

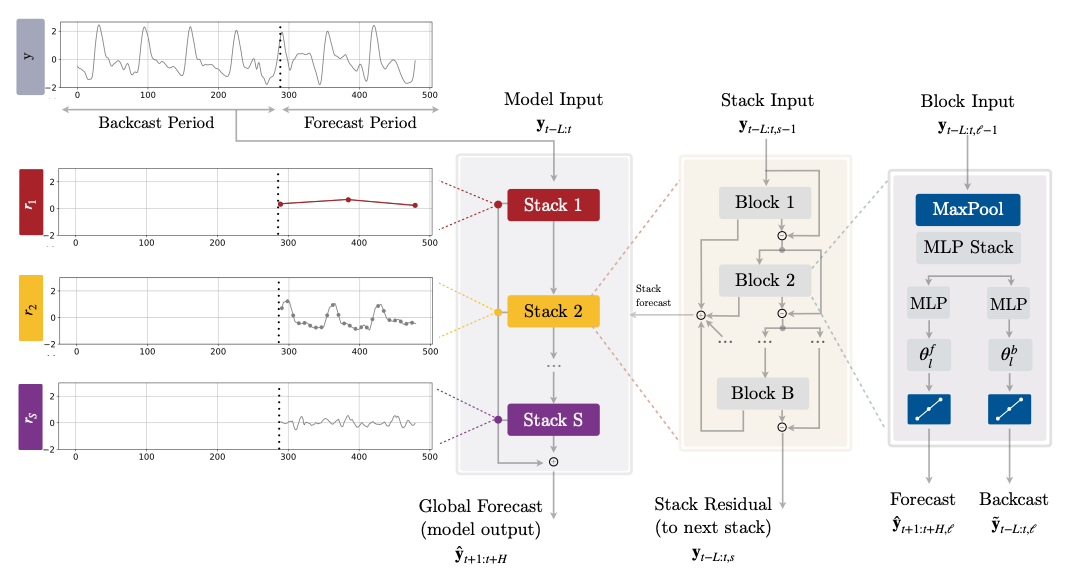
NHITS
builds upon
NBEATS
and specializes its partial outputs in the different frequencies of the
time series through hierarchical interpolation and multi-rate input
processing. On the long-horizon forecasting task
NHITS
improved accuracy by 25% on AAAI’s best paper award the
Informer,
while being 50x faster.
The model is composed of several MLPs with ReLU non-linearities. Blocks
are connected via doubly residual stacking principle with the backcast
and forecast
outputs of the l-th block. Multi-rate
input pooling, hierarchical interpolation and backcast residual
connections together induce the specialization of the additive
predictions in different signal bands, reducing memory footprint and
computational time, thus improving the architecture parsimony and
accuracy.
References
- Boris N. Oreshkin, Dmitri Carpov, Nicolas Chapados, Yoshua Bengio (2019). “N-BEATS: Neural basis expansion analysis for interpretable time series forecasting”.
- Cristian Challu, Kin G. Olivares, Boris N. Oreshkin, Federico Garza, Max Mergenthaler-Canseco, Artur Dubrawski (2023). “NHITS: Neural Hierarchical Interpolation for Time Series Forecasting”. Accepted at the Thirty-Seventh AAAI Conference on Artificial Intelligence.
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; and Zhang, W. (2020). “Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting”. Association for the Advancement of Artificial Intelligence Conference 2021 (AAAI 2021).
NHITS
NHITS
BaseModel
NHITS
The Neural Hierarchical Interpolation for Time Series (NHITS), is an MLP-based deep
neural architecture with backward and forward residual links. NHITS tackles volatility and
memory complexity challenges, by locally specializing its sequential predictions into
the signals frequencies with hierarchical interpolation and pooling.
Parameters:
NHITS.fit
fit method, optimizes the neural network’s weights using the
initialization parameters (learning_rate, windows_batch_size, …)
and the loss function as defined during the initialization.
Within fit we use a PyTorch Lightning Trainer that
inherits the initialization’s self.trainer_kwargs, to customize
its inputs, see PL’s trainer arguments.
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the model is not saving training checkpoints to protect
disk memory, to get them change enable_checkpointing=True in __init__.
Parameters:
Returns:
NHITS.predict
Trainer execution of predict_step.
Parameters:
Returns: