

1. Autoformer
Autoformer
BaseModel
Autoformer
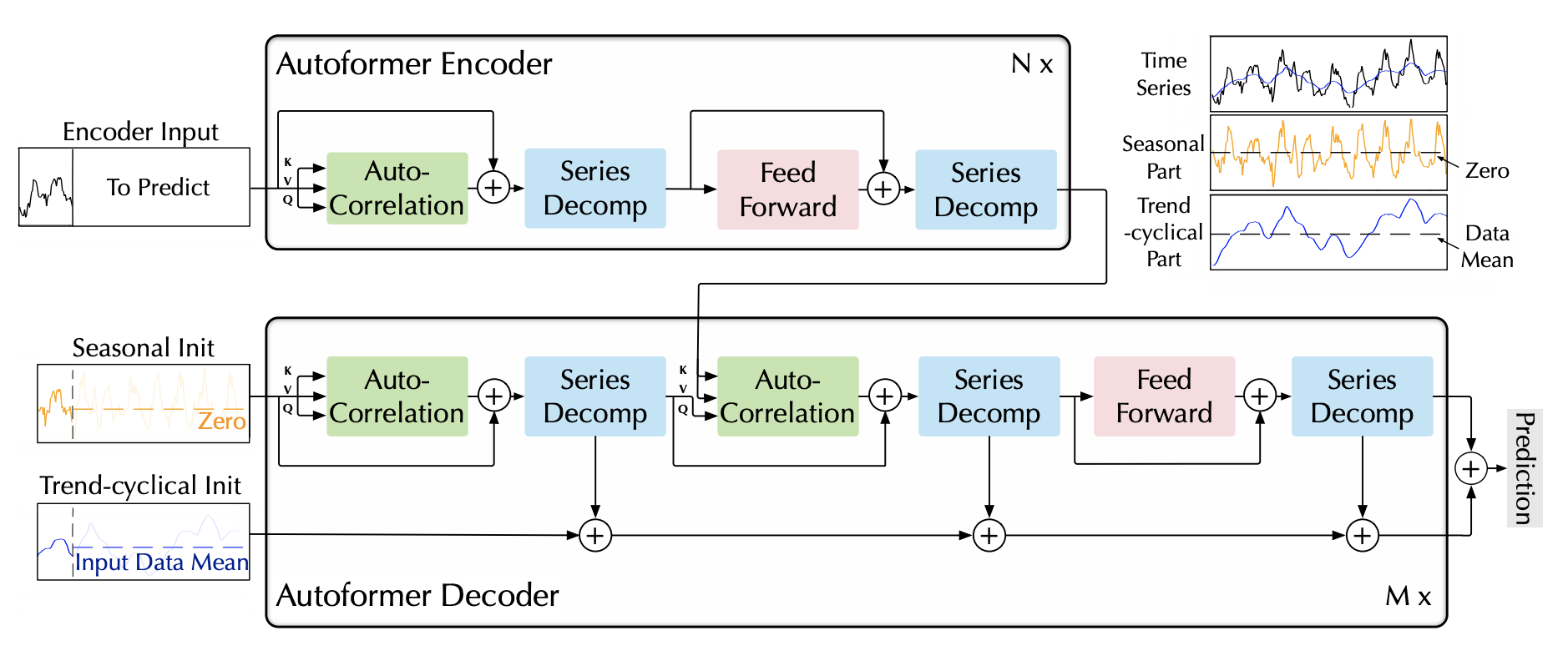
The Autoformer model tackles the challenge of finding reliable dependencies on intricate temporal patterns of long-horizon forecasting.
The architecture has the following distinctive features:
- In-built progressive decomposition in trend and seasonal compontents based on a moving average filter.
- Auto-Correlation mechanism that discovers the period-based dependencies by calculating the autocorrelation and aggregating similar sub-series based on the periodicity.
- Classic encoder-decoder proposed by Vaswani et al. (2017) with a multi-head attention mechanism.
- It employs encoded autoregressive features obtained from a convolution network.
- Absolute positional embeddings obtained from calendar features are utilized.
Autoformer.fit
fit method, optimizes the neural network’s weights using the
initialization parameters (learning_rate, windows_batch_size, …)
and the loss function as defined during the initialization.
Within fit we use a PyTorch Lightning Trainer that
inherits the initialization’s self.trainer_kwargs, to customize
its inputs, see PL’s trainer arguments.
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the model is not saving training checkpoints to protect
disk memory, to get them change enable_checkpointing=True in __init__.
Parameters:
Returns:
Autoformer.predict
Trainer execution of predict_step.
Parameters:
Returns:
Usage Example
2. Auxiliary functions
Decoder
Module
Autoformer decoder
DecoderLayer
Module
Autoformer decoder layer with the progressive decomposition architecture
Encoder
Module
Autoformer encoder
EncoderLayer
Module
Autoformer encoder layer with the progressive decomposition architecture
LayerNorm
Module
Special designed layernorm for the seasonal part
AutoCorrelationLayer
Module
Auto Correlation Layer
AutoCorrelation
Module
AutoCorrelation Mechanism with the following two phases:
(1) period-based dependencies discovery
(2) time delay aggregation
This block can replace the self-attention family mechanism seamlessly.