

Explore transfer learning for time series forecastingTransfer learning refers to the process of pre-training a flexible model on a large dataset and using it later on other data with little to no training. It is one of the most outstanding 🚀 achievements in Machine Learning 🧠 and has many practical applications. For time series forecasting, the technique allows you to get lightning-fast predictions ⚡ bypassing the tradeoff between accuracy and speed (more than 30 times faster than our already fast autoARIMA for a similar accuracy). This notebook shows how to generate a pre-trained model and store it in a checkpoint to make it available to forecast new time series never seen by the model. Table of Contents
1. Installing NeuralForecast/DatasetsForecast
2. Load M4 Data
3. Instantiate NeuralForecast core, Fit, and save
4. Load pre-trained model and predict on AirPassengers
5. Evaluate Results
You can run these experiments using GPU with Google Colab.
1. Installing Libraries
2. Load M4 Data
TheM4 class will automatically download the complete M4 dataset and
process it.
It return three Dataframes: Y_df contains the values for the target
variables, X_df contains exogenous calendar features and S_df
contains static features for each time-series (none for M4). For this
example we will only use Y_df.
If you want to use your own data just replace Y_df. Be sure to use a
long format and have a similar structure to our data set.
| unique_id | ds | y | |
|---|---|---|---|
| 0 | M1 | 1970-01-01 00:00:00.000000001 | 8000.0 |
| 1 | M1 | 1970-01-01 00:00:00.000000002 | 8350.0 |
| 2 | M1 | 1970-01-01 00:00:00.000000003 | 8570.0 |
| 3 | M1 | 1970-01-01 00:00:00.000000004 | 7700.0 |
| 4 | M1 | 1970-01-01 00:00:00.000000005 | 7080.0 |
| … | … | … | … |
| 11246406 | M9999 | 1970-01-01 00:00:00.000000083 | 4200.0 |
| 11246407 | M9999 | 1970-01-01 00:00:00.000000084 | 4300.0 |
| 11246408 | M9999 | 1970-01-01 00:00:00.000000085 | 3800.0 |
| 11246409 | M9999 | 1970-01-01 00:00:00.000000086 | 4400.0 |
| 11246410 | M9999 | 1970-01-01 00:00:00.000000087 | 4300.0 |
3. Model Train and Save
Using theNeuralForecast.fit method you can train a set of models to
your dataset. You just have to define the input_size and horizon of
your model. The input_size is the number of historic observations
(lags) that the model will use to learn to predict h steps in the
future. Also, you can modify the hyperparameters of the model to get a
better accuracy.
core.NeuralForecast.save method. This method uses
PytorchLightning save_checkpoint function. We set save_dataset=False
to only save the model.
4. Transfer M4 to AirPassengers
We load the stored model with thecore.NeuralForecast.load method, and
forecast AirPassenger with the core.NeuralForecast.predict function.
| unique_id | ds | NHITS | |
|---|---|---|---|
| 0 | 1.0 | 1960-01-31 | 422.038757 |
| 1 | 1.0 | 1960-02-29 | 424.678040 |
| 2 | 1.0 | 1960-03-31 | 439.538879 |
| 3 | 1.0 | 1960-04-30 | 447.967072 |
| 4 | 1.0 | 1960-05-31 | 470.603333 |
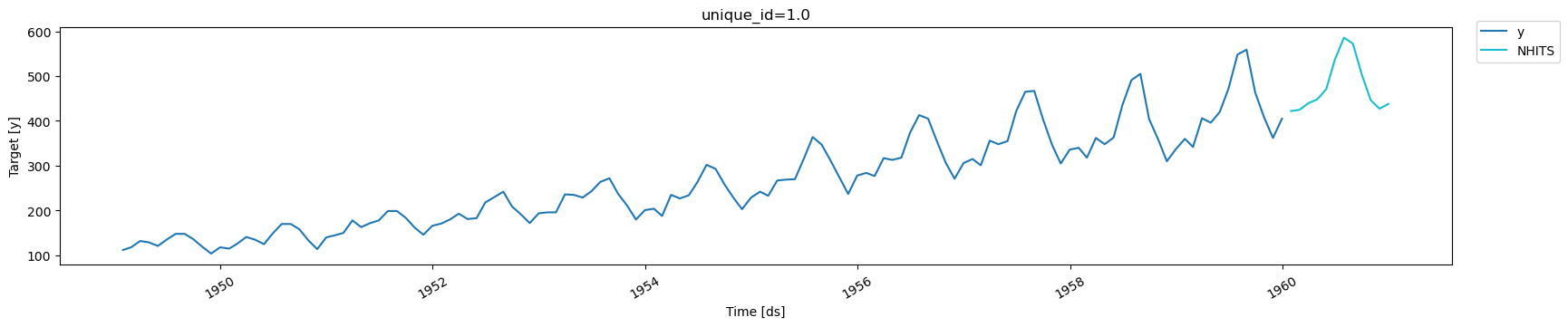
5. Evaluate Results
We evaluate the forecasts of the pre-trained model with the Mean Absolute Error (mae).