In this notebook, you will make forecasts for the M5 dataset choosing the best model for each time series using cross validation.Statistical, Machine Learning, and Neural Forecasting Methods In this tutorial, we will explore the process of forecasting on the M5 dataset by utilizing the most suitable model for each time series. We’ll accomplish this through an essential technique known as cross-validation. This approach helps us in estimating the predictive performance of our models, and in selecting the model that yields the best performance for each time series. The M5 dataset comprises of hierarchical sales data, spanning five years, from Walmart. The aim is to forecast daily sales for the next 28 days. The dataset is broken down into the 50 states of America, with 10 stores in each state. In the realm of time series forecasting and analysis, one of the more complex tasks is identifying the model that is optimally suited for a specific group of series. Quite often, this selection process leans heavily on intuition, which may not necessarily align with the empirical reality of our dataset. In this tutorial, we aim to provide a more structured, data-driven approach to model selection for different groups of series within the M5 benchmark dataset. This dataset, well-known in the field of forecasting, allows us to showcase the versatility and power of our methodology. We will train an assortment of models from various forecasting paradigms: StatsForecast
- Baseline models: These models are simple yet often highly effective
for providing an initial perspective on the forecasting problem. We
will use
SeasonalNaiveandHistoricAveragemodels for this category. - Intermittent models: For series with sporadic, non-continuous
demand, we will utilize models like
CrostonOptimized,IMAPA, andADIDA. These models are particularly suited for handling zero-inflated series. - State Space Models: These are statistical models that use
mathematical descriptions of a system to make predictions. The
AutoETSmodel from the statsforecast library falls under this category.
LightGBM, XGBoost, and
LinearRegression can be advantageous due to their capacity to uncover
intricate patterns in data. We’ll use the MLForecast library for this
purpose.
NeuralForecast
Deep Learning: DL models, such as Transformers (AutoTFT) and Neural
Networks (AutoNHITS), allow us to handle complex non-linear
dependencies in time series data. We’ll utilize the NeuralForecast
library for these models.
Using the Nixtla suite of libraries, we’ll be able to drive our model
selection process with data, ensuring we utilize the most suitable
models for specific groups of series in our dataset.
Outline:
- Reading Data: In this initial step, we load our dataset into memory, making it available for our subsequent analysis and forecasting. It is important to understand the structure and nuances of the dataset at this stage.
- Forecasting Using Statistical and Deep Learning Methods: We apply a wide range of forecasting methods from basic statistical techniques to advanced deep learning models. The aim is to generate predictions for the next 28 days based on our dataset.
- Model Performance Evaluation on Different Windows: We assess the performance of our models on distinct windows.
- Selecting the Best Model for a Group of Series: Using the performance evaluation, we identify the optimal model for each group of series. This step ensures that the chosen model is tailored to the unique characteristics of each group.
- Filtering the Best Possible Forecast: Finally, we filter the forecasts generated by our chosen models to obtain the most promising predictions. This is our final output and represents the best possible forecast for each series according to our models.
Warning
This tutorial was originally executed using a c5d.24xlarge EC2
instance.
Installing Libraries
Download and prepare data
The example uses the M5 dataset. It consists of30,490 bottom time series.
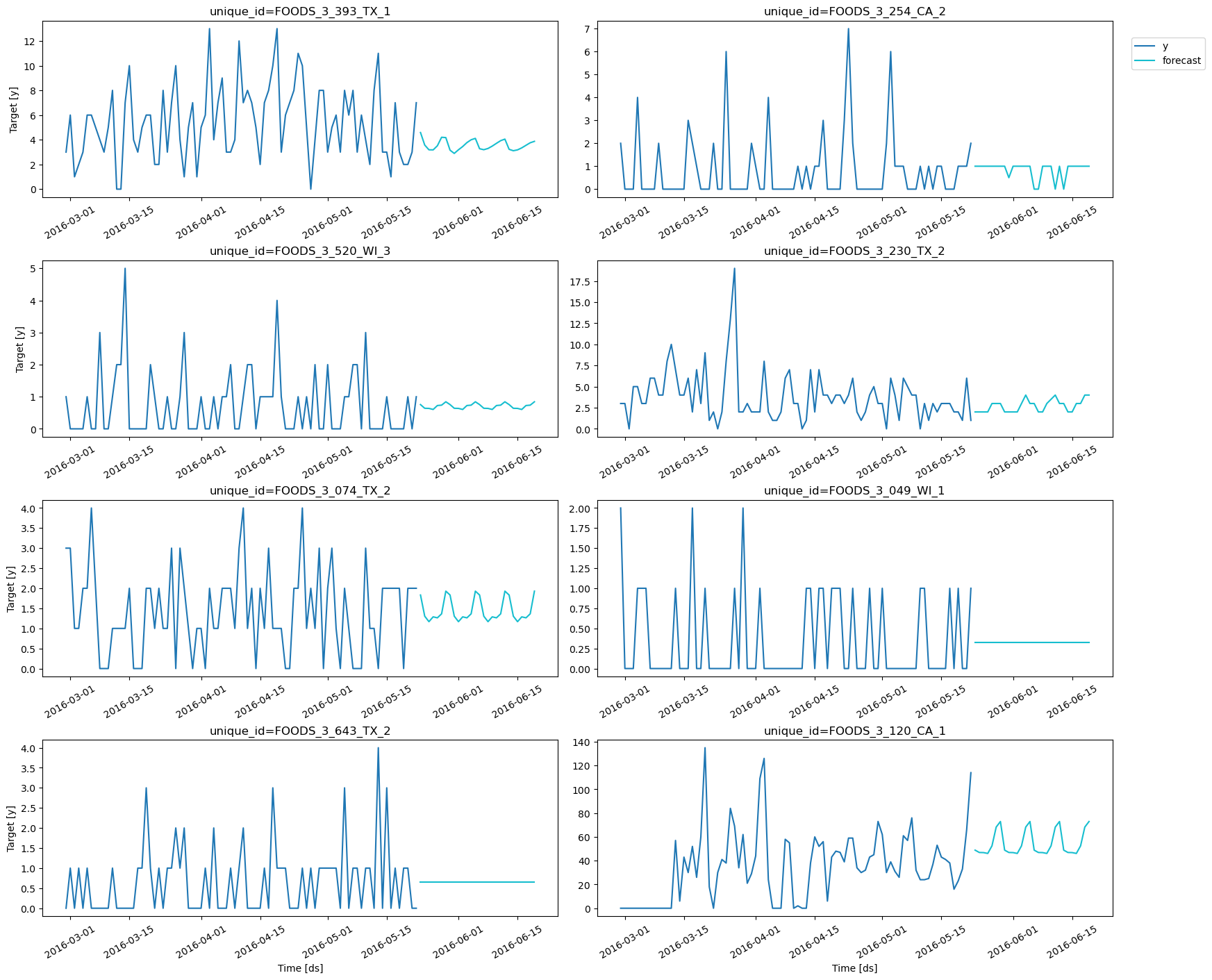
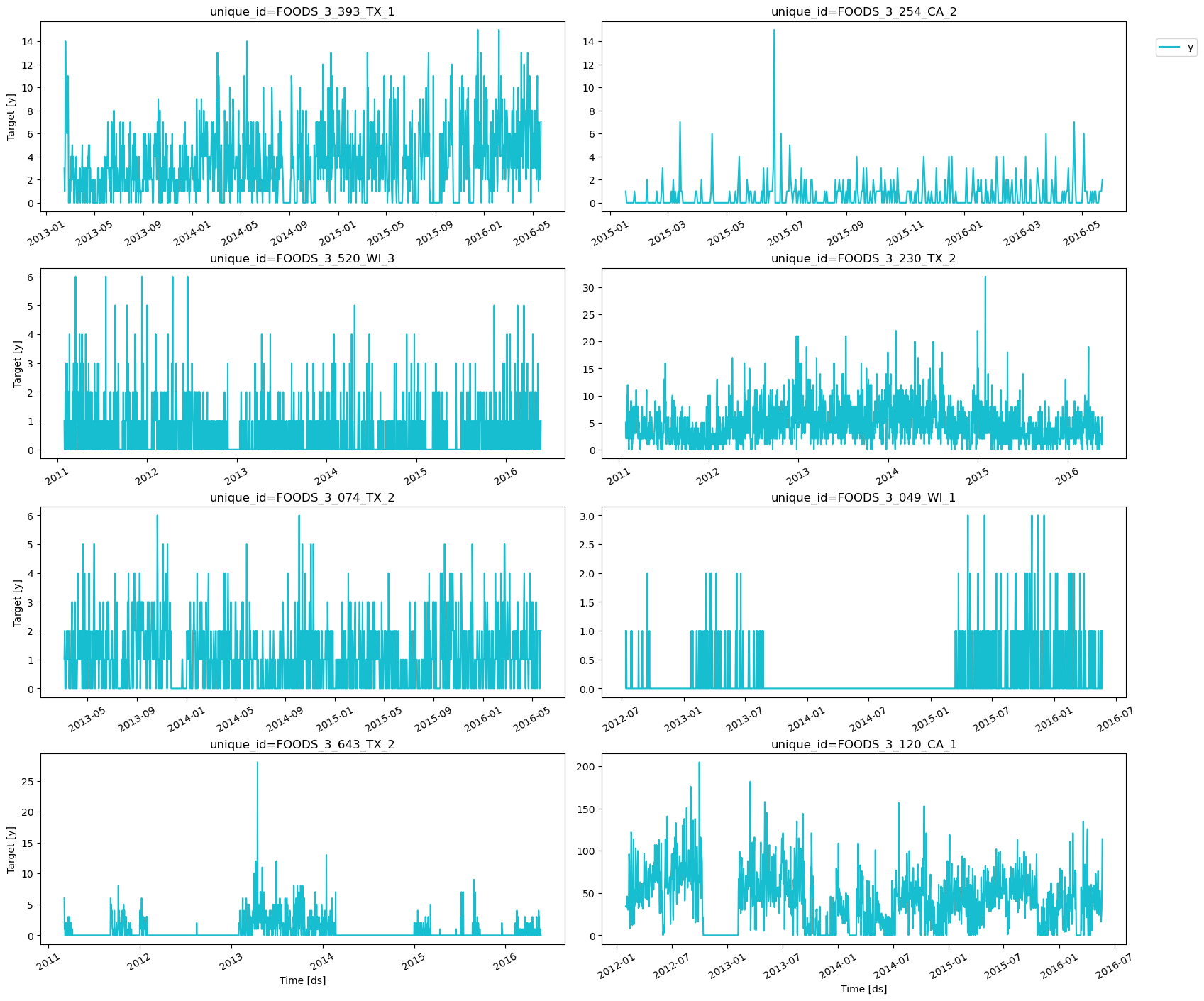
Basic Plotting
Plot some series using theplot_series function from the
utilsforecast library. This method prints 8 random series from the
dataset and is useful for basic EDA.
