

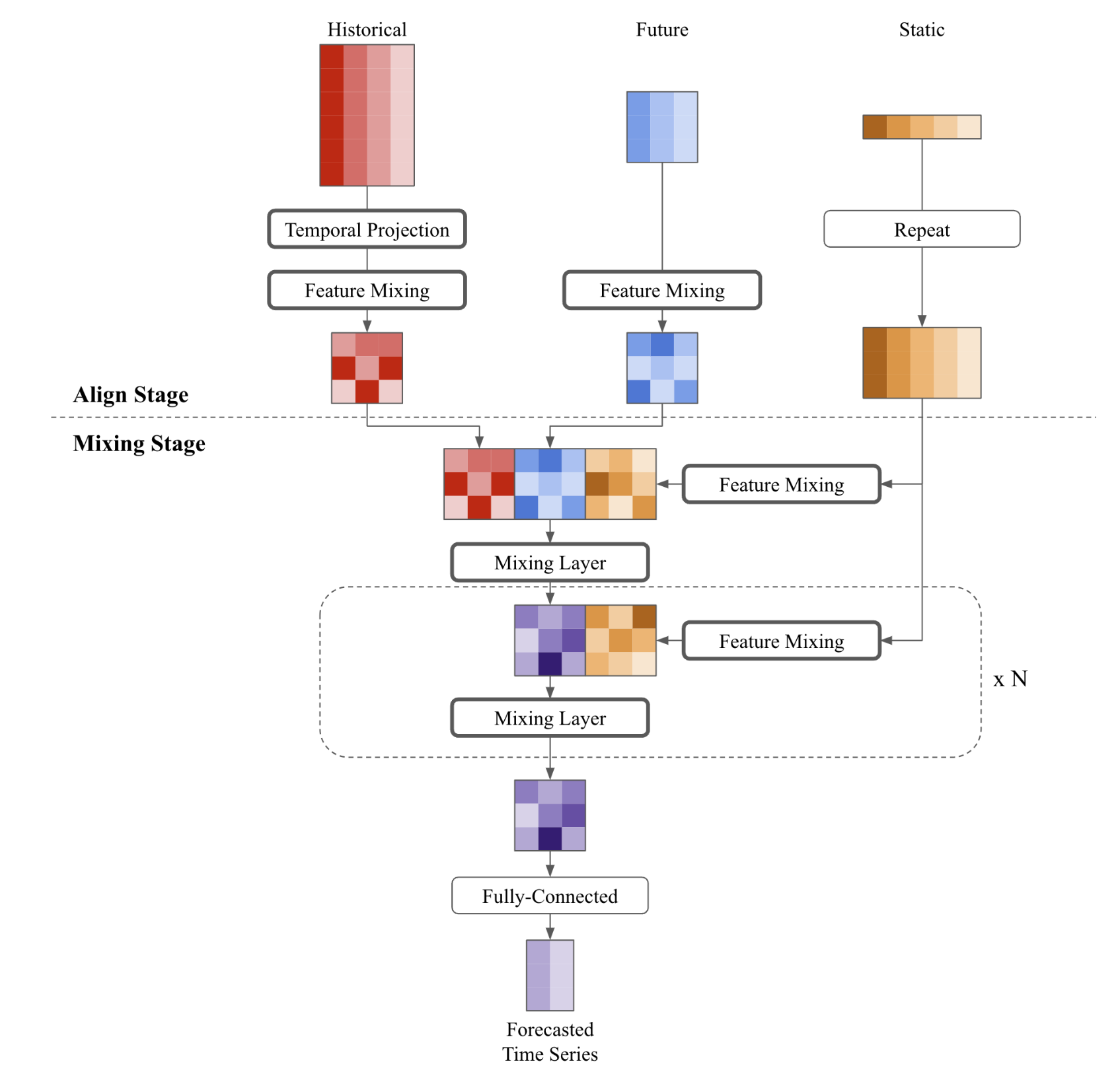
TSMixerx) is a MLP-based multivariate
time-series forecasting model, with capability for additional exogenous
inputs. TSMixerx jointly learns temporal and cross-sectional representations
of the time-series by repeatedly combining time and feature information using
stacked mixing layers. A mixing layer consists of a sequential time- and
feature Multi Layer Perceptron (MLP).
1. TSMixerx
TSMixerx
BaseModel
TSMixerx
Time-Series Mixer exogenous (TSMixerx) is a MLP-based multivariate time-series forecasting model, with capability for additional exogenous inputs. TSMixerx jointly learns temporal and cross-sectional representations of the time-series by repeatedly combining time- and feature information using stacked mixing layers. A mixing layer consists of a sequential time- and feature Multi Layer Perceptron (MLP).
Parameters:
TSMixerx.fit
fit method, optimizes the neural network’s weights using the
initialization parameters (learning_rate, windows_batch_size, …)
and the loss function as defined during the initialization.
Within fit we use a PyTorch Lightning Trainer that
inherits the initialization’s self.trainer_kwargs, to customize
its inputs, see PL’s trainer arguments.
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the model is not saving training checkpoints to protect
disk memory, to get them change enable_checkpointing=True in __init__.
Parameters:
Returns:
TSMixerx.predict
Trainer execution of predict_step.
Parameters:
Returns:
Usage Examples
Train model and forecast future values withpredict method.
cross_validation to forecast multiple historic values.
2. Auxiliary Functions
2.1 Mixing layers
A mixing layer consists of a sequential time- and feature Multi Layer Perceptron (MLP).
MixingLayerWithStaticExogenous
Module
MixingLayerWithStaticExogenous
MixingLayer
Module
MixingLayer
FeatureMixing
Module
FeatureMixing
TemporalMixing
Module
TemporalMixing