1. Installing Packages
2. Load PHM2008 aircraft degradation dataset
3. Fit and Predict NeuralForecast
4. Evaluate Predictions You can run these experiments using GPU with Google Colab.
1. Installing Packages
2. Load PHM2008 aircraft degradation dataset
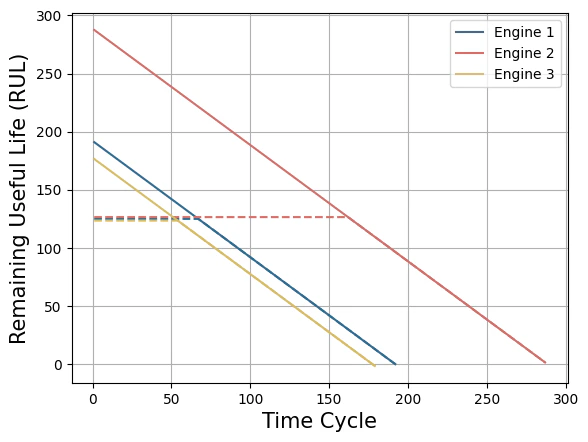
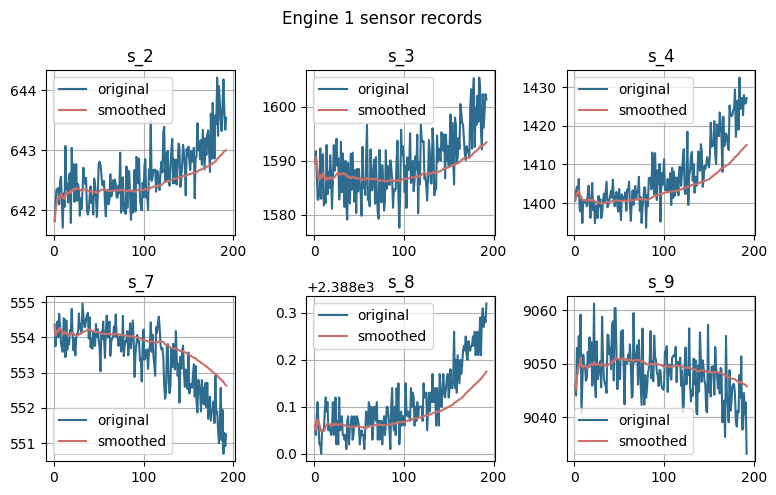
Here we will load the Prognosis and Health Management 2008 challenge dataset. This dataset used the Commercial Modular Aero-Propulsion System Simulation to recreate the degradation process of turbofan engines for different aircraft with varying wear and manufacturing starting under normal conditions. The training dataset consists of complete run-to-failure simulations, while the test dataset comprises sequences before failure.
3. Fit and Predict NeuralForecast
NeuralForecast methods are capable of addressing regression problems involving various variables. The regression problem involves predicting the target variable based on its lags , temporal exogenous features , exogenous features available at the time of prediction , and static features . The task of estimating the remaining useful life (RUL) simplifies the problem to a single horizon prediction , where the objective is to predict based on the exogenous features and static features . In the RUL estimation task, the exogenous features typically correspond to sensor monitoring information, while the target variable represents the RUL itself.4. Evaluate Predictions
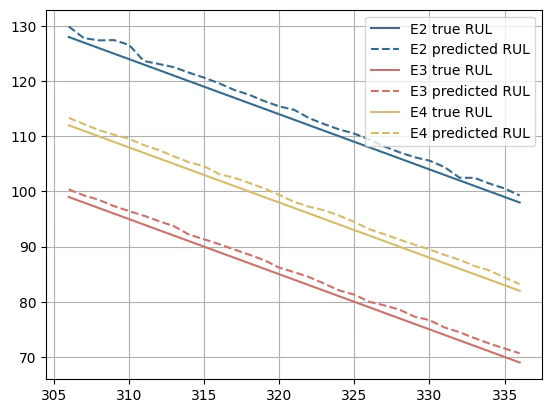
In the original PHM2008 dataset the true RUL values for the test set are only provided for the last time cycle of each enginge. We will filter the predictions to only evaluate the last time cycle.
Alternatively, we can also evaluate over multiple windows to have a more
representative metric of the performance.
Finally, we can plot the true value and predicted value of the model
across many cross-validation windows.