

NBEATS)
is an
MLP-based
deep neural architecture with backward and forward residual links. The
network has two variants: (1) in its interpretable configuration,
NBEATS
sequentially projects the signal into polynomials and harmonic basis to
learn trend and seasonality components; (2) in its generic
configuration, it substitutes the polynomial and harmonic basis for
identity basis and larger network’s depth. The Neural Basis Expansion
Analysis with Exogenous
(NBEATSx),
incorporates projections to exogenous temporal variables available at
the time of the prediction.
This method proved state-of-the-art
performance on the M3, M4, and Tourism Competition datasets, improving
accuracy by 3% over the ESRNN M4 competition winner. For Electricity
Price Forecasting tasks
NBEATSx
model improved accuracy by 20% and 5% over ESRNN and
NBEATS,
and 5% on task-specialized
architectures.
References
- Boris N. Oreshkin, Dmitri Carpov, Nicolas Chapados, Yoshua Bengio (2019). “N-BEATS: Neural basis expansion analysis for interpretable time series forecasting”.
- Kin G. Olivares, Cristian Challu, Grzegorz Marcjasz, Rafał Weron, Artur Dubrawski (2021). “Neural basis expansion analysis with exogenous variables: Forecasting electricity prices with NBEATSx”.
NBEATSx
NBEATSx
BaseModel
NBEATSx
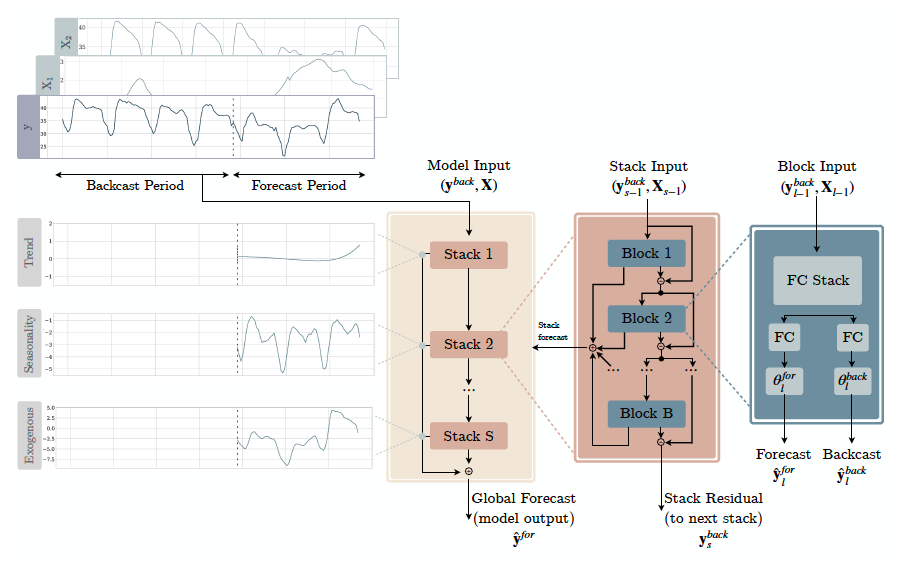
The Neural Basis Expansion Analysis with Exogenous variables (NBEATSx) is a simple
and effective deep learning architecture. It is built with a deep stack of MLPs with
doubly residual connections. The NBEATSx architecture includes additional exogenous
blocks, extending NBEATS capabilities and interpretability. With its interpretable
version, NBEATSx decomposes its predictions on seasonality, trend, and exogenous effects.
Parameters:
NBEATSx.fit
fit method, optimizes the neural network’s weights using the
initialization parameters (learning_rate, windows_batch_size, …)
and the loss function as defined during the initialization.
Within fit we use a PyTorch Lightning Trainer that
inherits the initialization’s self.trainer_kwargs, to customize
its inputs, see PL’s trainer arguments.
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the model is not saving training checkpoints to protect
disk memory, to get them change enable_checkpointing=True in __init__.
Parameters:
Returns:
NBEATSx.predict
Trainer execution of predict_step.
Parameters:
Returns: