- Jan Golda, Krzysztof Kudrynski. “NVIDIA, Deep Learning Forecasting Examples”
- Bryan Lim, Sercan O. Arik, Nicolas Loeff, Tomas Pfister, “Temporal Fusion Transformers for interpretable multi-horizon time series forecasting”
1. Temporal Fusion Decoder
TFT
BaseModel
TFT
The Temporal Fusion Transformer architecture (TFT) is an Sequence-to-Sequence
model that combines static, historic and future available data to predict an
univariate target. The method combines gating layers, an LSTM recurrent encoder,
with and interpretable multi-head attention layer and a multi-step forecasting
strategy decoder.
Parameters:
TFT.fit
fit method, optimizes the neural network’s weights using the
initialization parameters (learning_rate, windows_batch_size, …)
and the loss function as defined during the initialization.
Within fit we use a PyTorch Lightning Trainer that
inherits the initialization’s self.trainer_kwargs, to customize
its inputs, see PL’s trainer arguments.
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the model is not saving training checkpoints to protect
disk memory, to get them change enable_checkpointing=True in __init__.
Parameters:
Returns:
TFT.predict
Trainer execution of predict_step.
Parameters:
Returns:
TFT.feature_importances
TFT.attention_weights
TFT.feature_importance_correlations
Usage Example
2. TFT Architecture
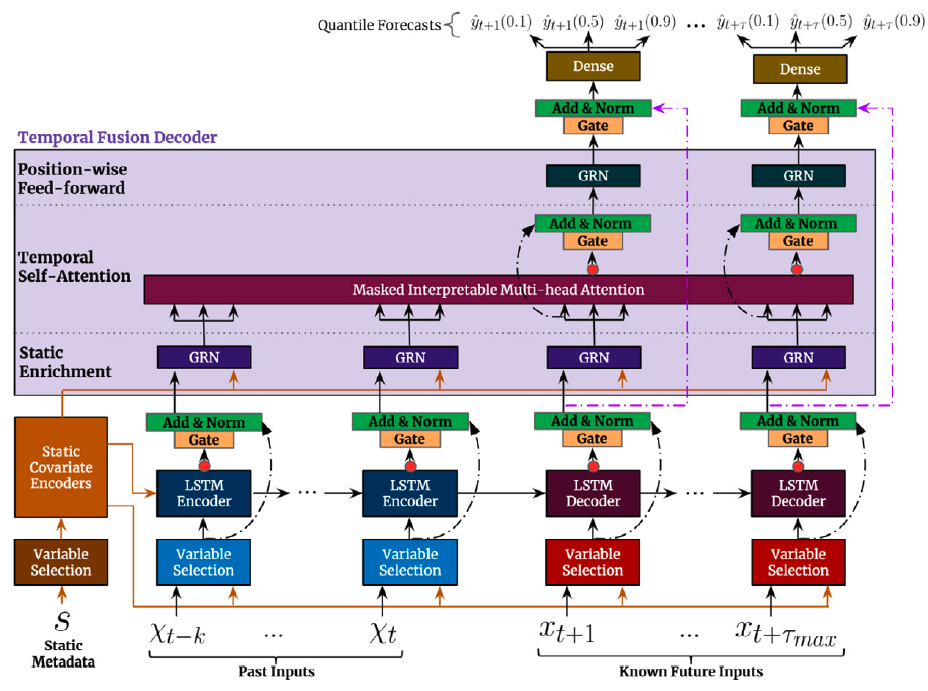
The first TFT’s step is embed the original input into a high dimensional space , after which each embedding is gated by a variable selection network (VSN). The static embedding is used as context for variable selection and as initial condition to the LSTM. Finally the encoded variables are fed into the multi-head attention decoder.2.1 Static Covariate Encoder
The static embedding is transformed by the StaticCovariateEncoder into contexts . Where are temporal variable selection contexts, are TemporalFusionDecoder enriching contexts, and are LSTM’s hidden/contexts for the TemporalCovariateEncoder.2.2 Temporal Covariate Encoder
TemporalCovariateEncoder encodes the embeddings and contexts with an LSTM. An analogous process is repeated for the future data, with the main difference that contains the future available information.2.3 Temporal Fusion Decoder
The TemporalFusionDecoder enriches the LSTM’s outputs with and then uses an attention layer, and multi-step adapter.3. Interpretability
3.1 Attention Weights
3.1.1 Mean attention
3.1.2 Attention of all future time steps
3.1.3 Attention of a specific future time step
3.2 Feature Importance
3.2.1 Global feature importance
Static variable importances
Past variable importances
Future variable importances
3.2.2 Variable importances over time
Future variable importance over time
Importance of each future covariate at each future time stepPast variable importance over time
Past variable importance over time ponderated by attention
Decomposition of the importance of each time step based on importance of each variable at that time step3.2.3 Variable importance correlations over time
Variables which gain and lose importance at same moments4. Auxiliary Functions
4.1 Gating Mechanisms
The Gated Residual Network (GRN) provides adaptive depth and network complexity capable of accommodating different size datasets. As residual connections allow for the network to skip the non-linear transformation of input and context . The Gated Linear Unit (GLU) provides the flexibility of supressing unnecesary parts of the GRN. Consider GRN’s output then GLU transformation is defined by: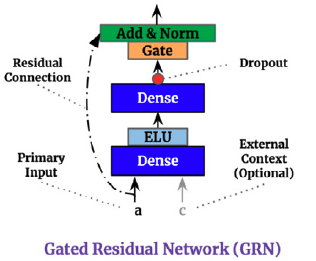
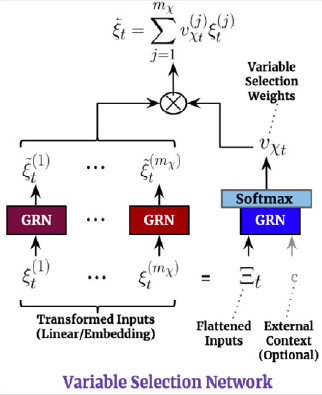
4.2 Variable Selection Networks
TFT includes automated variable selection capabilities, through its variable selection network (VSN) components. The VSN takes the original input and transforms it through embeddings or linear transformations into a high dimensional space . For the observed historic data, the embedding matrix at time is a concatenation of variable embeddings: The variable selection weights are given by: The VSN processed features are then: