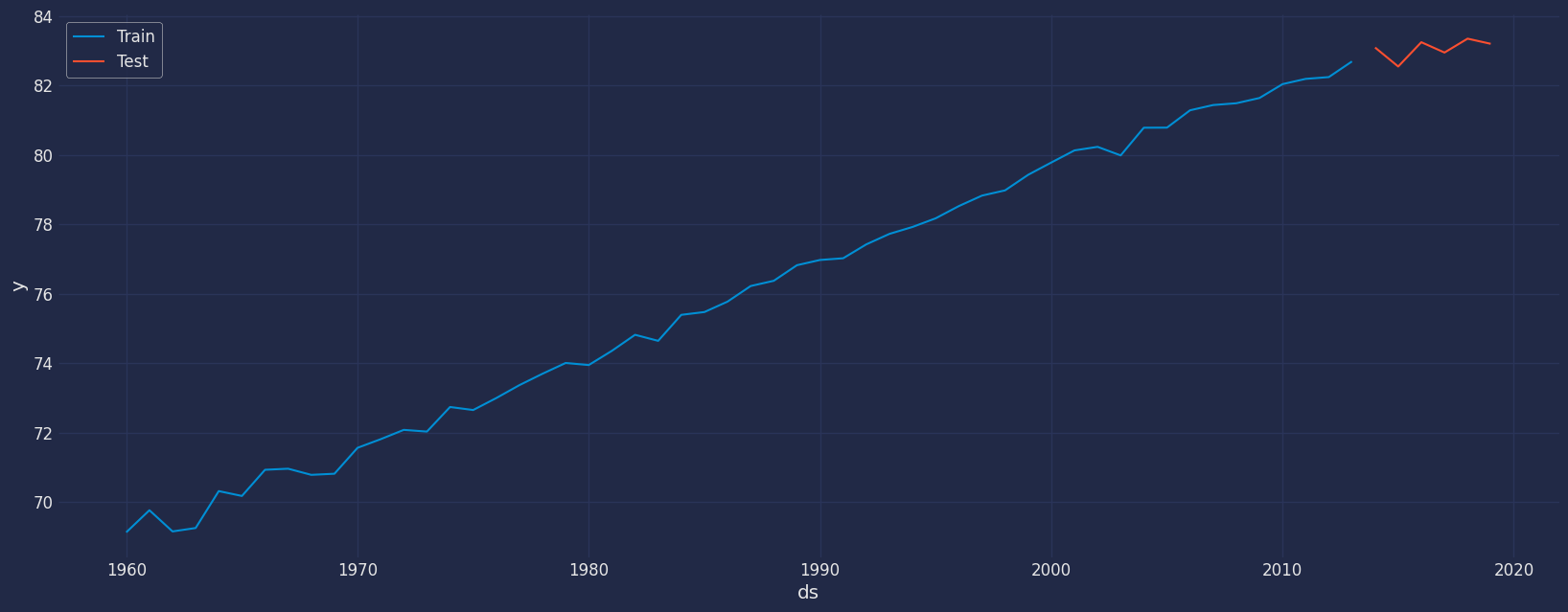
Split the data into training and testing
Let’s divide our data into sets- Data to train our model.
- Data to test our model.
Implementation of AutoCES with StatsForecast
Load libraries
Instantiate Model
Import and instantiate the models. Setting the argument is sometimes tricky. This article on Seasonal periods) by the master, Rob Hyndmann, can be usefulseason_length
Note
Automatically selects the best Complex Exponential Smoothing model
using an information criterion. Default is Akaike Information Criterion
(AICc), while particular models are estimated using maximum likelihood.
The state-space equations can be determined based on their simple,
parial, optimized or ommited components. The model string
parameter defines the kind of CES model: for simple CES (withous
seasonality), for simple seasonality (lagged CES), for partial
seasonality (without complex part), for full seasonality (lagged CES
with real and complex seasonal parts).
If the component is selected as , it operates as a placeholder to ask
the AutoCES model to figure out the best parameter.
-
freq:a string indicating the frequency of the data. (See pandas’ available frequencies.) -
n_jobs:n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model:a model to be used if a model fails.
Fit the Model
.get() function to extract the element and then we are going to save
it in a pd.DataFrame().
Forecast Method
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the .forecast doest not store the fitted
values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[90]means that the model expects the real value to be inside that interval 90% of the times.
ARIMA and Theta)
Predict method with confidence interval
To generate forecasts use the predict method. The predict method takes two arguments: forecasts the nexth (for
horizon) and level.
-
h (int):represents the forecast h steps into the future. In this case, 12 months ahead. -
level (list of floats):this optional parameter is used for probabilistic forecasting. Set the level (or confidence percentile) of your prediction interval. For example,level=[95]means that the model expects the real value to be inside that interval 95% of the times.
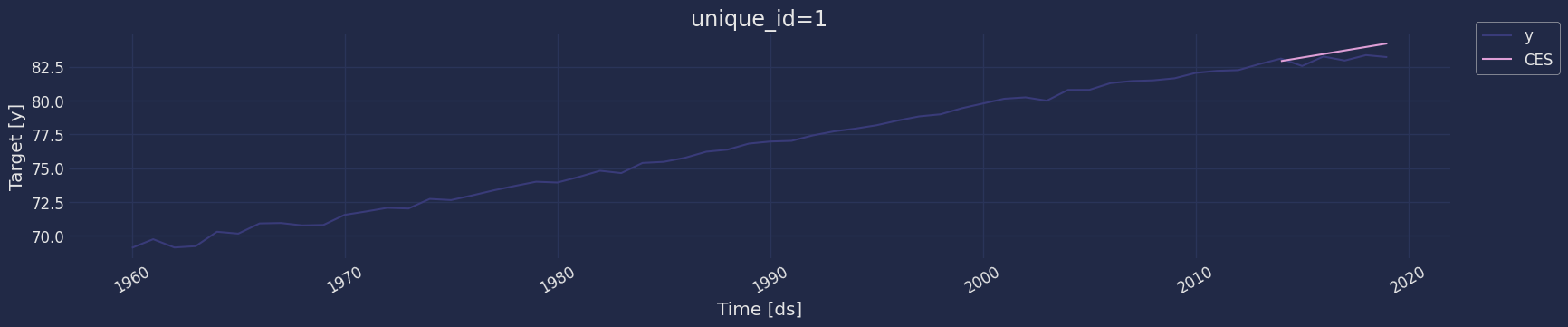
Now let’s visualize the result of our forecast and the historical data
of our time series, also let’s draw the confidence interval that we have
obtained when making the prediction with 95% confidence.

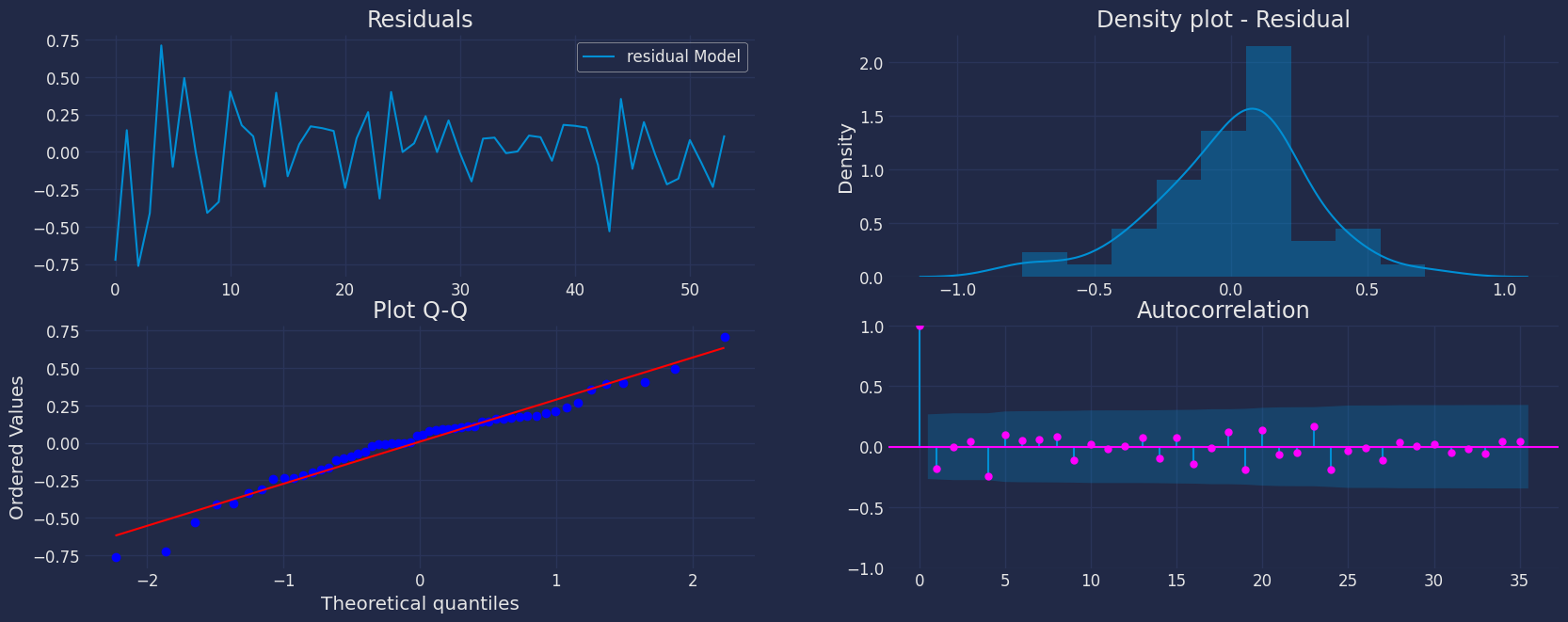
Cross-validation
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:
Perform time series cross-validation
Cross-validation of time series models is considered a best practice but most implementations are very slow. The statsforecast library implements cross-validation as a distributed operation, making the process less time-consuming to perform. If you have big datasets you can also perform Cross Validation in a distributed cluster using Ray, Dask or Spark. In this case, we want to evaluate the performance of each model for the last 5 months(n_windows=5), forecasting every second months
(step_size=12). Depending on your computer, this step should take
around 1 min.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df:training data frame -
h (int):represents h steps into the future that are being forecasted. In this case, 12 months ahead. -
step_size (int):step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int):number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_id:series identifierds:datestamp or temporal indexcutoff:the last datestamp or temporal index for the n_windows.y:true value"model":columns with the model’s name and fitted value.