Model training, evaluation and selection for multiple time series
Introducing Polars: A High-Performance DataFrame Library
This document aims to highlight the recent integration of Polars, a robust and high-speed DataFrame library developed in Rust, into the functionality of StatsForecast. Polars, with its nimble and potent capabilities, has rapidly established a strong reputation within the Data Science community, further solidifying its position as a reliable tool for managing and manipulating substantial data sets. Available in languages including Rust, Python, Node.js, and R, Polars demonstrates a remarkable ability to handle sizable data sets with efficiency and speed that surpasses many other DataFrame libraries, such as Pandas. Polars’ open-source nature invites ongoing enhancements and contributions, augmenting its appeal within the data science arena. The most significant features of Polars that contribute to its rapid adoption are:- Performance Efficiency: Constructed using Rust, Polars exhibits an exemplary ability to manage substantial datasets with remarkable speed and minimal memory usage.
- Lazy Evaluation: Polars operates on the principle of ‘lazy evaluation’, creating an optimized logical plan of operations for efficient execution, a feature that mirrors the functionality of Apache Spark.
- Parallel Execution: Demonstrating the capability to exploit multi-core CPUs, Polars facilitates parallel execution of operations, substantially accelerating data processing tasks.
Prerequisites This Guide assumes basic familiarity with StatsForecast. For a minimal example visit the Quick StartFollow this article for a step-by-step guide on building a production-ready forecasting pipeline for multiple time series. During this guide you will gain familiarity with the core
StatsForecastclass and some relevant methods like
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation.
We will use a classical benchmarking dataset from the M4 competition.
The dataset includes time series from different domains like finance,
economy and sales. In this example, we will use a subset of the Hourly
dataset.
We will model each time series individually. Forecasting at this level
is also known as local forecasting. Therefore, you will train a series
of models for every unique series and then select the best one.
StatsForecast focuses on speed, simplicity, and scalability, which makes
it ideal for this task.
Outline:
- Install packages.
- Read the data.
- Explore the data.
- Train many models for every unique combination of time series.
- Evaluate the model’s performance using cross-validation.
- Select the best model for every unique time series.
Not Covered in this guide
- Forecasting at scale using clusters on the cloud.
- Forecast the M5 Dataset in 5min using Ray clusters.
- Forecast the M5 Dataset in 5min using Spark clusters.
- Learn how to predict 1M series in less than 30min.
- Training models on Multiple Seasonalities.
- Learn to use multiple seasonality in this Electricity Load forecasting tutorial.
- Using external regressors or exogenous variables
- Follow this tutorial to include exogenous variables like weather or holidays or static variables like category or family.
- Comparing StatsForecast with other popular libraries.
- You can reproduce our benchmarks here.
Install libraries
We assume you have StatsForecast already installed. Check this guide for instructions on how to install StatsForecast.Read the data
We will use polars to read the M4 Hourly data set stored in a parquet file for efficiency. You can use ordinary polars operations to read your data in other formats likes.csv.
The input to StatsForecast is always a data frame in long
format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp or int) column should be either an integer indexing time or a datestamp ideally like YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
This dataset contains 414 unique series with 900 observations on
average. For this example and reproducibility’s sake, we will select
only 10 unique IDs and keep only the last week. Depending on your
processing infrastructure feel free to select more or less series.
Note Processing time is dependent on the available computing resources. Running this example with the complete dataset takes around 10 minutes in a c5d.24xlarge (96 cores) instance from AWS.
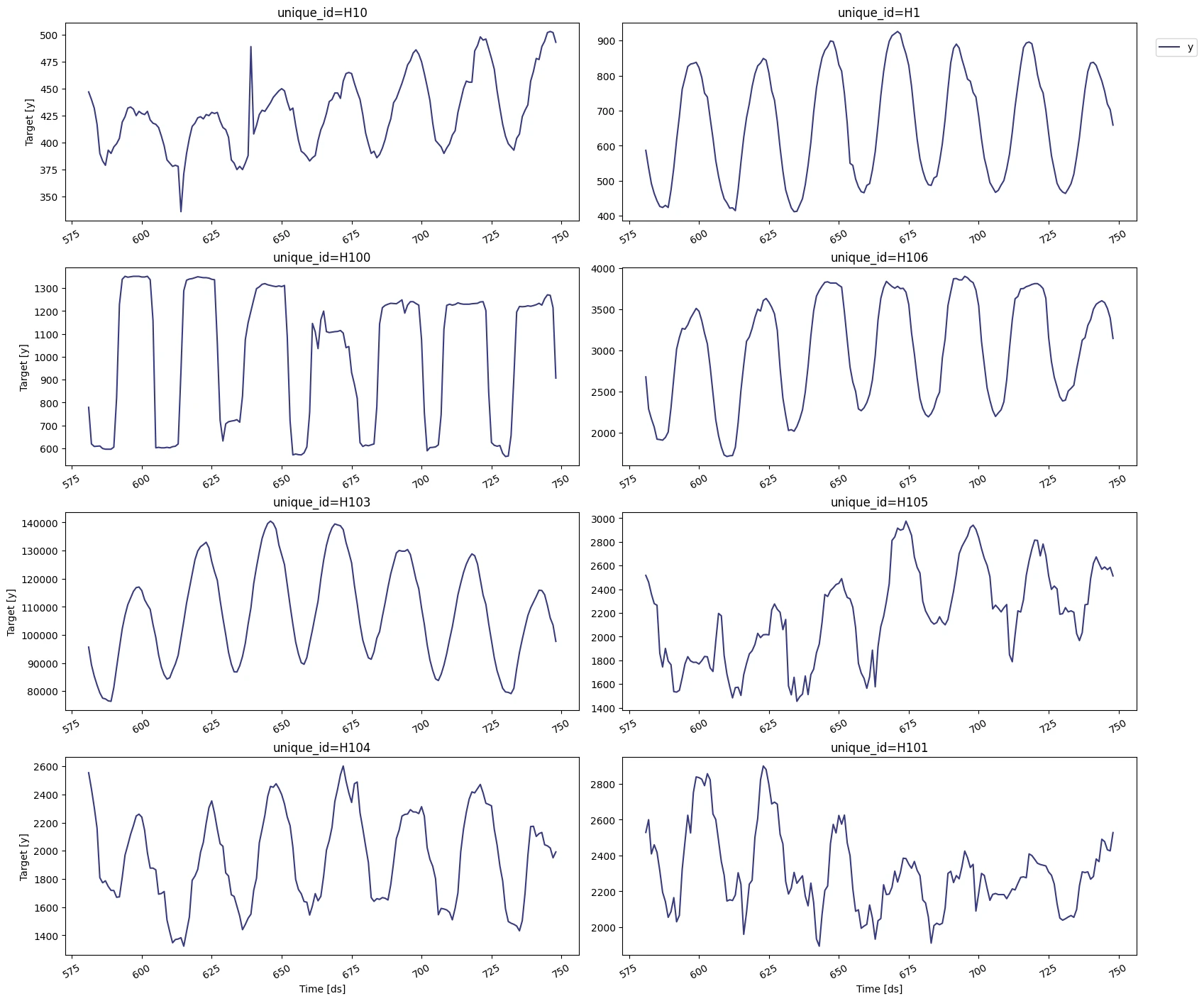
Explore Data with the plot method
Plot some series using theplot method from the StatsForecast class.
This method prints 8 random series from the dataset and is useful for
basic EDA.
Note TheStatsForecast.plotmethod uses matplotlib as a default engine. You can change to plotly by settingengine="plotly".
Train multiple models for many series
StatsForecast can train many models on many time series efficiently. Start by importing and instantiating the desired models. StatsForecast offers a wide variety of models grouped in the following categories:- Auto Forecast: Automatic forecasting tools search for the best parameters and select the best possible model for a series of time series. These tools are useful for large collections of univariate time series. Includes automatic versions of: Arima, ETS, Theta, CES.
- Exponential Smoothing: Uses a weighted average of all past observations where the weights decrease exponentially into the past. Suitable for data with no clear trend or seasonality. Examples: SES, Holt’s Winters, SSO.
- Benchmark models: classical models for establishing baselines. Examples: Mean, Naive, Random Walk
- Intermittent or Sparse models: suited for series with very few non-zero observations. Examples: CROSTON, ADIDA, IMAPA
- Multiple Seasonalities: suited for signals with more than one clear seasonality. Useful for low-frequency data like electricity and logs. Examples: MSTL.
- Theta Models: fit two theta lines to a deseasonalized time series, using different techniques to obtain and combine the two theta lines to produce the final forecasts. Examples: Theta, DynamicTheta
-
AutoARIMA: Automatically selects the best ARIMA (AutoRegressive Integrated Moving Average) model using an information criterion. Ref:AutoARIMA. -
HoltWinters: triple exponential smoothing, Holt-Winters’ method is an extension of exponential smoothing for series that contain both trend and seasonality. Ref:HoltWinters -
SeasonalNaive: Memory Efficient Seasonal Naive predictions. Ref:SeasonalNaive -
HistoricAverage: arithmetic mean. Ref:HistoricAverage. -
DynamicOptimizedTheta: The theta family of models has been shown to perform well in various datasets such as M3. Models the deseasonalized time series. Ref:DynamicOptimizedTheta.
season_length argument
is sometimes tricky. This article on Seasonal
periods) by the
master, Rob Hyndmann, can be useful.
StatsForecast object with the
following parameters:
-
models: a list of models. Select the models you want from models and import them. -
freq: a string indicating the frequency of the data. (See panda’s available frequencies.) This is also available with Polars. -
n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model: a model to be used if a model fails.
forecast method takes two arguments: forecasts next h (horizon)
and level.
-
h(int): represents the forecast h steps into the future. In this case, 12 months ahead. -
level(list of floats): this optional parameter is used for probabilistic forecasting. Set thelevel(or confidence percentile) of your prediction interval. For example,level=[90]means that the model expects the real value to be inside that interval 90% of the times.
Note Theforecastmethod is compatible with distributed clusters, so it does not store any model parameters. If you want to store parameters for every model you can use thefitandpredictmethods. However, those methods are not defined for distributed engines like Spark, Ray or Dask.
Plot the results of 8 random series using the
StatsForecast.plot
method.
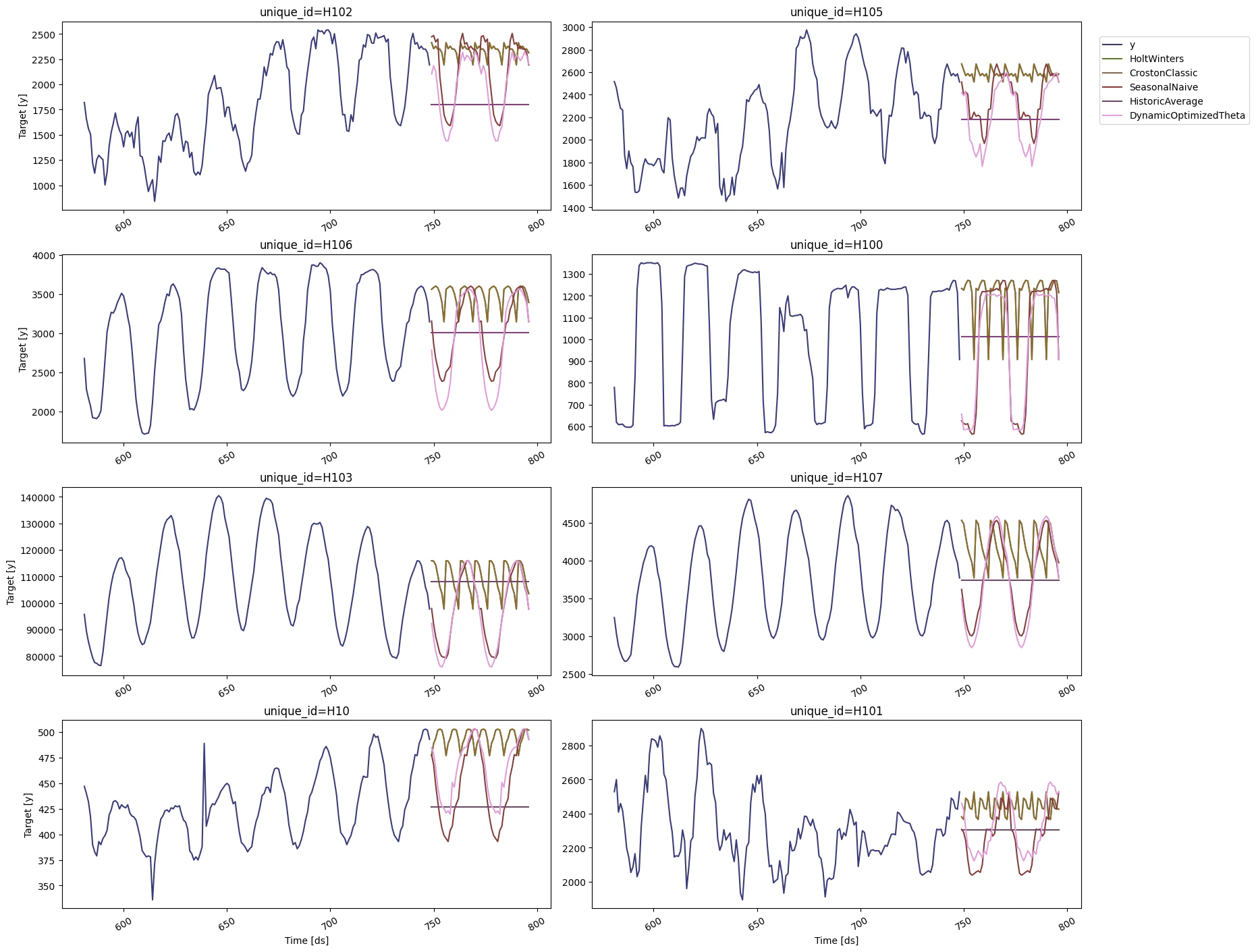
StatsForecast.plot allows for further customization. For example,
plot the results of the different models and unique ids.


Evaluate the model’s performance
In previous steps, we’ve taken our historical data to predict the future. However, to assess its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy: Cross-validation of time series models is considered a best practice but
most implementations are very slow. The statsforecast library implements
cross-validation as a distributed operation, making the process less
time-consuming to perform. If you have big datasets you can also perform
Cross Validation in a distributed cluster using Ray, Dask or Spark.
In this case, we want to evaluate the performance of each model for the
last 2 days (n_windows=2), forecasting every second day (step_size=48).
Depending on your computer, this step should take around 1 min.
Cross-validation of time series models is considered a best practice but
most implementations are very slow. The statsforecast library implements
cross-validation as a distributed operation, making the process less
time-consuming to perform. If you have big datasets you can also perform
Cross Validation in a distributed cluster using Ray, Dask or Spark.
In this case, we want to evaluate the performance of each model for the
last 2 days (n_windows=2), forecasting every second day (step_size=48).
Depending on your computer, this step should take around 1 min.
Tip
Setting n_windows=1 mirrors a traditional train-test split with our
historical data serving as the training set and the last 48 hours
serving as the testing set.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df: training data frame -
h(int): represents h steps into the future that are being forecasted. In this case, 24 hours ahead. -
step_size(int): step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int): number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
cv_df object is a new data frame that includes the following
columns:
-
unique_id: series identifier -
ds: datestamp or temporal index -
cutoff: the last datestamp or temporal index for then_windows.Ifn_windows=1, then one unique cutoff value, ifn_windows=2then two unique cutoff values. -
y: true value -
"model": columns with the model’s name and fitted value.
Next, we will evaluate the performance of every model for every series
using common error metrics like Mean Absolute Error (MAE) or Mean Square
Error (MSE) Define a utility function to evaluate different error
metrics for the cross validation data frame.
First import the desired error metrics from
utilsforecast.losses. Then
define a utility function that takes a cross-validation data frame as a
metric and returns an evaluation data frame with the average of the
error metric for every unique id and fitted model and all cutoffs.
Warning You can also use Mean Average Percentage Error (MAPE), however for granular forecasts, MAPE values are extremely hard to judge and not useful to assess forecasting quality.Create the data frame with the results of the evaluation of your cross-validation data frame using a Mean Squared Error metric.