Create forecasts with Stats, Ml and Neural methods.
StatsForecast
StatsForecast is a comprehensive library providing a suite of popular
univariate time series forecasting models, all designed with a focus on
high performance and scalability.
Here’s what makes StatsForecast a powerful tool for time series
forecasting:
- Collection of Local Models: StatsForecast provides a diverse collection of local models that can be applied to each time series individually, allowing us to capture unique patterns within each series.
- Simplicity: With StatsForecast, training, forecasting, and backtesting multiple models become a straightforward process, requiring only a few lines of code. This simplicity makes it a convenient tool for both beginners and experienced practitioners.
- Optimized for Speed: The implementation of the models in StatsForecast is optimized for speed, ensuring that large-scale computations are performed efficiently, thereby reducing the overall time for model training and prediction.
- Horizontal Scalability: One of the distinguishing features of StatsForecast is its ability to scale horizontally. It is compatible with distributed computing frameworks such as Spark, Dask, and Ray. This feature allows it to handle large datasets by distributing the computations across multiple nodes in a cluster, making it a go-to solution for large-scale time series forecasting tasks.
StatsForecast receives a list of models to fit each time series. Since
we are dealing with Daily data, it would be benefitial to use 7 as
seasonality.
models: a list of models. Select the models you want from models and import them.freq: a string indicating the frequency of the data. (See panda’s available frequencies.)n_jobs: int, number of jobs used in the parallel processing, use -1 for all cores.fallback_model: a model to be used if a model fails. Any settings are passed into the constructor. Then you call its fit method and pass in the historical data frame.
h periods.
The forecast object here is a new data frame that includes a column with
the name of the model and the y hat values.
This block of code times how long it takes to run the forecasting
function of the StatsForecast class, which predicts the next 28 days
(h=28). The time is calculated in minutes and printed out at the end.
| unique_id | ds | SeasonalNaive | Naive | HistoricAverage | CrostonOptimized | ADIDA | IMAPA | AutoETS | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_3_001_CA_1 | 2016-05-23 | 1.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.381414 |
| 1 | FOODS_3_001_CA_1 | 2016-05-24 | 0.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.286933 |
| 2 | FOODS_3_001_CA_1 | 2016-05-25 | 0.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.334987 |
| 3 | FOODS_3_001_CA_1 | 2016-05-26 | 1.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.186851 |
| 4 | FOODS_3_001_CA_1 | 2016-05-27 | 0.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.308112 |
MLForecast
MLForecast is a powerful library that provides automated feature
creation for time series forecasting, facilitating the use of global
machine learning models. It is designed for high performance and
scalability.
Key features of MLForecast include:
- Support for sklearn models: MLForecast is compatible with models that follow the scikit-learn API. This makes it highly flexible and allows it to seamlessly integrate with a wide variety of machine learning algorithms.
- Simplicity: With MLForecast, the tasks of training, forecasting, and backtesting models can be accomplished in just a few lines of code. This streamlined simplicity makes it user-friendly for practitioners at all levels of expertise.
- Optimized for speed: MLForecast is engineered to execute tasks rapidly, which is crucial when handling large datasets and complex models.
- Horizontal Scalability: MLForecast is capable of horizontal scaling using distributed computing frameworks such as Spark, Dask, and Ray. This feature enables it to efficiently process massive datasets by distributing the computations across multiple nodes in a cluster, making it ideal for large-scale time series forecasting tasks.
MLForecast for time series forecasting, we instantiate a new
MLForecast object and provide it with various parameters to tailor the
modeling process to our specific needs:
-
models: This parameter accepts a list of machine learning models you wish to use for forecasting. You can import your preferred models from scikit-learn, lightgbm and xgboost. -
freq: This is a string indicating the frequency of your data (hourly, daily, weekly, etc.). The specific format of this string should align with pandas’ recognized frequency strings. -
target_transforms: These are transformations applied to the target variable before model training and after model prediction. This can be useful when working with data that may benefit from transformations, such as log-transforms for highly skewed data. -
lags: This parameter accepts specific lag values to be used as regressors. Lags represent how many steps back in time you want to look when creating features for your model. For example, if you want to use the previous day’s data as a feature for predicting today’s value, you would specify a lag of 1. -
lags_transforms: These are specific transformations for each lag. This allows you to apply transformations to your lagged features. -
date_features: This parameter specifies date-related features to be used as regressors. For instance, you might want to include the day of the week or the month as a feature in your model. -
num_threads: This parameter controls the number of threads to use for parallelizing feature creation, helping to speed up this process when working with large datasets.
