Step-by-step guide on using theDuring this walkthrough, we will become familiar with the mainAutoETS ModelwithStatsforecast.
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation in other.
The text in this article is largely taken from Rob J. Hyndman and
George Athanasopoulos (2018). “Forecasting Principles and Practice (3rd
ed)”.
Table of Contents
- Introduction
- ETS Models
- ETS Estimation
- Model Selection
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of AutoETS with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
Automatic forecasts of large numbers of univariate time series are often needed in business. It is common to have over one thousand product lines that need forecasting at least monthly. Even when a smaller number of forecasts are required, there may be nobody suitably trained in the use of time series models to produce them. In these circumstances, an automatic forecasting algorithm is an essential tool. Automatic forecasting algorithms must determine an appropriate time series model, estimate the parameters and compute the forecasts. They must be robust to unusual time series patterns, and applicable to large numbers of series without user intervention. The most popular automatic forecasting algorithms are based on either exponential smoothing or ARIMA models.Exponential smoothing
Although exponential smoothing methods have been around since the 1950s, a modelling framework incorporating procedures for model selection was not developed until relatively recently.Ord, Koehler, and
Snyder (1997), Hyndman, Koehler, Snyder, and Grose (2002) and
Hyndman, Koehler, Ord, and Snyder (2005b) have shown that all
exponential smoothing methods (including non-linear methods) are optimal
forecasts from innovations state space models.
Exponential smoothing methods were originally classified by
Pegels’ (1969) taxonomy. This was later extended by
Gardner (1985), modified by Hyndman et al. (2002), and extended again
by Taylor (2003), giving a total of fifteen methods seen in the
following table.
Some of these methods are better known under other names. For example,
cell
(N,N) describes the simple exponential smoothing (or SES)
method, cell (A,N) describes Holt’s linear method, and cell
(Ad,N) describes the damped trend method. The additive
Holt-Winters’ method is given by cell (A,A) and the multiplicative
Holt-Winters’ method is given by cell (A,M). The other cells
correspond to less commonly used but analogous methods.
Point forecasts for all methods
We denote the observed time series by . A forecast of based on all of the data up to time is denoted by . To illustrate the method, we give the point forecasts and updating equation for method(A,A), the he Holt-Winters’ additive
method:
where is the length of seasonality (e.g., the number of months or
quarters in a year), represents the level of the series,
denotes the growth, is the seasonal component,
is the forecast for periods ahead, and
. To use method (1), we need values
for the initial states , and , and
for the smoothing parameters and . All of
these will be estimated from the observed data.
Equation (1c) is slightly different from the usual Holt-Winters
equations such as those in Makridakis et al. (1998) or Bowerman,
O’Connell, and Koehler (2005). These authors replace (1c) with
If is substituted using (1a), we obtain
Thus, we obtain identical forecasts using this approach by replacing
in (1c) with . The modification given in
(1c) was proposed by Ord et al. (1997) to make the state space
formulation simpler. It is equivalent to Archibald’s (1990) variation of
the Holt-Winters’ method.
Innovations state space models
For each exponential smoothing method in Other ETS models , Hyndman et al. (2008b) describe two possible innovations state space models, one corresponding to a model with additive errors and the other to a model with multiplicative errors. If the same parameter values are used, these two models give equivalent point forecasts, although different prediction intervals. Thus there are 30 potential models described in this classification. Historically, the nature of the error component has often been ignored, because the distinction between additive and multiplicative errors makes no difference to point forecasts. We are careful to distinguish exponential smoothing methods from the underlying state space models. An exponential smoothing method is an algorithm for producing point forecasts only. The underlying stochastic state space model gives the same point forecasts, but also provides a framework for computing prediction intervals and other properties. To distinguish the models with additive and multiplicative errors, we add an extra letter to the front of the method notation. The triplet(E,T,S) refers to the three components: error, trend and seasonality.
So the model ETS(A,A,N) has additive errors, additive trend and no
seasonality—in other words, this is Holt’s linear method with additive
errors. Similarly, ETS(M,Md,M) refers to a model with multiplicative
errors, a damped multiplicative trend and multiplicative seasonality.
The notation ETS(·,·,·) helps in remembering the order in which the
components are specified.
Once a model is specified, we can study the probability distribution of
future values of the series and find, for example, the conditional mean
of a future observation given knowledge of the past. We denote this as
, where xt contains the unobserved
components such as , and . For we use
as a shorthand notation. For many models, these
conditional means will be identical to the point forecasts given in
Table Other ETS models, so that
. However, for other models (those with
multiplicative trend or multiplicative seasonality), the conditional
mean and the point forecast will differ slightly for .
We illustrate these ideas using the damped trend method of Gardner and
McKenzie (1985).
Each model consists of a measurement equation that describes the
observed data, and some state equations that describe how the unobserved
components or states (level, trend, seasonal) change over time. Hence,
these are referred to as state space models.
For each method there exist two models: one with additive errors and one
with multiplicative errors. The point forecasts produced by the models
are identical if they use the same smoothing parameter values. They
will, however, generate different prediction intervals.
To distinguish between a model with additive errors and one with
multiplicative errors (and also to distinguish the models from the
methods), we add a third letter to the classification of in the above
Table. We label each state space model as ETS(⋅,.,.) for (Error,
Trend, Seasonal). This label can also be thought of as ExponenTial
Smoothing. Using the same notation as in the above Table, the
possibilities for each component (or state) are: Error ={ A,M },
Trend ={N,A,Ad} and Seasonal ={ N,A,M }.
ETS(A,N,N): simple exponential smoothing with additive errors
Recall the component form of simple exponential smoothing: If we re-arrange the smoothing equation for the level, we get the “error correction” form, where s the residual at time . The training data errors lead to the adjustment of the estimated level throughout the smoothing process for . For example, if the error at time is negative, then and so the level at time has been over-estimated. The new level is then the previous level adjusted downwards. The closer is to one, the “rougher” the estimate of the level (large adjustments take place). The smaller the , the “smoother” the level (small adjustments take place). We can also write , so that each observation can be represented by the previous level plus an error. To make this into an innovations state space model, all we need to do is specify the probability distribution for . For a model with additive errors, we assume that residuals (the one-step training errors) are normally distributed white noise with mean 0 and variance . A short-hand notation for this is ; NID stands for “normally and independently distributed”. Then the equations of the model can be written as We refer to (2) as the measurement (or observation) equation and (3) as the state (or transition) equation. These two equations, together with the statistical distribution of the errors, form a fully specified statistical model. Specifically, these constitute an innovations state space model underlying simple exponential smoothing. The term “innovations” comes from the fact that all equations use the same random error process, . For the same reason, this formulation is also referred to as a “single source of error” model. There are alternative multiple source of error formulations which we do not present here. The measurement equation shows the relationship between the observations and the unobserved states. In this case, observation is a linear function of the level , the predictable part of , and the error , the unpredictable part of . For other innovations state space models, this relationship may be nonlinear. The state equation shows the evolution of the state through time. The influence of the smoothing parameter is the same as for the methods discussed earlier. For example, governs the amount of change in successive levels: high values of allow rapid changes in the level; low values of lead to smooth changes. If , the level of the series does not change over time; if , the model reduces to a random walk model, .ETS(M,N,N): simple exponential smoothing with multiplicative errors
In a similar fashion, we can specify models with multiplicative errors by writing the one-step-ahead training errors as relative errors where . Substituting gives and . Then we can write the multiplicative form of the state space model asETS(A,A,N): Holt’s linear method with additive errors
For this model, we assume that the one-step-ahead training errors are given by Substituting this into the error correction equations for Holt’s linear method we obtain where for simplicity we have set .ETS(M,A,N): Holt’s linear method with multiplicative errors
Specifying one-step-ahead training errors as relative errors such that and following an approach similar to that used above, the innovations state space model underlying Holt’s linear method with multiplicative errors is specified as where again and .Estimating ETS models
An alternative to estimating the parameters by minimising the sum of squared errors is to maximise the “likelihood”. The likelihood is the probability of the data arising from the specified model. Thus, a large likelihood is associated with a good model. For an additive error model, maximising the likelihood (assuming normally distributed errors) gives the same results as minimising the sum of squared errors. However, different results will be obtained for multiplicative error models. In this section, we will estimate the smoothing parameters and and the initial states , by maximising the likelihood. The possible values that the smoothing parameters can take are restricted. Traditionally, the parameters have been constrained to lie between 0 and 1 so that the equations can be interpreted as weighted averages. That is, . For the state space models, we have set and . Therefore, the traditional restrictions translate to and . In practice, the damping parameter is usually constrained further to prevent numerical difficulties in estimating the model. Another way to view the parameters is through a consideration of the mathematical properties of the state space models. The parameters are constrained in order to prevent observations in the distant past having a continuing effect on current forecasts. This leads to some admissibility constraints on the parameters, which are usually (but not always) less restrictive than the traditional constraints region(Hyndman et al., 2008, pp. 149-161). For example, for the ETS(A,N,N)
model, the traditional parameter region is but the
admissible region is . For the ETS(A,A,N) model, the
traditional parameter region is and but
the admissible region is and .
