

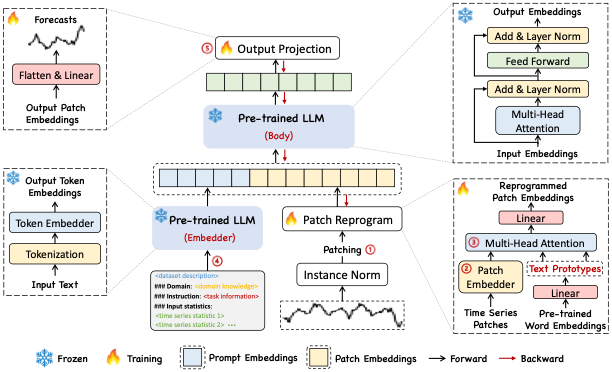
1. Time-LLM
Usage example
2. Auxiliary Functions
ReprogrammingLayer
Module
ReprogrammingLayer
FlattenHead
Module
FlattenHead
PatchEmbedding
Module
PatchEmbedding
TokenEmbedding
Module
TokenEmbedding
ReplicationPad1d
Module
ReplicationPad1d