

MLP)
composed of stacked Fully Connected Neural Networks trained with
backpropagation. Each node in the architecture is capable of modeling
non-linear relationships granted by their activation functions. Novel
activations like Rectified Linear Units (ReLU) have greatly improved the
ability to fit deeper networks overcoming gradient vanishing problems that
were associated with Sigmoid and TanH activations. For the forecasting
task the last layer is changed to follow a auto-regression problem. This
version is multivariate, indicating that it will predict all time series of
the forecasting problem jointly.
References
-Rosenblatt, F. (1958). “The perceptron: A probabilistic model for information storage and organization in the brain.”
-Fukushima, K. (1975). “Cognitron: A self-organizing multilayered neural network.”
-Vinod Nair, Geoffrey E. Hinton (2010). “Rectified Linear Units Improve Restricted Boltzmann Machines”
MLPMultivariate
MLPMultivariate
BaseModel
MLPMultivariate
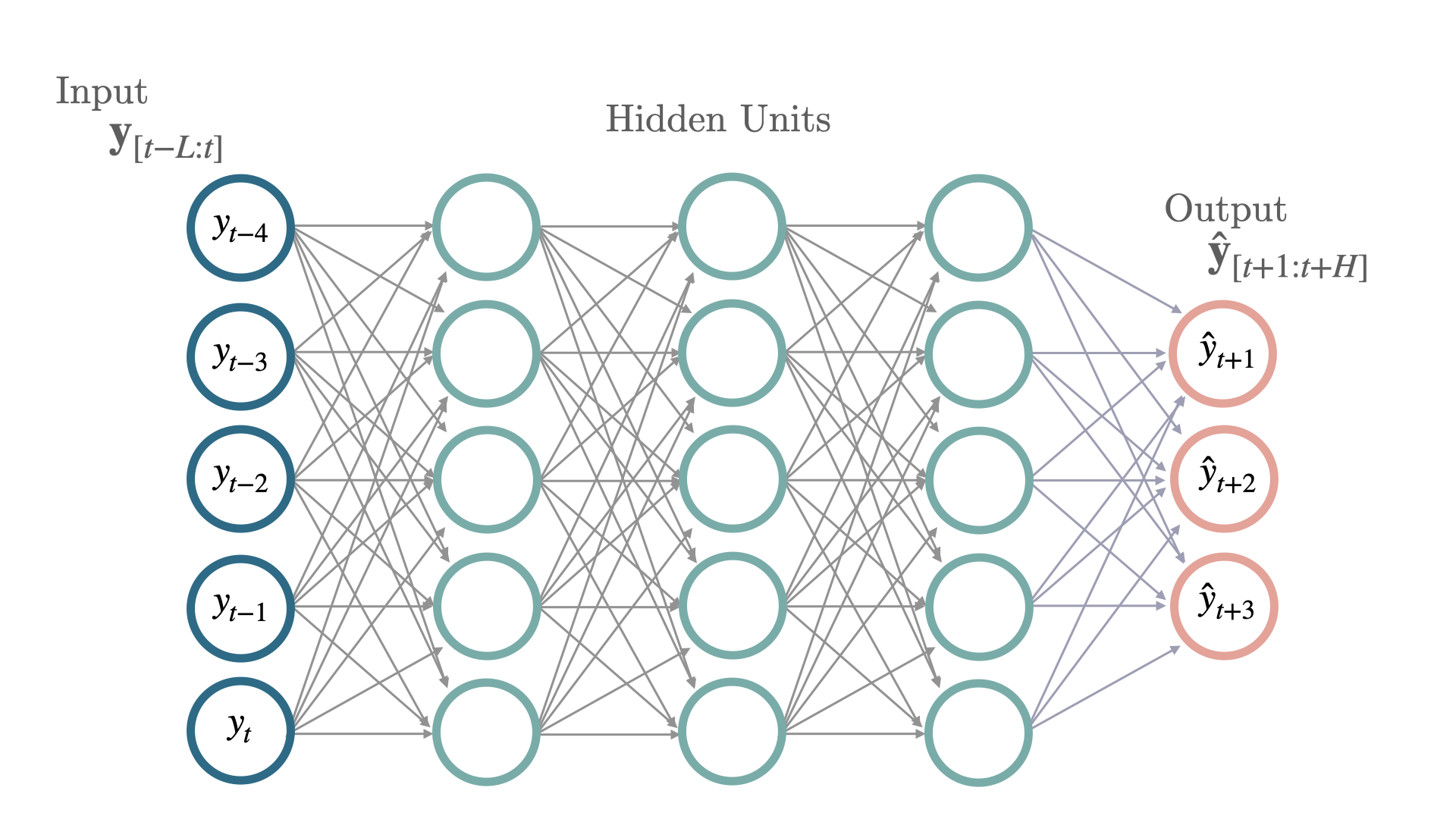
Simple Multi Layer Perceptron architecture (MLP) for multivariate forecasting.
This deep neural network has constant units through its layers, each with
ReLU non-linearities, it is trained using ADAM stochastic gradient descent.
The network accepts static, historic and future exogenous data, flattens
the inputs and learns fully connected relationships against the target variables.
Parameters:
MLPMultivariate.fit
fit method, optimizes the neural network’s weights using the
initialization parameters (learning_rate, windows_batch_size, …)
and the loss function as defined during the initialization.
Within fit we use a PyTorch Lightning Trainer that
inherits the initialization’s self.trainer_kwargs, to customize
its inputs, see PL’s trainer arguments.
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the model is not saving training checkpoints to protect
disk memory, to get them change enable_checkpointing=True in __init__.
Parameters:
Returns:
MLPMultivariate.predict
Trainer execution of predict_step.
Parameters:
Returns: