

- Installing NeuralForecast.
- Loading Noisy AirPassengers.
- Fit and predict robustified NeuralForecast.
- Plot and evaluate predictions.
You can run these experiments using GPU with Google Colab.
1. Installing NeuralForecast
2. Loading Noisy AirPassengers
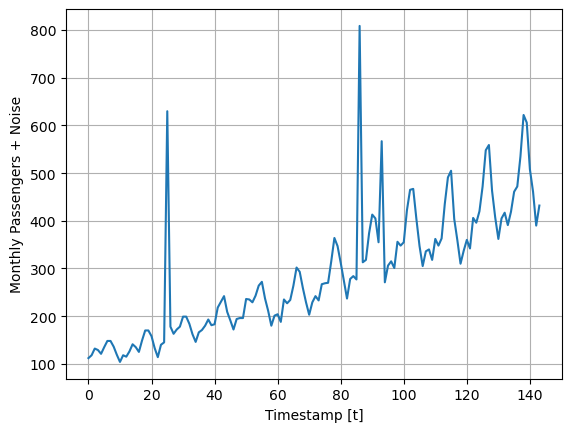
For this example we will use the classic Box-Cox AirPassengers dataset that we will augment it by introducing outliers. In particular, we will focus on introducing outliers to the target variable altering it to deviate from its original observation by a specified factor, such as 2-to-4 times the standard deviation.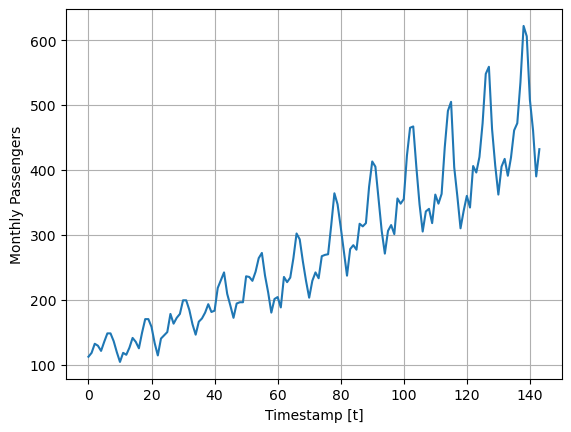
3. Fit and predict robustified NeuralForecast
Huber MQ Loss
The Huber loss, employed in robust regression, is a loss function that exhibits reduced sensitivity to outliers in data when compared to the squared error loss. The Huber loss function is quadratic for small errors and linear for large errors. Here we will use a slight modification for probabilistic predictions. Feel free to play with the parameter.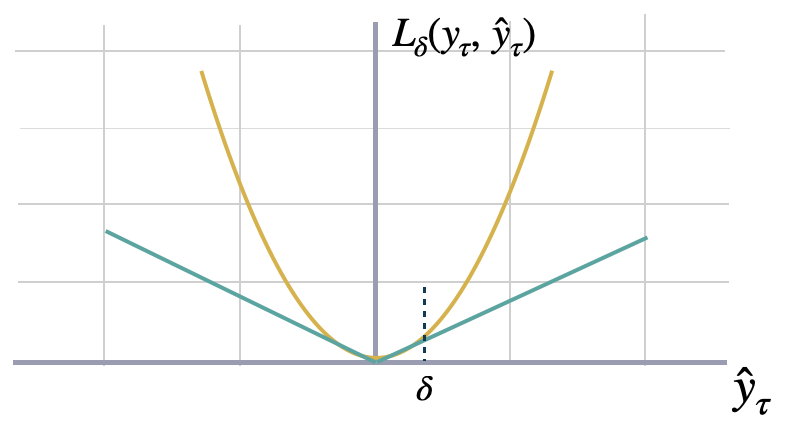
Dropout Regularization
The dropout technique is a regularization method used in neural networks to prevent overfitting. During training, dropout randomly sets a fraction of the input units or neurons in a layer to zero at each update, effectively “dropping out” those units. This means that the network cannot rely on any individual unit because it may be dropped out at any time. By doing so, dropout forces the network to learn more robust and generalizable representations by preventing units from co-adapting too much. The dropout method, can help us to robustify the network to outliers in the auto-regressive features. You can explore it through thedropout_prob_theta parameter.
