

Step-by-step guide on using theIn this walkthrough, we will become familiar with the mainADIDA ModelwithStatsforecast.
StatsForecast class and some relevant methods such as
StatsForecast.plot, StatsForecast.forecast and
StatsForecast.cross_validation.
The text in this article is largely taken from: 1. Changquan Huang •
Alla Petukhina. Springer series (2022). Applied Time Series Analysis and
Forecasting with
Python. 2.
Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic
Adaptive Model (ADAM) 3. James D.
Hamilton. Time Series Analysis Princeton University Press, Princeton,
New Jersey, 1st Edition,
1994.
Table of Contents
- Introduction
- ADIDA Model
- Loading libraries and data
- Explore data with the plot method
- Split the data into training and testing
- Implementation of ADIDA with StatsForecast
- Cross-validation
- Model evaluation
- References
Introduction
The Aggregate-Disaggregate Intermittent Demand Approach (ADIDA) is a forecasting method that is used to predict the demand for products that exhibit intermittent demand patterns. Intermittent demand patterns are characterized by a large number of zero observations, which can make forecasting challenging. The ADIDA method uses temporal aggregation to reduce the number of zero observations and mitigate the effect of the variance observed in the intervals. The method uses equally sized time buckets to perform non-overlapping temporal aggregation and predict the demand over a pre-specified lead time. The time bucket is set equal to the mean inter-demand interval, which is the average time between two consecutive non-zero observations. The method uses the Simple Exponential Smoothing (SES) technique to obtain the forecasts. SES is a popular time series forecasting technique that is commonly used for its simplicity and effectiveness in producing accurate forecasts. The ADIDA method has several advantages. It is easy to implement and can be used for a wide range of intermittent demand patterns. The method also provides accurate forecasts and can be used to predict the demand over a pre-specified lead time. However, the ADIDA method has some limitations. The method assumes that the time buckets are equally sized, which may not be the case for all intermittent demand patterns. Additionally, the method may not be suitable for time series data with complex patterns or trends. Overall, the ADIDA method is a useful forecasting technique for intermittent demand patterns that can help mitigate the effect of zero observations and produce accurate demand forecasts.ADIDA Model
What is intermittent demand?
Intermittent demand is a demand pattern characterized by the irregular and sporadic occurrence of events or sales. In other words, it refers to situations in which the demand for a product or service occurs intermittently, with periods of time in which there are no sales or significant events. Intermittent demand differs from constant or regular demand, where sales occur in a predictable and consistent manner over time. In contrast, in intermittent demand, periods without sales may be long and there may not be a regular sequence of events. This type of demand can occur in different industries and contexts, such as low consumption products, seasonal products, high variability products, products with short life cycles, or in situations where demand depends on specific events or external factors. Intermittent demand can pose challenges in forecasting and inventory management, as it is difficult to predict when sales will occur and in what quantity. Methods like the Croston model, which I mentioned earlier, are used to address intermittent demand and generate more accurate and appropriate forecasts for this type of demand pattern.Problem with intermittent demand
Intermittent demand can present various challenges and issues in inventory management and demand forecasting. Some of the common problems associated with intermittent demand are as follows:- Unpredictable variability: Intermittent demand can have unpredictable variability, making planning and forecasting difficult. Demand patterns can be irregular and fluctuate dramatically between periods with sales and periods without sales.
- Low frequency of sales: Intermittent demand is characterized by long periods without sales. This can lead to inventory management difficulties, as it is necessary to hold enough stock to meet demand when it occurs, while avoiding excess inventory during non-sales periods.
- Forecast error: Forecasting intermittent demand can be more difficult to pin down than constant demand. Traditional forecast models may not be adequate to capture the variability and lack of patterns in intermittent demand, which can lead to significant errors in estimates of future demand.
- Impact on the supply chain: Intermittent demand can affect the efficiency of the supply chain and create difficulties in production planning, supplier management and logistics. Lead times and inventory levels must be adjusted to meet unpredictable demand.
- Operating costs: Managing inventory in situations of intermittent demand can increase operating costs. Maintaining adequate inventory during non-sales periods and managing stock levels may require additional investments in storage and logistics.
ADIDA Model
The ADIDA model is based on the Simple Exponential Smoothing (SES) method and uses temporal aggregation to handle the problem of intermittent demand. The mathematical development of the model can be summarized as follows: Let St be the demand at time , where . The mean inter-demand interval is denoted as MI, which is the average time between two consecutive non-zero demands. The time bucket size is set equal to MI. The demand data is then aggregated into non-overlapping time buckets of size MI. Let Bt be the demand in bucket , where . The aggregated demand data can be represented as: The SES method is then applied to the aggregated demand data to obtain the forecasts. The forecast for bucket is denoted as . The SES method involves estimating the level at time t based on the actual demand at time t and the estimated level at the previous time period, , using the following equation: where is the smoothing parameter that controls the weight given to the current demand value. The forecast for bucket is then obtained by using the estimated level at the previous time period, , as follows: The forecasts are then disaggregated to obtain the demand predictions for the original time period. Let be the demand prediction at time . The disaggregation can be performed using the following equation:How can you determine if the ADIDA model is suitable for a specific data set?
To determine if the ADIDA model is suitable for a specific data set, the following steps can be followed:- Analyze the demand pattern: Examine the demand pattern of the data to determine if it fits an intermittent pattern. Intermittent data is characterized by a high proportion of zeros and sporadic demands in specific periods.
- Evaluate seasonality: Check if there is a clear seasonality in the data. The ADIDA model assumes that there is no seasonality or that it can be handled by temporal aggregation. If the data show complex seasonality or cannot be handled by temporal aggregation, the ADIDA model may not be suitable.
- Data requirements: Consider the data requirements of the ADIDA model. The model requires historical demand data and the ability to calculate the mean interval between non-zero demands. Make sure you have enough data to estimate the parameters and that the data is available at a frequency suitable for temporal aggregation.
- Performance evaluation: Perform a performance evaluation of the ADIDA model on the specific data set. Compare model-generated forecasts with actual demand values and use evaluation metrics such as mean absolute error (MAE) or mean square error (MSE). If the model performs well and produces accurate forecasts on the data set, this is an indication that it is suitable for that data set.
