

In this example we will show how to perform electricity load forecasting on the ERCOT (Texas) market for detecting daily peaks.
Introduction
Predicting peaks in different markets is useful. In the electricity market, consuming electricity at peak demand is penalized with higher tarifs. When an individual or company consumes electricity when its most demanded, regulators calls that a coincident peak (CP). In the Texas electricity market (ERCOT), the peak is the monthly 15-minute interval when the ERCOT Grid is at a point of highest capacity. The peak is caused by all consumers’ combined demand on the electrical grid. The coincident peak demand is an important factor used by ERCOT to determine final electricity consumption bills. ERCOT registers the CP demand of each client for 4 months, between June and September, and uses this to adjust electricity prices. Clients can therefore save on electricity bills by reducing the coincident peak demand. In this example we will train anNHITS model on historic load data to
forecast day-ahead peaks on September 2022. Multiple seasonality is
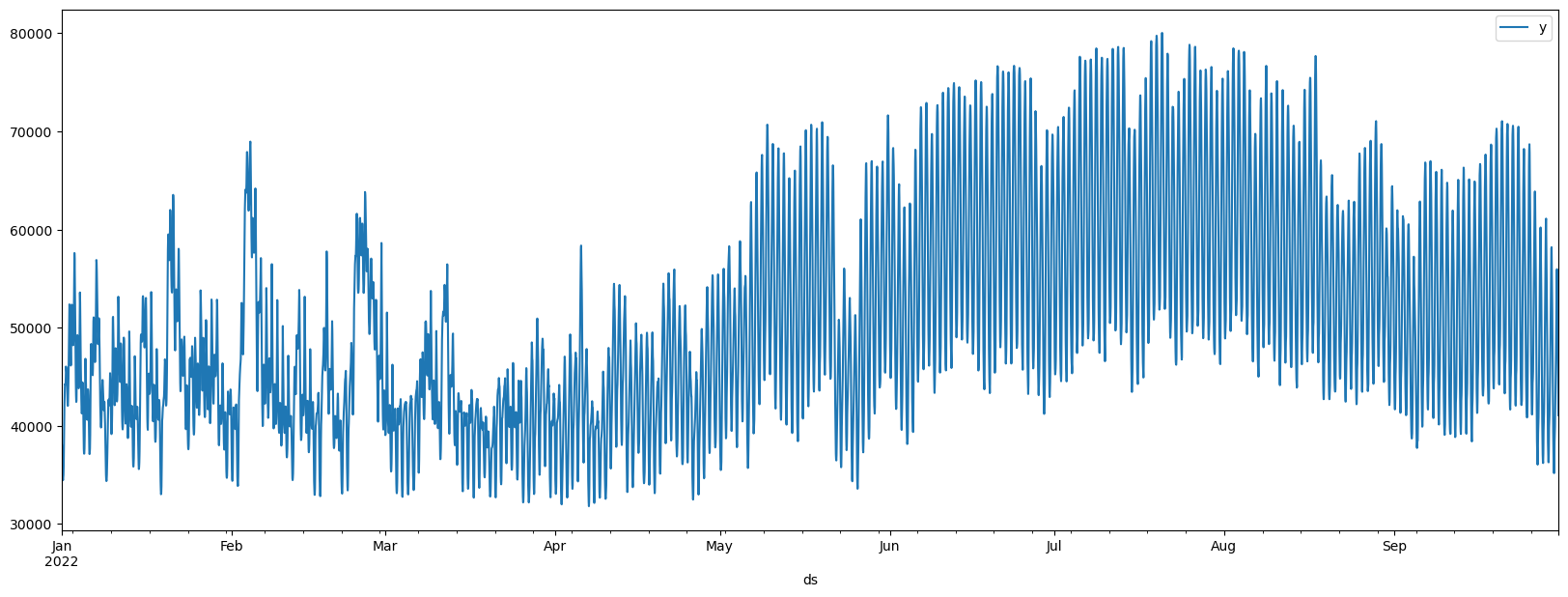
traditionally present in low sampled electricity data. Demand exhibits
daily and weekly seasonality, with clear patterns for specific hours of
the day such as 6:00pm vs 3:00am or for specific days such as Sunday vs
Friday.