MLForecast constructor. Once the
MLForecast object is initialized with these settings, we call its
fit method and pass the historical data frame as the argument. The
fit method trains the models on the provided historical data, readying
them for future forecasting tasks.
fit models to train the select models. In this case we
are generating conformal prediction intervals.
predict to generate forecasts.
| unique_id | ds | LGBMRegressor | XGBRegressor | LinearRegression | |
|---|---|---|---|---|---|
| 0 | FOODS_3_001_CA_1 | 2016-05-23 | 0.549520 | 0.560123 | 0.332693 |
| 1 | FOODS_3_001_CA_1 | 2016-05-24 | 0.553196 | 0.369337 | 0.055071 |
| 2 | FOODS_3_001_CA_1 | 2016-05-25 | 0.599668 | 0.374338 | 0.127144 |
| 3 | FOODS_3_001_CA_1 | 2016-05-26 | 0.638097 | 0.327176 | 0.101624 |
| 4 | FOODS_3_001_CA_1 | 2016-05-27 | 0.763305 | 0.331631 | 0.269863 |
NeuralForecast
NeuralForecast is a robust collection of neural forecasting models
that focuses on usability and performance. It includes a variety of
model architectures, from classic networks such as Multilayer
Perceptrons (MLP) and Recurrent Neural Networks (RNN) to novel
contributions like N-BEATS, N-HITS, Temporal Fusion Transformers (TFT),
and more.
Key features of NeuralForecast include:
- A broad collection of global models. Out of the box implementation of MLP, LSTM, RNN, TCN, DilatedRNN, NBEATS, NHITS, ESRNN, TFT, Informer, PatchTST and HINT.
- A simple and intuitive interface that allows training, forecasting, and backtesting of various models in a few lines of code.
- Support for GPU acceleration to improve computational speed.