Model selection
A great advantage of theETS statistical framework is that information
criteria can be used for model selection. The AIC, AIC_c and BIC,
can be used here to determine which of the ETS models is most
appropriate for a given time series.
For ETS models, Akaike’s Information Criterion (AIC) is defined as
where is the likelihood of the model and is the total number of
parameters and initial states that have been estimated (including the
residual variance).
The AIC corrected for small sample bias (AIC_c) is defined as
and the Bayesian Information Criterion (BIC) is
Three of the combinations of (Error, Trend, Seasonal) can lead to
numerical difficulties. Specifically, the models that can cause such
instabilities are ETS(A,N,M), ETS(A,A,M), and ETS(A,Ad,M), due to
division by values potentially close to zero in the state equations. We
normally do not consider these particular combinations when selecting a
model.
Models with multiplicative errors are useful when the data are strictly
positive, but are not numerically stable when the data contain zeros or
negative values. Therefore, multiplicative error models will not be
considered if the time series is not strictly positive. In that case,
only the six fully additive models will be applied.
Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
Read Data
The input to StatsForecast is always a data frame in long format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
ds from object type to datetime.
Explore data with the plot method
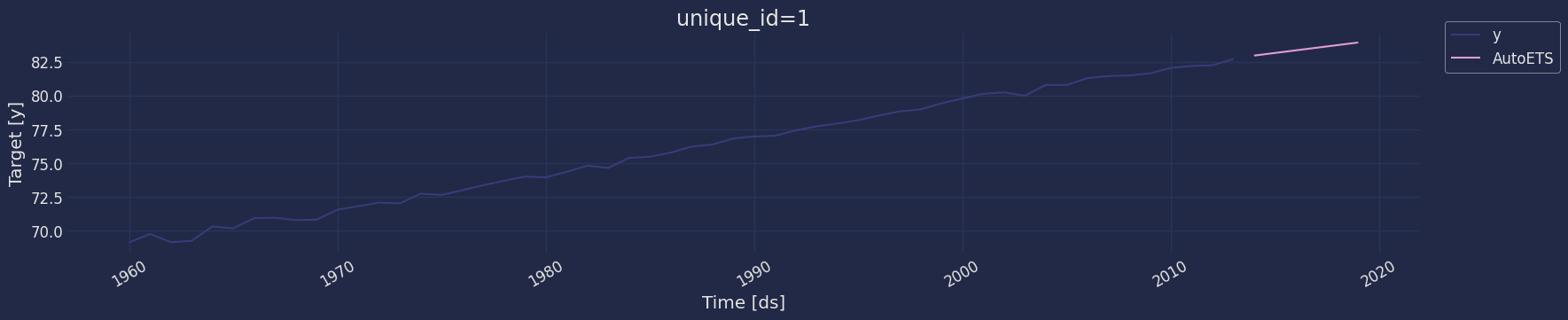
Plot some series using the plot method from the StatsForecast class. This method prints a random series from the dataset and is useful for basic EDA.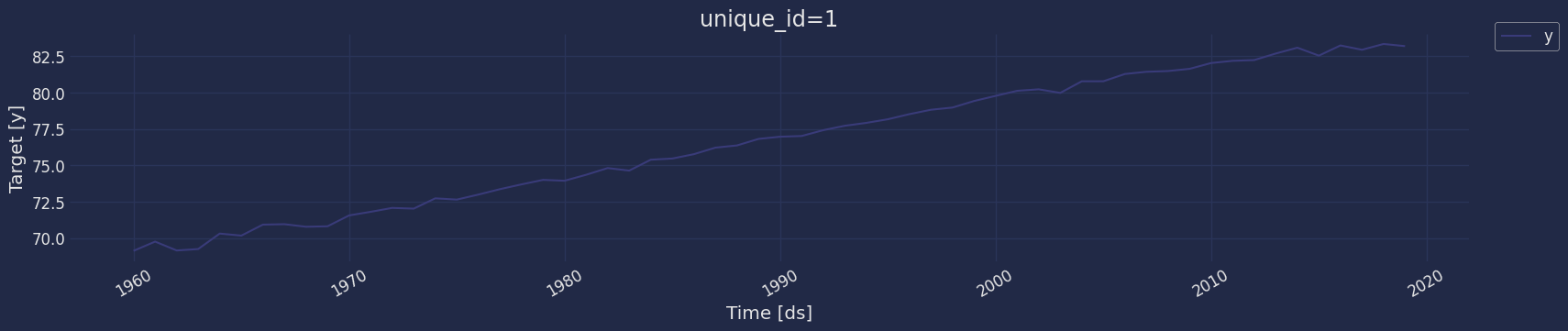
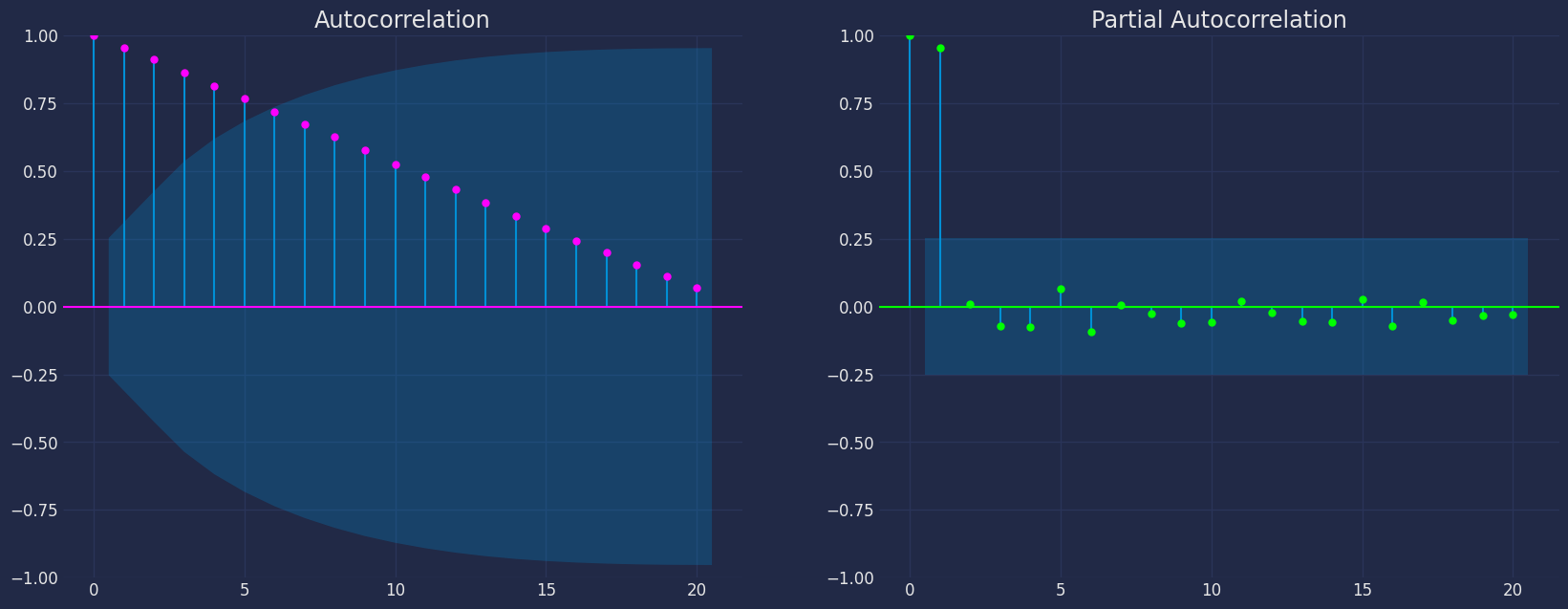
Autocorrelation plots
Decomposition of the time series
How to decompose a time series and why? In time series analysis to forecast new values, it is very important to know past data. More formally, we can say that it is very important to know the patterns that values follow over time. There can be many reasons that cause our forecast values to fall in the wrong direction. Basically, a time series consists of four components. The variation of those components causes the change in the pattern of the time series. These components are:- Level: This is the primary value that averages over time.
