

In this notebook, we’ll implement models for intermittent or sparse data using the M5 dataset.Intermittent or sparse data has very few non-zero observations. This type of data is hard to forecast because the zero values increase the uncertainty about the underlying patterns in the data. Furthermore, once a non-zero observation occurs, there can be considerable variation in its size. Intermittent time series are common in many industries, including finance, retail, transportation, and energy. Given the ubiquity of this type of series, special methods have been developed to forecast them. The first was from Croston (1972), followed by several variants and by different aggregation frameworks. The models of NeuralForecast can be trained to model sparse or intermittent time series using a
Poisson
distribution loss. By the end of this tutorial, you’ll have a good
understanding of these models and how to use them.
Outline:
- Install libraries
- Load and explore the data
- Train models for intermittent data
- Perform Cross Validation
Tip You can use Colab to run this Notebook interactively
Warning
To reduce the computation time, it is recommended to use GPU. Using
Colab, do not forget to activate it. Just go to
Runtime>Change runtime type and select GPU as hardware accelerator.
1. Install libraries
We assume that you have NeuralForecast already installed. If not, check this guide for instructions on how to install NeuralForecast Install the necessary packages usingpip install neuralforecast
2. Load and explore the data
For this example, we’ll use a subset of the M5 Competition dataset. Each time series represents the unit sales of a particular product in a given Walmart store. At this level (product-store), most of the data is intermittent. We first need to import the data.StatsForecast class.
This method prints 8 random series from the dataset and is useful for
basic
EDA.