- Comparison with other models: Compare the performance of the ADIDA model with other forecast models suitable for intermittent data. Consider models like Croston, Syntetos-Boylan Approximation (SBA), or models based on exponential smoothing techniques that have been developed specifically for intermittent data. If the ADIDA model shows similar or better performance than other models, it can be considered suitable.
Loading libraries and data
Tip Statsforecast will be needed. To install, see instructions.Next, we import plotting libraries and configure the plotting style.
The input to StatsForecast is always a data frame in long format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
object types to datetime and numeric.
Explore data with the plot method
Plot a series using the plot method from the StatsForecast class. This method prints a random series from the dataset and is useful for basic EDA.
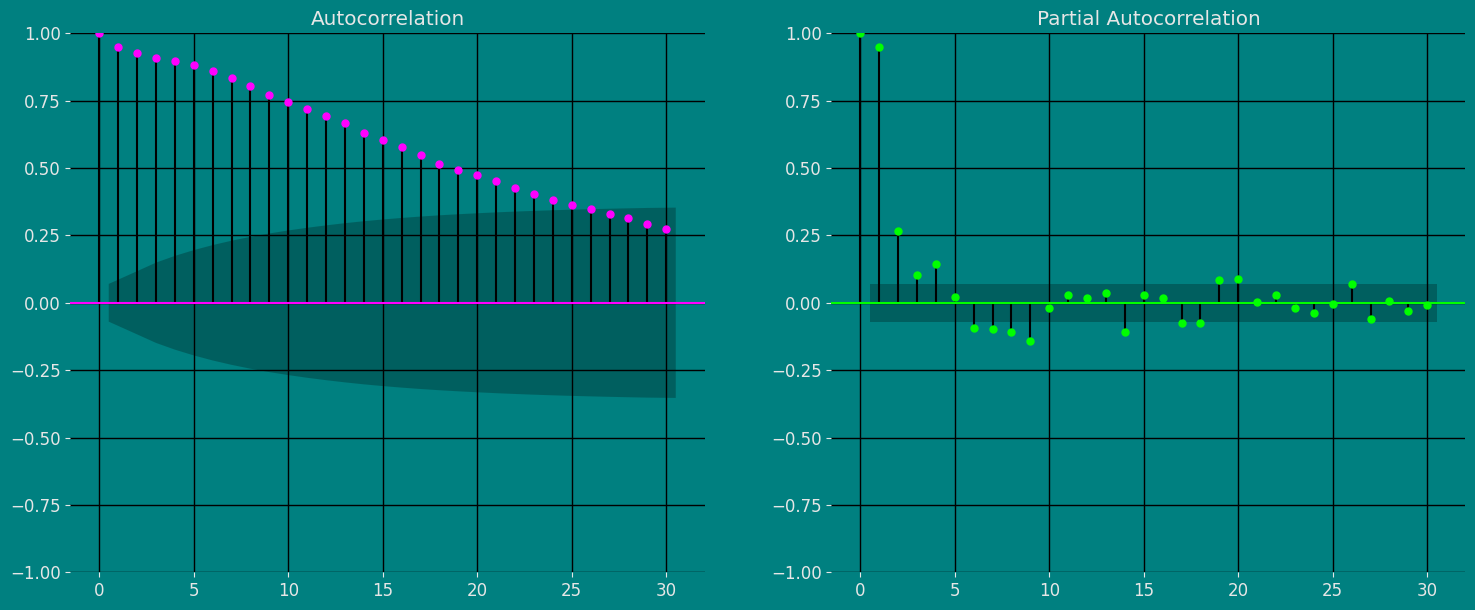
Autocorrelation plots
Decomposition of the time series
How to decompose a time series and why? In time series analysis to forecast new values, it is very important to know past data. More formally, we can say that it is very important to know the patterns that values follow over time. There can be many reasons that cause our forecast values to fall in the wrong direction. Basically, a time series consists of four components. The variation of those components causes the change in the pattern of the time series. These components are:- Level: This is the primary value that averages over time.
- Trend: The trend is the value that causes increasing or decreasing patterns in a time series.
- Seasonality: This is a cyclical event that occurs in a time series for a short time and causes short-term increasing or decreasing patterns in a time series.
- Residual/Noise: These are the random variations in the time series.
Additive time series
If the components of the time series are added to make the time series. Then the time series is called the additive time series. By visualization, we can say that the time series is additive if the increasing or decreasing pattern of the time series is similar throughout the series. The mathematical function of any additive time series can be represented by:Multiplicative time series
If the components of the time series are multiplicative together, then the time series is called a multiplicative time series. For visualization, if the time series is having exponential growth or decline with time, then the time series can be considered as the multiplicative time series. The mathematical function of the multiplicative time series can be represented as.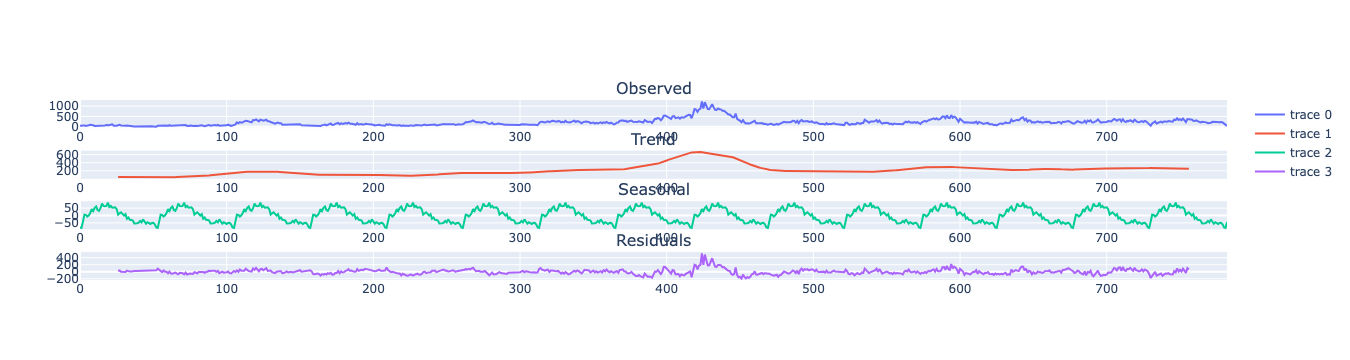
Split the data into training and testing
Let’s divide our data into sets 1. Data to train ourADIDA Model. 2.
Data to test our model
For the test data we will use the last 25 week to test and evaluate the
performance of our model.
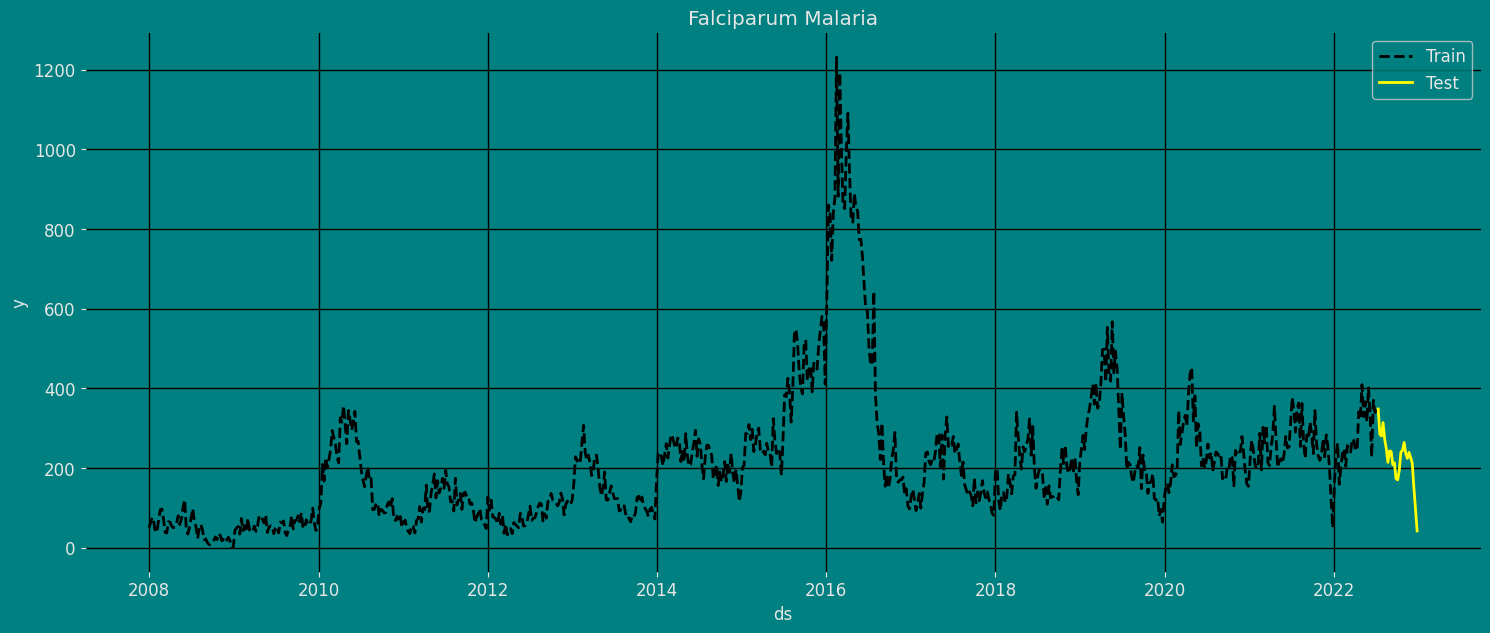
Implementation of ADIDA Model with StatsForecast
To also know more about the parameters of the functions of the
ADIDA Model, they are listed below. For more information, visit the
documentation
Load libraries
Instantiating Model
Import and instantiate the models. Setting the argument is sometimes tricky. This article on Seasonal periods by the master, Rob Hyndmann, can be useful forseason_length.
StatsForecast object with the
following parameters:
models: a list of models. Select the models you want from models and
import them.
-
freq:a string indicating the frequency of the data. (See pandas’ available frequencies.) -
n_jobs:n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores. -
fallback_model:a model to be used if a model fails.
Fit the Model
Here, we call thefit() method to fit the model.
ADIDA Model. We can observe it with the
following instruction:
Forecast Method
If you want to gain speed in productive settings where you have multiple series or models we recommend using theStatsForecast.forecast method
instead of .fit and .predict.
The main difference is that the forecast() method does not store the
fitted values and is highly scalable in distributed environments.
The forecast method takes two arguments: forecasts next h (horizon)
and level.
h (int):represents the forecast h steps into the future. In this case, 25 week ahead.
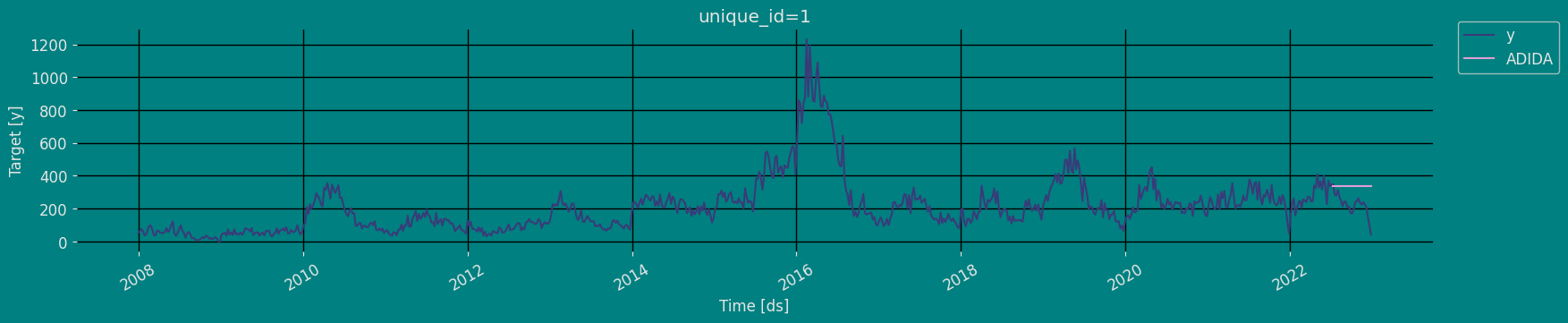
Predict method with confidence interval
To generate forecasts use the predict method. The predict method takes two arguments: forecasts the nexth (for
horizon) and level.
h (int):represents the forecast h steps into the future. In this case, 25 week ahead.
Cross-validation
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:Perform time series cross-validation
Cross-validation of time series models is considered a best practice but most implementations are very slow. The statsforecast library implements cross-validation as a distributed operation, making the process less time-consuming to perform. If you have big datasets you can also perform Cross Validation in a distributed cluster using Ray, Dask or Spark. In this case, we want to evaluate the performance of each model for the last 5 months(n_windows=), forecasting every second months
(step_size=12). Depending on your computer, this step should take
around 1 min.
The cross_validation method from the StatsForecast class takes the
following arguments.
-
df:training data frame -
h (int):represents h steps into the future that are being forecasted. In this case, 12 months ahead. -
step_size (int):step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int):number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_id:series identifierds:datestamp or temporal indexcutoff:the last datestamp or temporal index for then_windows.y:true valuemodel:columns with the model’s name and fitted value.
Model Evaluation
Now we are going to evaluate our model with the results of the predictions, we will use different types of metrics MAE, MAPE, MASE, RMSE, SMAPE to evaluate the accuracy.References
- Changquan Huang • Alla Petukhina. Springer series (2022). Applied Time Series Analysis and Forecasting with Python.
- Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic Adaptive Model (ADAM)
- James D. Hamilton. Time Series Analysis Princeton University Press, Princeton, New Jersey, 1st Edition, 1994.
- Nixtla ADIDA API
- Pandas available frequencies.
- Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting Principles and Practice (3rd ed)”.
- Seasonal periods- Rob J Hyndman.