

A minimal example of using Hierarchical Forecast with NeuralForecastThis notebook offers a step by step guide to create a hierarchical forecasting pipeline. In the pipeline we will use
NeuralForecast and HINT class, to create
fit, predict and reconcile forecasts.
We will use the TourismL dataset that summarizes large Australian
national visitor survey.
Outline1. Installing packages
2. Load hierarchical dataset
3. Fit and Predict HINT
4. Benchmark methods
5. Forecast Evaluation You can run these experiments using GPU with Google Colab.
1. Installing packages
2. Load hierarchical dataset
This detailed Australian Tourism Dataset comes from the National Visitor Survey, managed by the Tourism Research Australia, it is composed of 555 monthly series from 1998 to 2016, it is organized geographically, and purpose of travel. The natural geographical hierarchy comprises seven states, divided further in 27 zones and 76 regions. The purpose of travel categories are holiday, visiting friends and relatives (VFR), business and other. The MinT (Wickramasuriya et al., 2019), among other hierarchical forecasting studies has used the dataset it in the past. The dataset can be accessed in the MinT reconciliation webpage, although other sources are available.| Geographical Division | Number of series per division | Number of series per purpose | Total |
|---|---|---|---|
| Australia | 1 | 4 | 5 |
| States | 7 | 28 | 35 |
| Zones | 27 | 108 | 135 |
| Regions | 76 | 304 | 380 |
| Total | 111 | 444 | 555 |
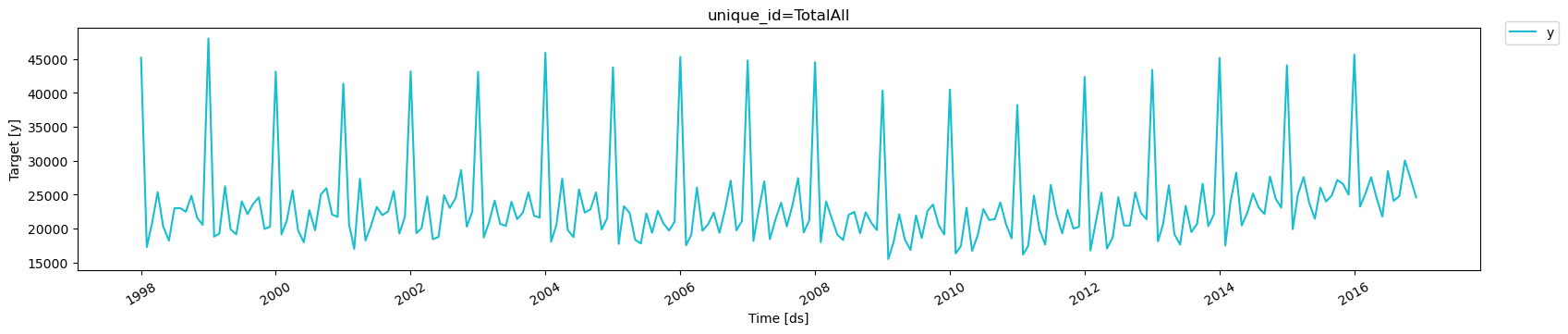
3. Fit and Predict HINT
The Hierarchical Forecast Network (HINT) combines into an easy to use model three components:1. SoTA neural forecast model.
2. An efficient and flexible multivariate probability distribution.
3. Builtin reconciliation capabilities.
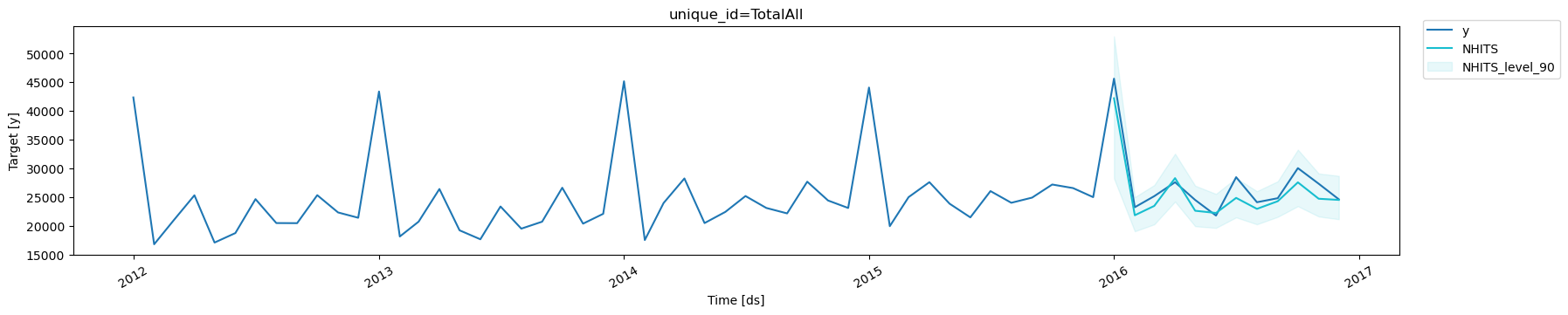
4. Benchmark methods
We compare against AutoARIMA, a well-established traditional forecasting method from the StatsForecast package, for which we reconcile the forecasts using HierarchicalForecast.BottomUp and MinTrace
reconciliation techniques:
5. Forecast Evaluation
To evaluate the coherent probabilistic predictions we use the scaled Continuous Ranked Probability Score (sCRPS), defined as follows: As you can see the HINT model (using NHITS as base model) efficiently achieves state of the art accuracy under minimal tuning.| level | metric | NHITS | AutoARIMA | |
|---|---|---|---|---|
| 0 | Country | scaled_crps | 0.044431 | 0.131136 |
| 1 | Country/State | scaled_crps | 0.063411 | 0.147516 |
| 2 | Country/State/Zone | scaled_crps | 0.106060 | 0.174071 |
| 3 | Country/State/Zone/Region | scaled_crps | 0.151988 | 0.205654 |
| 4 | Country/Purpose | scaled_crps | 0.075821 | 0.133664 |
| 5 | Country/State/Purpose | scaled_crps | 0.114674 | 0.181850 |
| 6 | Country/State/Zone/Purpose | scaled_crps | 0.180491 | 0.244324 |
| 7 | Country/State/Zone/Region/Purpose | scaled_crps | 0.245466 | 0.310656 |
| 8 | Overall | scaled_crps | 0.122793 | 0.191109 |
References
- Kin G. Olivares, David Luo, Cristian Challu, Stefania La Vattiata,
Max Mergenthaler, Artur Dubrawski (2023). “HINT: Hierarchical
Mixture Networks For Coherent Probabilistic Forecasting”.
International Conference on Machine Learning (ICML). Workshop on
Structured Probabilistic Inference & Generative Modeling. Available
at
https://arxiv.org/abs/2305.07089.
- Kin G. Olivares, O. Nganba Meetei, Ruijun Ma, Rohan Reddy, Mengfei
Cao, Lee Dicker (2023).”Probabilistic Hierarchical Forecasting with
Deep Poisson Mixtures”. International Journal Forecasting, accepted
paper. URL
https://arxiv.org/pdf/2110.13179.pdf.
- Kin G. Olivares, Federico Garza, David Luo, Cristian Challu, Max Mergenthaler, Souhaib Ben Taieb, Shanika Wickramasuriya, and Artur Dubrawski (2023). “HierarchicalForecast: A reference framework for hierarchical forecasting”. Journal of Machine Learning Research, submitted. URL https://arxiv.org/abs/2207.03517