| unique_id | ds | AutoNHITS | AutoNHITS-lo-90 | AutoNHITS-hi-90 | AutoTFT | AutoTFT-lo-90 | AutoTFT-hi-90 | |
|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_3_001_CA_1 | 2016-05-23 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 2.0 |
| 1 | FOODS_3_001_CA_1 | 2016-05-24 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 2.0 |
| 2 | FOODS_3_001_CA_1 | 2016-05-25 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 1.0 |
| 3 | FOODS_3_001_CA_1 | 2016-05-26 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 2.0 |
| 4 | FOODS_3_001_CA_1 | 2016-05-27 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 2.0 |
| unique_id | ds | SeasonalNaive | Naive | HistoricAverage | CrostonOptimized | ADIDA | IMAPA | AutoETS | AutoNHITS | AutoNHITS-lo-90 | AutoNHITS-hi-90 | AutoTFT | AutoTFT-lo-90 | AutoTFT-hi-90 | LGBMRegressor | XGBRegressor | LinearRegression | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_3_001_CA_1 | 2016-05-23 | 1.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.381414 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 2.0 | 0.549520 | 0.560123 | 0.332693 |
| 1 | FOODS_3_001_CA_1 | 2016-05-24 | 0.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.286933 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 2.0 | 0.553196 | 0.369337 | 0.055071 |
| 2 | FOODS_3_001_CA_1 | 2016-05-25 | 0.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.334987 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 1.0 | 0.599668 | 0.374338 | 0.127144 |
| 3 | FOODS_3_001_CA_1 | 2016-05-26 | 1.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.186851 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 2.0 | 0.638097 | 0.327176 | 0.101624 |
| 4 | FOODS_3_001_CA_1 | 2016-05-27 | 0.0 | 2.0 | 0.448738 | 0.345192 | 0.345477 | 0.347249 | 0.308112 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 2.0 | 0.763305 | 0.331631 | 0.269863 |
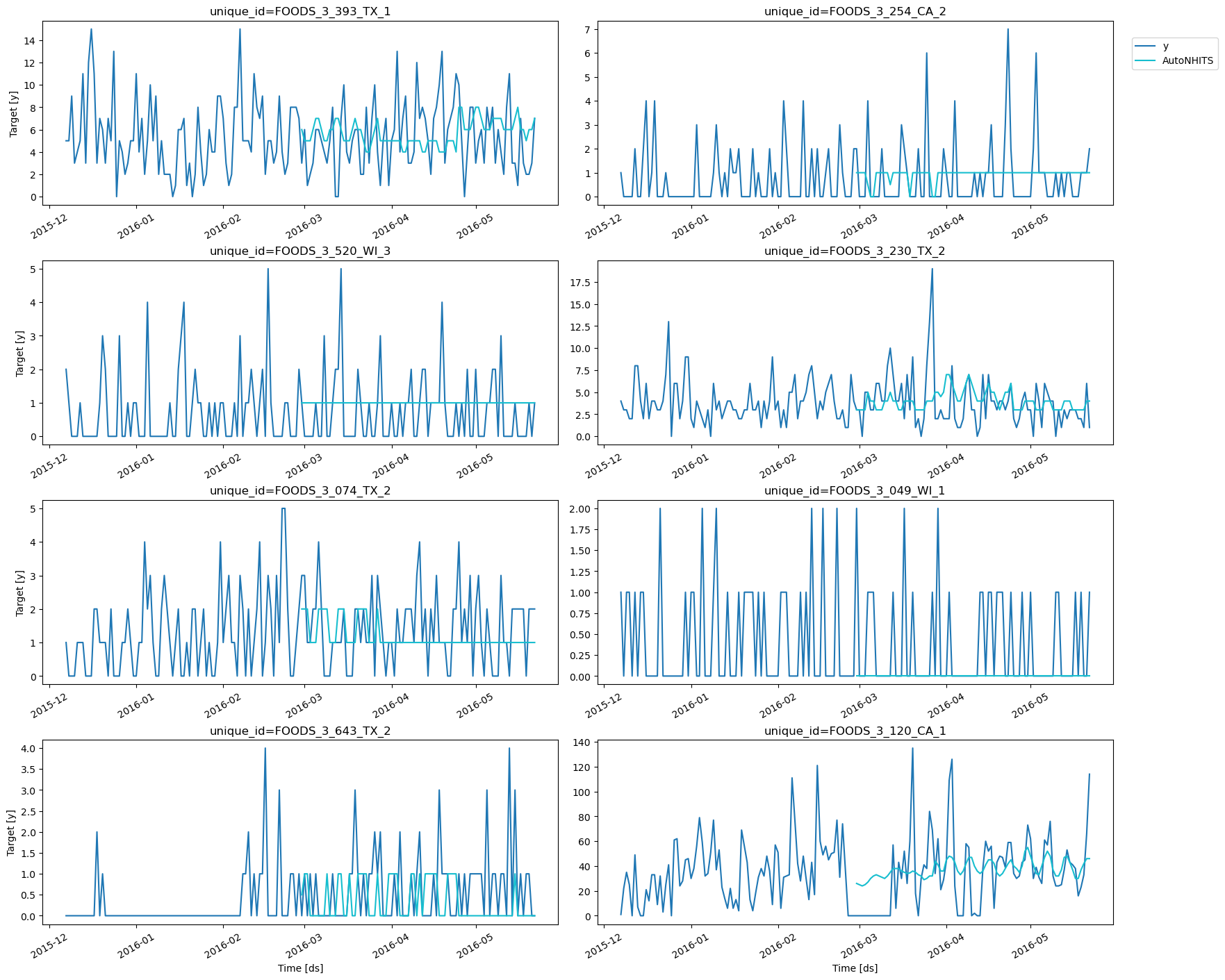
Forecast plots
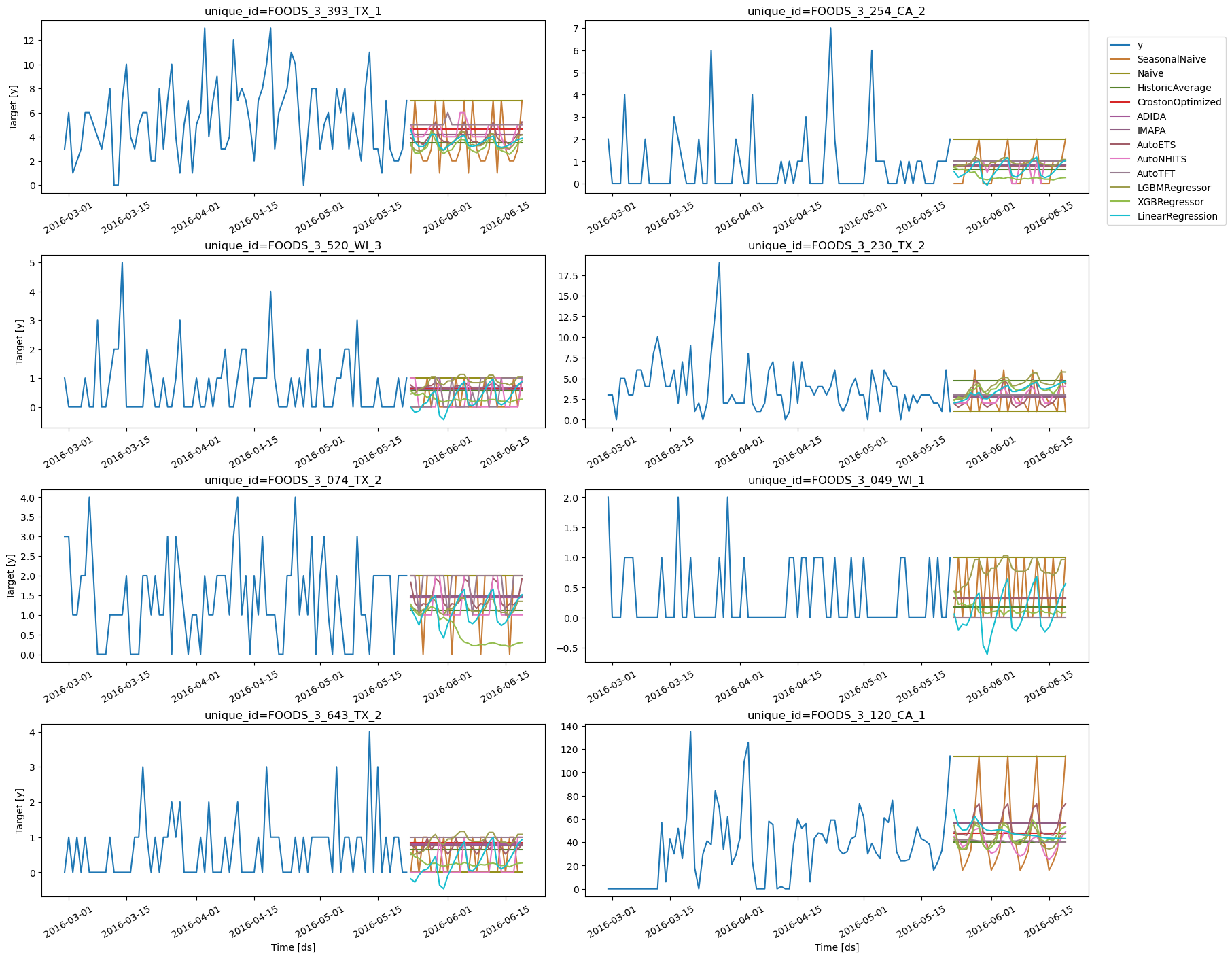
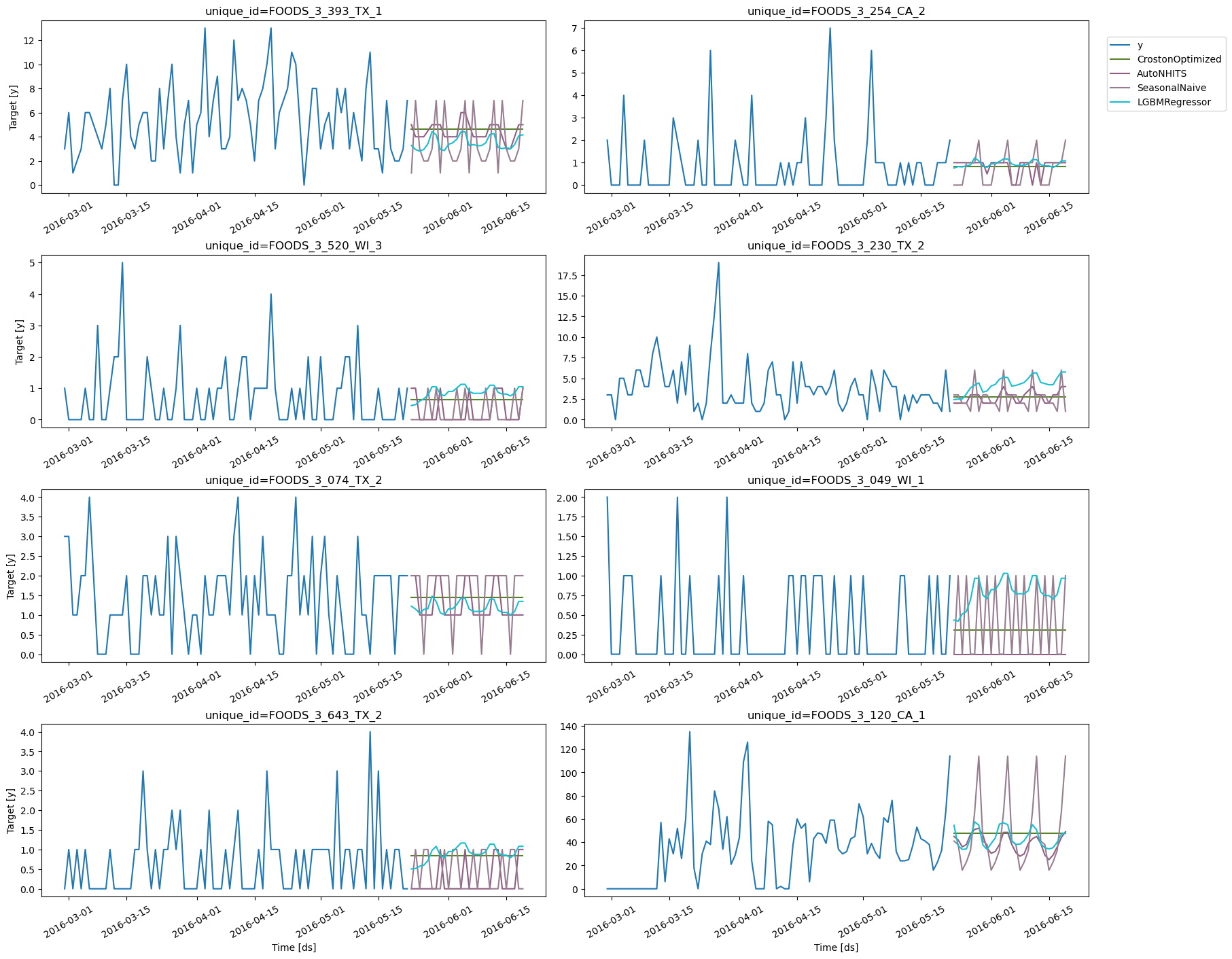
Validate Model’s Performance
The three libraries -StatsForecast, MLForecast, and
NeuralForecast - offer out-of-the-box cross-validation capabilities
specifically designed for time series. This allows us to evaluate the
model’s performance using historical data to obtain an unbiased
assessment of how well each model is likely to perform on unseen data.
Cross Validation in StatsForecast
Thecross_validation method from the StatsForecast class accepts the
following arguments:
df: A DataFrame representing the training data.h(int): The forecast horizon, represented as the number of steps into the future that we wish to predict. For example, if we’re forecasting hourly data,h=24would represent a 24-hour forecast.step_size(int): The step size between each cross-validation window. This parameter determines how often we want to run the forecasting process.n_windows(int): The number of windows used for cross validation. This parameter defines how many past forecasting processes we want to evaluate.
unique_idseries identifierds: datestamp or temporal indexcutoff: the last datestamp or temporal index for the n_windows. If n_windows=1, then one unique cuttoff value, if n_windows=2 then two unique cutoff values.y: true value"model": columns with the model’s name and fitted value.