First, we will load ERCOT historic demand, then we will use the
Neuralforecast.cross_validation method to fit the model and forecast
daily load during September. Finally, we show how to use the forecasts
to detect the coincident peak.
Outline
- Install libraries
- Load and explore the data
- Fit NHITS model and forecast
- Peak detection
Tip You can use Colab to run this Notebook interactively
Libraries
We assume you have NeuralForecast already installed. Check this guide for instructions on how to install NeuralForecast. Install the necessary packages usingpip install neuralforecast
Load Data
The input to NeuralForecast models is always a data frame in long format with three columns:unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp or int) column should be either an integer indexing time or a datestamp ideally like YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast. We will rename the
Fit and Forecast with NHITS
Import theNeuralForecast class and the models you need.
AutoNHITS you need to define:
h: forecasting horizonloss: training loss. Use theDistributionLossto produce probabilistic forecasts. Default:MAE.config: hyperparameter search space. IfNone, theAutoNHITSclass will use a pre-defined suggested hyperparameter space.num_samples: number of configurations explored.
NeuralForecast object with the
following required parameters:
-
models: a list of models. Select the models you want from models and import them. -
freq: a string indicating the frequency of the data. (See panda’s available frequencies.)
cross_validation method allows the user to simulate multiple
historic forecasts, greatly simplifying pipelines by replacing for loops
with fit and predict methods. This method re-trains the model and
forecast each window. See this
tutorial
for an animation of how the windows are defined.
Use the cross_validation method to produce all the daily forecasts for
September. To produce daily forecasts set the forecasting horizon h as
24. In this example we are simulating deploying the pipeline during
September, so set the number of windows as 30 (one for each day).
Finally, set the step size between windows as 24, to only produce one
forecast per day.
Important When usingcross_validationmake sure the forecasts are produced at the desired timestamps. Check thecutoffcolumn which specifices the last timestamp before the forecasting window.
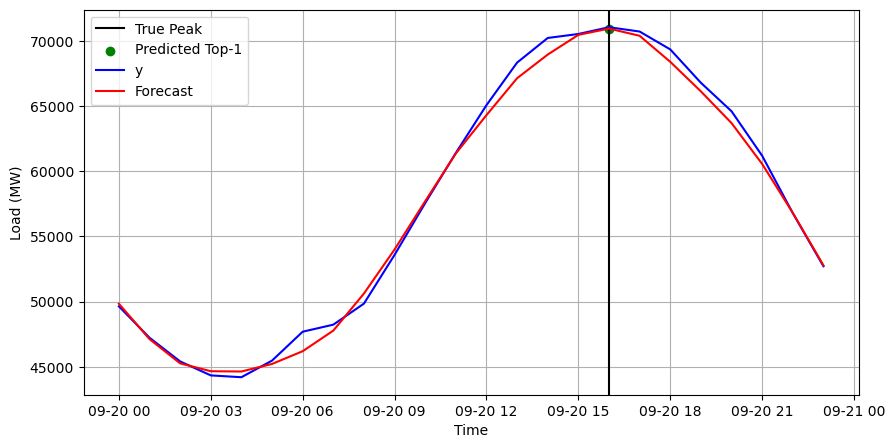
Peak Detection
Finally, we use the forecasts incrossvaldation_df to detect the daily
hourly demand peaks. For each day, we set the detected peaks as the
highest forecasts. In this case, we want to predict one peak (npeaks);
depending on your setting and goals, this parameter might change. For
example, the number of peaks can correspond to how many hours a battery
can be discharged to reduce demand.
Important In this example we only include September. However,NHITScan correctly predict the peaks for the 4 months of 2022. You can try this by increasing thenwindowsparameter ofcross_validationor filtering theY_dfdataset. The complete run for all months take only 10 minutes.