3. Train models for intermittent data
Auto model contains a default search space that was extensively
tested on multiple large-scale datasets. Additionally, users can define
specific search spaces tailored for particular datasets and tasks.
First, we create a custom search space for the AutoNHITS and AutoTFT
models. Search spaces are specified with dictionaries, where keys
corresponds to the model’s hyperparameter and the value is a Tune
function to specify how the hyperparameter will be sampled. For example,
use randint to sample integers uniformly, and choice to sample
values of a list.
Auto model you need to define:
h: forecasting horizon.loss: training and validation loss fromneuralforecast.losses.pytorch.config: hyperparameter search space. IfNone, theAutoclass will use a pre-defined suggested hyperparameter space.search_alg: search algorithm (fromtune.search), default is random search. Refer to https://docs.ray.io/en/latest/tune/api_docs/suggestion.html for more information on the different search algorithm options.num_samples: number of configurations explored.
h as 28, use the Poisson distribution
loss (ideal for count data) for training and validation, and use the
default search algorithm.
Tip The number of samples,Next, we use thenum_samples, is a crucial parameter! Larger values will usually produce better results as we explore more configurations in the search space, but it will increase training times. Larger search spaces will usually require more samples. As a general rule, we recommend settingnum_sampleshigher than 20.
Neuralforecast class to train the Auto model. In
this step, Auto models will automatically perform hyperparamter tuning
training multiple models with different hyperparameters, producing the
forecasts on the validation set, and evaluating them. The best
configuration is selected based on the error on a validation set. Only
the best model is stored and used during inference.
predict method to forecast the next 28 days using the
optimal hyperparameters.
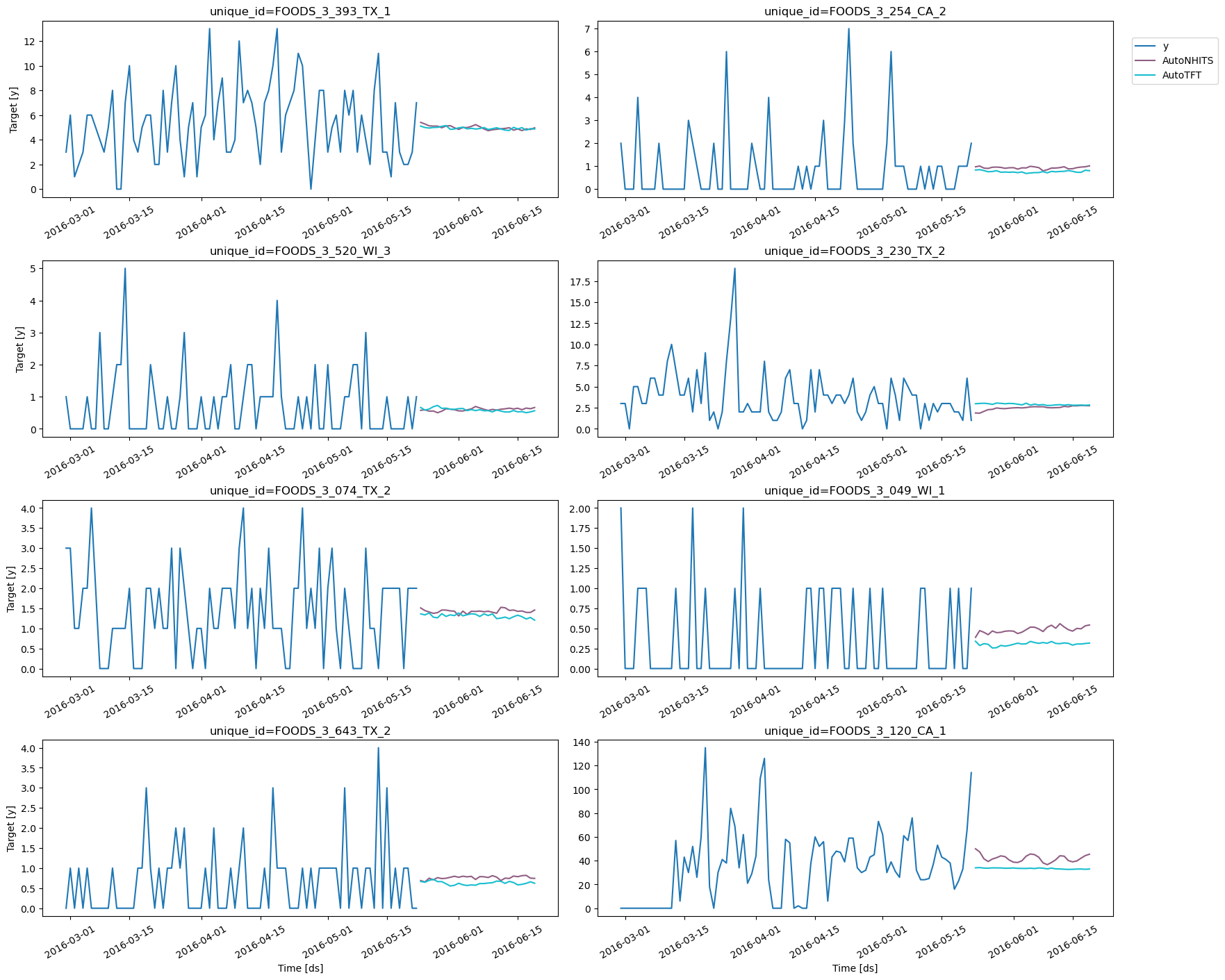
4. Cross Validation
Time series cross-validation is a method for evaluating how a model would have performed in the past. It works by defining a sliding window across the historical data and predicting the period following it. NeuralForecast has an
implementation of time series cross-validation that is fast and easy to
use.
The
NeuralForecast has an
implementation of time series cross-validation that is fast and easy to
use.
The cross_validation method from the NeuralForecast class takes the
following arguments.
df: training data framestep_size(int): step size between each window. In other words: how often do you want to run the forecasting processes.n_windows(int): number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
cv_df object is a new data frame that includes the following
columns:
unique_id: contains the id corresponding to the time seriesds: datestamp or temporal indexcutoff: the last datestamp or temporal index for the n_windows. If n_windows=1, then one unique cuttoff value, if n_windows=2 then two unique cutoff values.y: true value"model": columns with the model’s name and fitted value.



Evaluate
In this section we will evaluate the performance of each model each cross validation window using the MSE metric.References
- Croston, J. D. (1972). Forecasting and stock control for intermittent demands. Journal of the Operational Research Society, 23(3), 289-303.
- Cristian Challu, Kin G. Olivares, Boris N. Oreshkin, Federico Garza, Max Mergenthaler-Canseco, Artur Dubrawski (2021). N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting. Accepted at AAAI 2023.