- Trend: The trend is the value that causes increasing or decreasing patterns in a time series.
- Seasonality: This is a cyclical event that occurs in a time series for a short time and causes short-term increasing or decreasing patterns in a time series.
- Residual/Noise: These are the random variations in the time series.
Additive time series
If the components of the time series are added to make the time series. Then the time series is called the additive time series. By visualization, we can say that the time series is additive if the increasing or decreasing pattern of the time series is similar throughout the series. The mathematical function of any additive time series can be represented by:Multiplicative time series
If the components of the time series are multiplicative together, then the time series is called a multiplicative time series. For visualization, if the time series is having exponential growth or decline with time, then the time series can be considered as the multiplicative time series. The mathematical function of the multiplicative time series can be represented as.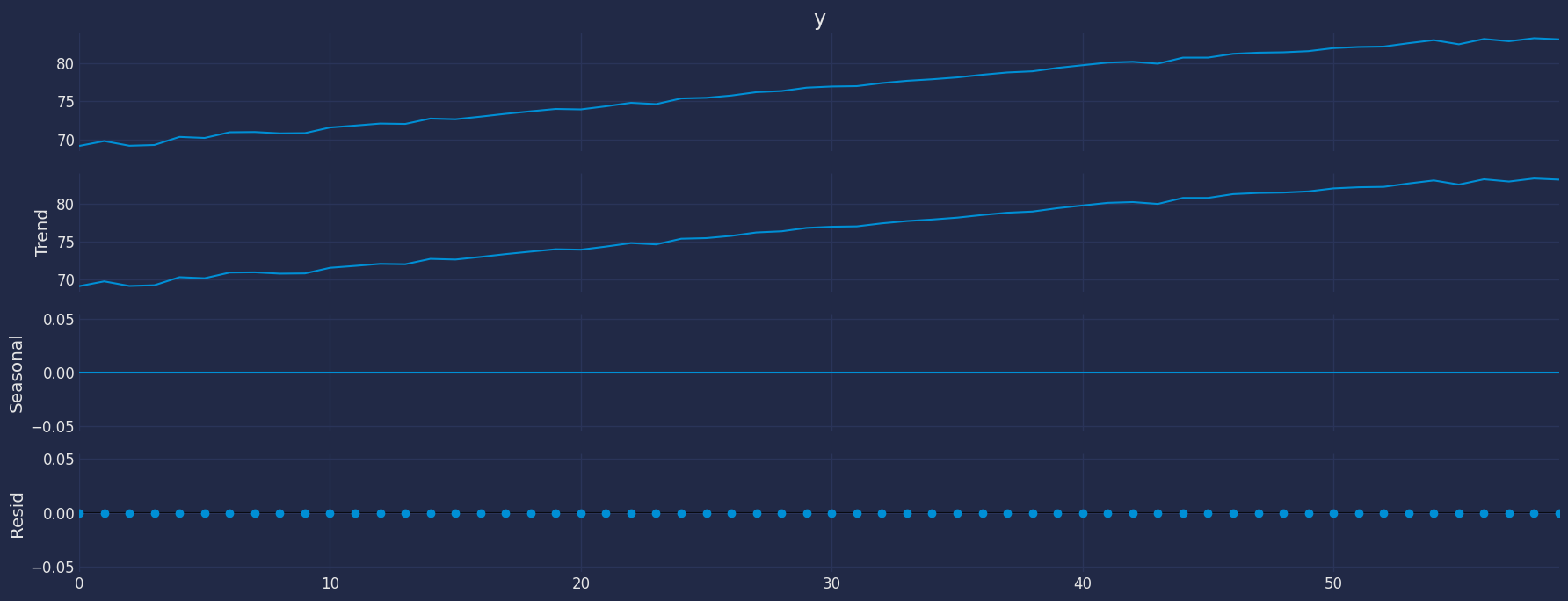
Split the data into training and testing
Let’s divide our data into sets- Data to train our model.
- Data to test our model.
Implementation of AutoETS with StatsForecast
Instantiate Model
Fit the Model
Model Prediction