| unique_id | ds | cutoff | y | SeasonalNaive | Naive | HistoricAverage | CrostonOptimized | ADIDA | IMAPA | AutoETS | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_3_001_CA_1 | 2016-02-29 | 2016-02-28 | 0.0 | 2.0 | 0.0 | 0.449111 | 0.618472 | 0.618375 | 0.617998 | 0.655286 |
| 1 | FOODS_3_001_CA_1 | 2016-03-01 | 2016-02-28 | 1.0 | 0.0 | 0.0 | 0.449111 | 0.618472 | 0.618375 | 0.617998 | 0.568595 |
| 2 | FOODS_3_001_CA_1 | 2016-03-02 | 2016-02-28 | 1.0 | 0.0 | 0.0 | 0.449111 | 0.618472 | 0.618375 | 0.617998 | 0.618805 |
| 3 | FOODS_3_001_CA_1 | 2016-03-03 | 2016-02-28 | 0.0 | 1.0 | 0.0 | 0.449111 | 0.618472 | 0.618375 | 0.617998 | 0.455891 |
| 4 | FOODS_3_001_CA_1 | 2016-03-04 | 2016-02-28 | 0.0 | 1.0 | 0.0 | 0.449111 | 0.618472 | 0.618375 | 0.617998 | 0.591197 |
MLForecast
Thecross_validation method from the MLForecast class takes the
following arguments.
df: training data frameh(int): represents the steps into the future that are being forecasted. In this case, 24 hours ahead.step_size(int): step size between each window. In other words: how often do you want to run the forecasting processes.n_windows(int): number of windows used for cross-validation. In other words: what number of forecasting processes in the past do you want to evaluate.
unique_idseries identifierds: datestamp or temporal indexcutoff: the last datestamp or temporal index for the n_windows. If n_windows=1, then one unique cuttoff value, if n_windows=2 then two unique cutoff values.y: true value"model": columns with the model’s name and fitted value.
| unique_id | ds | cutoff | y | LGBMRegressor | XGBRegressor | LinearRegression | |
|---|---|---|---|---|---|---|---|
| 0 | FOODS_3_001_CA_1 | 2016-02-29 | 2016-02-28 | 0.0 | 0.435674 | 0.556261 | -0.353077 |
| 1 | FOODS_3_001_CA_1 | 2016-03-01 | 2016-02-28 | 1.0 | 0.639676 | 0.625807 | -0.088985 |
| 2 | FOODS_3_001_CA_1 | 2016-03-02 | 2016-02-28 | 1.0 | 0.792989 | 0.659651 | 0.217697 |
| 3 | FOODS_3_001_CA_1 | 2016-03-03 | 2016-02-28 | 0.0 | 0.806868 | 0.535121 | 0.438713 |
| 4 | FOODS_3_001_CA_1 | 2016-03-04 | 2016-02-28 | 0.0 | 0.829106 | 0.313354 | 0.637066 |
NeuralForecast
This machine doesn’t have GPU, but Google Colabs offers some for free. Using Colab’s GPU to train NeuralForecast.| unique_id | ds | cutoff | AutoNHITS | AutoNHITS-lo-90 | AutoNHITS-hi-90 | AutoTFT | AutoTFT-lo-90 | AutoTFT-hi-90 | y | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_3_001_CA_1 | 2016-02-29 | 2016-02-28 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 2.0 | 0.0 |
| 1 | FOODS_3_001_CA_1 | 2016-03-01 | 2016-02-28 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 2.0 | 1.0 |
| 2 | FOODS_3_001_CA_1 | 2016-03-02 | 2016-02-28 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 2.0 | 1.0 |
| 3 | FOODS_3_001_CA_1 | 2016-03-03 | 2016-02-28 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 2.0 | 0.0 |
| 4 | FOODS_3_001_CA_1 | 2016-03-04 | 2016-02-28 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 2.0 | 0.0 |
Merge cross validation forecasts
Plots CV



Aggregate Demand



Evaluation per series and CV window
