

NHITS’s inputs are static exogenous , historic exogenous , exogenous available at the time of the prediction and autoregressive features , each of these inputs is further decomposed into categorical and continuous. The network uses a multi-quantile regression to model the following conditional probability: In this notebook we show how to fit NeuralForecast methods for binary sequences regression. We will: - Installing NeuralForecast. - Loading binary sequence data. - Fit and predict temporal classifiers. - Plot and evaluate predictions. You can run these experiments using GPU with Google Colab.
1. Installing NeuralForecast
2. Loading Binary Sequence Data
Thecore.NeuralForecast class contains shared, fit, predict and
other methods that take as inputs pandas DataFrames with columns
['unique_id', 'ds', 'y'], where unique_id identifies individual time
series from the dataset, ds is the date, and y is the target binary
variable.
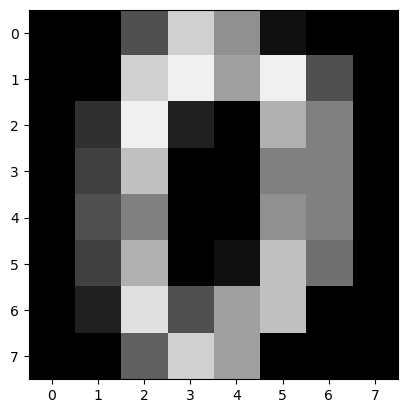
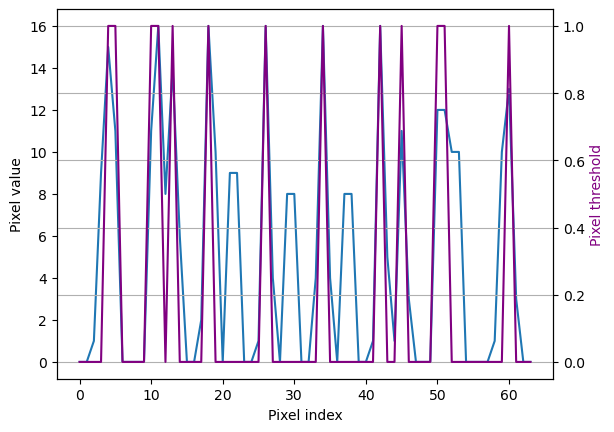
In this motivation example we convert 8x8 digits images into 64-length
sequences and define a classification problem, to identify when the
pixels surpass certain threshold. We declare a pandas dataframe in long
format, to match NeuralForecast’s inputs.
3. Fit and predict temporal classifiers
Fit the models
Using theNeuralForecast.fit method you can train a set of models to
your dataset. You can define the forecasting horizon (12 in this
example), and modify the hyperparameters of the model. For example, for
the NHITS we changed the default hidden size for both encoder and
decoders.
See the NHITS and MLP model
documentation.
Warning For the moment Recurrent-based model family is not available to operate with Bernoulli distribution output. This affects the following methodsLSTM,GRU,DilatedRNN, andTCN. This feature is work in progress.
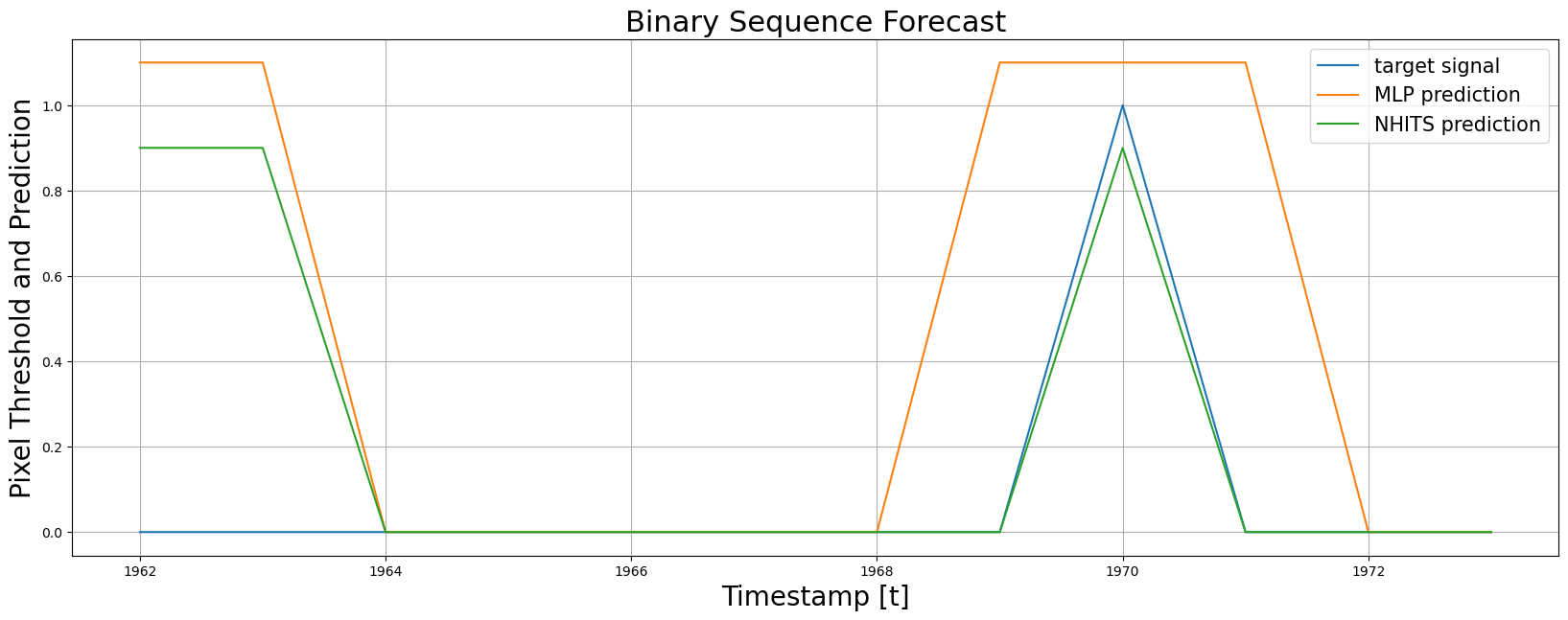
4. Plot and Evaluate Predictions
Finally, we plot the forecasts of both models against the real values. And evaluate the accuracy of theMLP and NHITS temporal classifiers.
References
- Cox D. R. (1958). “The Regression Analysis of Binary Sequences.” Journal of the Royal Statistical Society B, 20(2), 215–242.
- Cristian Challu, Kin G. Olivares, Boris N. Oreshkin, Federico Garza, Max Mergenthaler-Canseco, Artur Dubrawski (2023). NHITS: Neural Hierarchical Interpolation for Time Series Forecasting. Accepted at AAAI 2023.