Create a summary table with a model column and the number of series
where that model performs best. In this case, the Arima and Seasonal
Naive are the best models for 10 series and the Theta model should be
used for two.
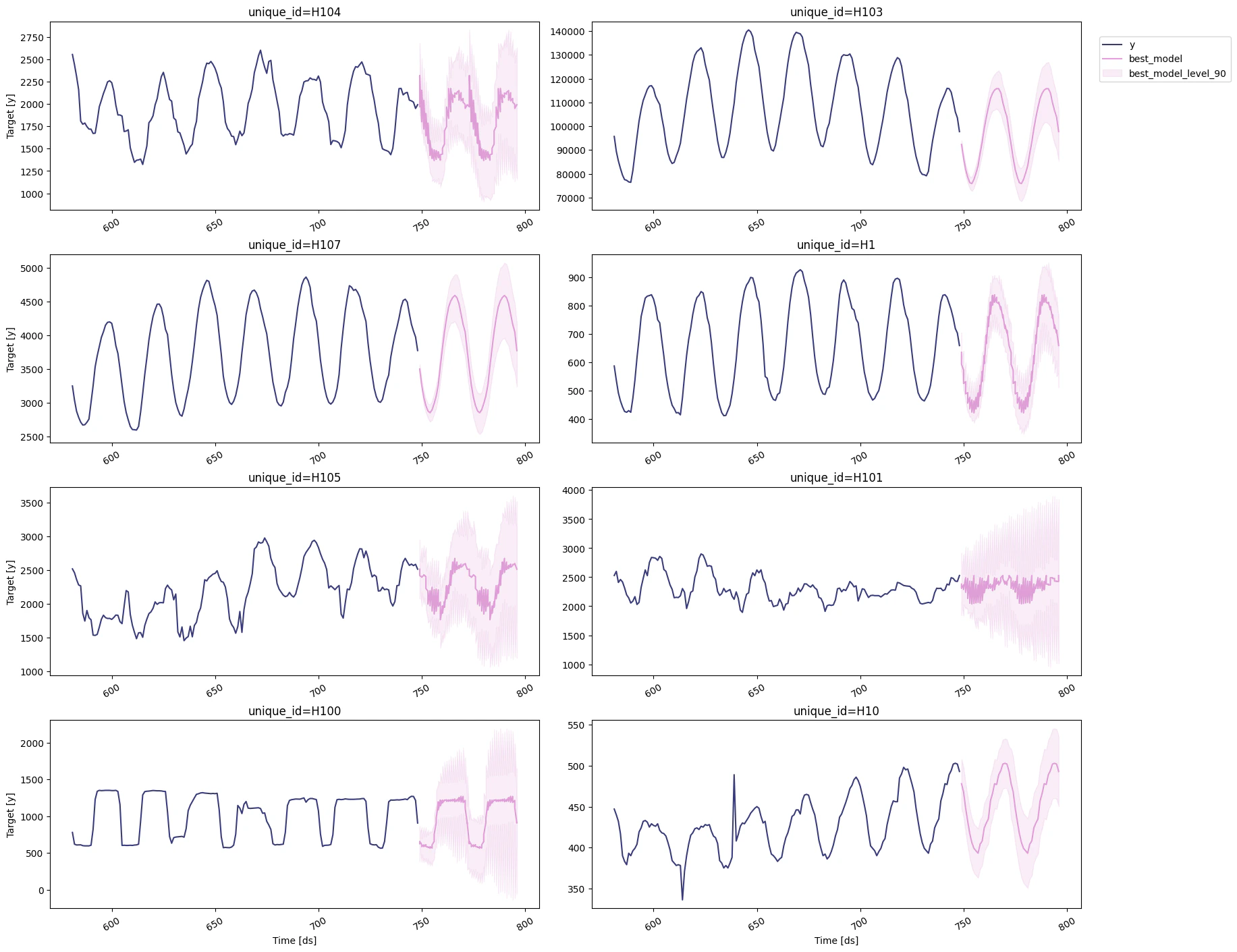
You can further explore your results by plotting the unique_ids where a
specific model wins.
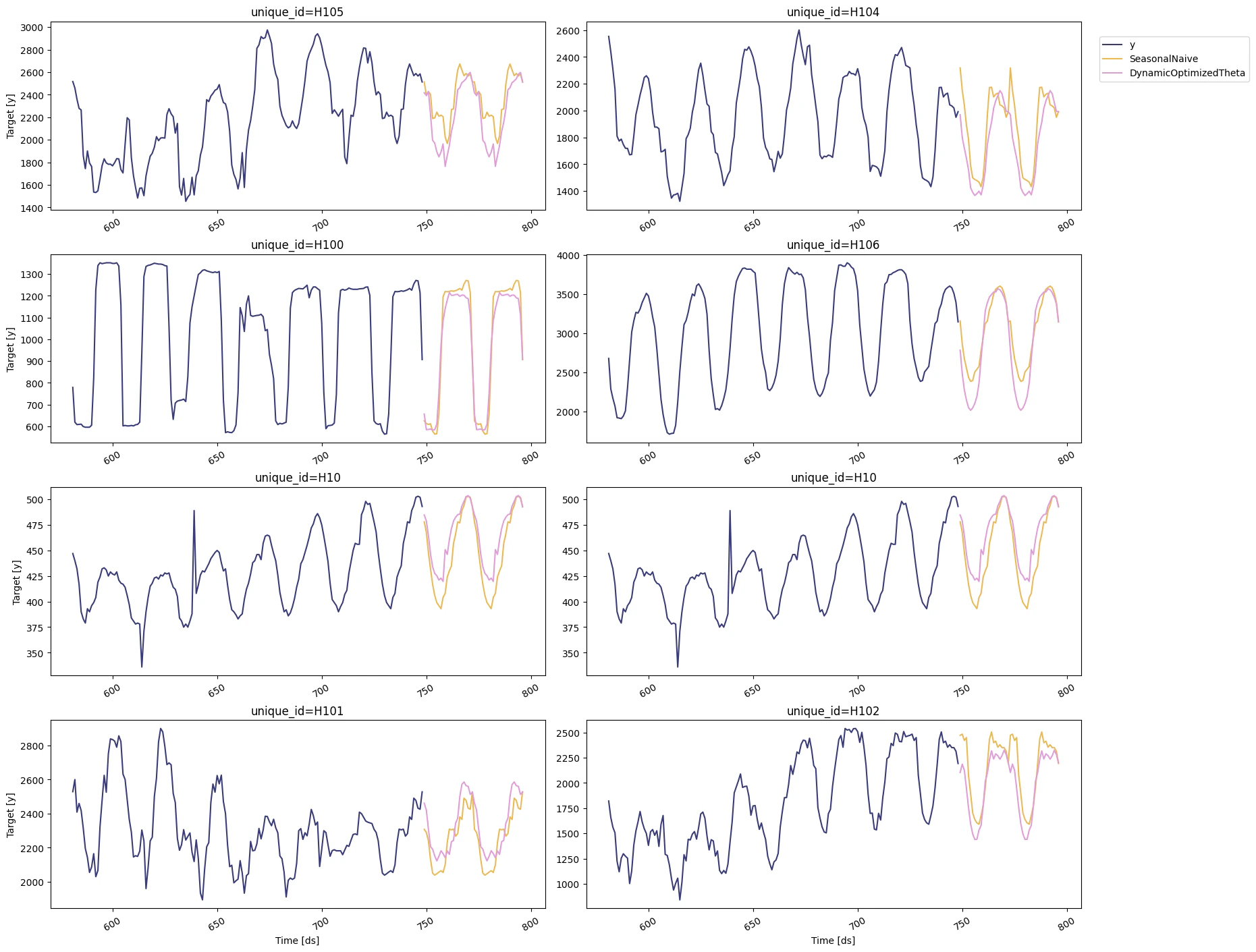
Select the best model for every unique series
Define a utility function that takes your forecast’s data frame with the predictions and the evaluation data frame and returns a data frame with the best possible forecast for every unique_id.
Plot the results.