In this section, we will evaluate the performance of each model for each time series.| unique_id | metric | SeasonalNaive | Naive | HistoricAverage | CrostonOptimized | ADIDA | IMAPA | AutoETS | AutoNHITS | AutoTFT | LGBMRegressor | XGBRegressor | LinearRegression | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_3_001_CA_1 | mse | 1.250000 | 0.892857 | 0.485182 | 0.507957 | 0.509299 | 0.516988 | 0.494235 | 0.630952 | 0.571429 | 0.648962 | 0.584722 | 0.529400 |
| 1 | FOODS_3_001_CA_2 | mse | 6.273809 | 3.773809 | 3.477309 | 3.412580 | 3.432295 | 3.474050 | 3.426468 | 4.550595 | 3.607143 | 3.423646 | 3.856465 | 3.773264 |
| 2 | FOODS_3_001_CA_3 | mse | 5.880952 | 4.357143 | 5.016396 | 4.173154 | 4.160645 | 4.176733 | 4.145148 | 4.005952 | 4.372024 | 4.928764 | 6.937792 | 5.317195 |
| 3 | FOODS_3_001_CA_4 | mse | 1.071429 | 0.476190 | 0.402938 | 0.382559 | 0.380783 | 0.380877 | 0.380872 | 0.476190 | 0.476190 | 0.664270 | 0.424068 | 0.637221 |
| 4 | FOODS_3_001_TX_1 | mse | 0.047619 | 0.047619 | 0.238824 | 0.261356 | 0.047619 | 0.047619 | 0.077575 | 0.047619 | 0.047619 | 0.718796 | 0.063564 | 0.187810 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 24685 | FOODS_3_827_TX_2 | smape | 0.083333 | 0.035714 | 0.989540 | 0.996362 | 0.987395 | 0.982847 | 0.981537 | 0.323810 | 0.335714 | 0.976356 | 0.994702 | 0.985058 |
| 24686 | FOODS_3_827_TX_3 | smape | 0.708532 | 0.681495 | 0.662490 | 0.653057 | 0.655810 | 0.660161 | 0.649180 | 0.683947 | 0.712121 | 0.639518 | 0.856866 | 0.686547 |
| 24687 | FOODS_3_827_WI_1 | smape | 0.608722 | 0.694328 | 0.470570 | 0.470846 | 0.480032 | 0.480032 | 0.466956 | 0.486852 | 0.475980 | 0.472336 | 0.484906 | 0.492277 |
| 24688 | FOODS_3_827_WI_2 | smape | 0.531777 | 0.398156 | 0.433577 | 0.387718 | 0.388827 | 0.389371 | 0.389888 | 0.393774 | 0.374640 | 0.413559 | 0.430893 | 0.399131 |
| 24689 | FOODS_3_827_WI_3 | smape | 0.643689 | 0.680178 | 0.588031 | 0.589143 | 0.599820 | 0.628673 | 0.591437 | 0.558201 | 0.567460 | 0.589870 | 0.698798 | 0.627255 |
| SeasonalNaive | Naive | HistoricAverage | CrostonOptimized | ADIDA | IMAPA | AutoETS | AutoNHITS | AutoTFT | LGBMRegressor | XGBRegressor | LinearRegression | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| metric | ||||||||||||
| mae | 1.775415 | 2.045906 | 1.749080 | 1.634791 | 1.542097 | 1.543745 | 1.511545 | 1.438250 | 1.497647 | 1.697947 | 1.552061 | 1.592978 |
| mse | 14.265773 | 20.453325 | 12.938136 | 11.484233 | 11.090195 | 11.094446 | 10.351927 | 9.606913 | 10.721251 | 10.502289 | 11.565916 | 10.830894 |
| smape | 0.436414 | 0.446430 | 0.616884 | 0.613219 | 0.618910 | 0.619313 | 0.620084 | 0.400770 | 0.411018 | 0.579856 | 0.693615 | 0.641515 |
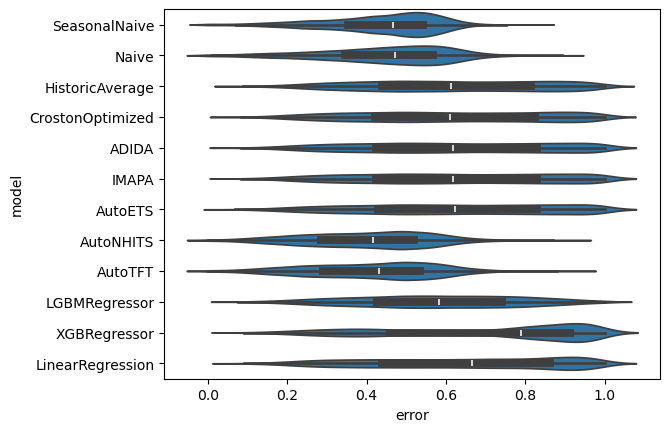
Distribution of errors
SMAPE
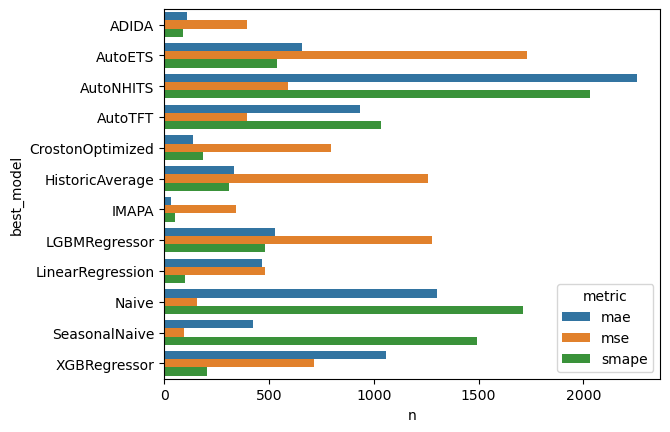
Choose models for groups of series
Feature:- A unified dataframe with forecasts for all different models
- Easy Ensamble
- E.g. Average predictions
- Or MinMax (Choosing is ensembling)
Et pluribus unum: an inclusive forecasting Pie.
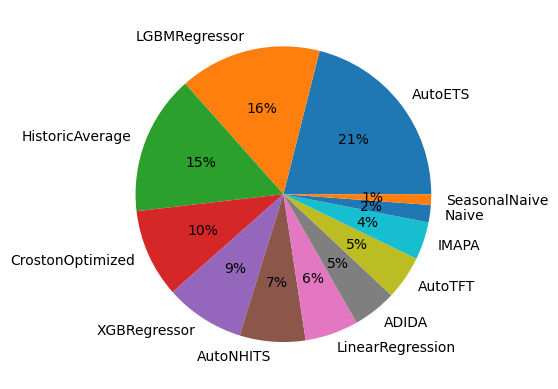
Choose Forecasting method for different groups of series