Fit NeuralForecast models
Using theNeuralForecast.fit method you can train a set of models to
your dataset. You can define the forecasting horizon (12 in this
example), and modify the hyperparameters of the model. For example, for
the NHITS we changed the default hidden size for both encoder and
decoders.
See the NHITS and MLP model
documentation.
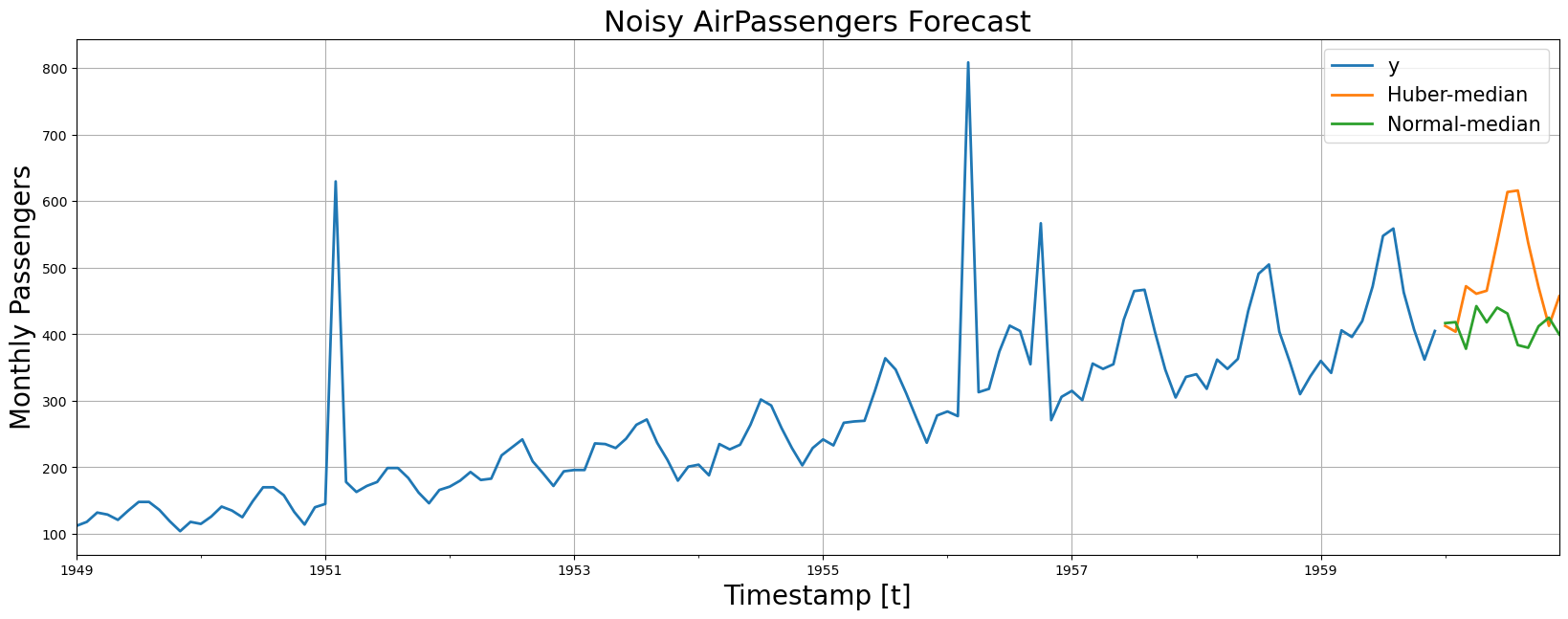
4. Plot and Evaluate Predictions
Finally, we plot the forecasts of both models against the real values. And evaluate the accuracy of theNHITS-Huber and NHITS-Normal
forecasters.
References
- Huber Peter, J (1964). “Robust Estimation of a Location Parameter”.
Annals of
Statistics.
- Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya
Sutskever, Ruslan Salakhutdinov (2014).”Dropout: A Simple Way to
Prevent Neural Networks from Overfitting”. Journal of Machine
Learning
Research.
- Cristian Challu, Kin G. Olivares, Boris N. Oreshkin, Federico Garza, Max Mergenthaler-Canseco, Artur Dubrawski (2023). NHITS: Neural Hierarchical Interpolation for Time Series Forecasting. Accepted at AAAI 2023.