Model training, evaluation and selection for multiple time series
Prerequesites This Guide assumes basic familiarity with NeuralForecast. For a minimal example visit the Quick StartFollow this article for a step to step guide on building a production-ready forecasting pipeline for multiple time series. During this guide you will gain familiarity with the core
NeuralForecastclass and some relevant methods like
NeuralForecast.fit, NeuralForecast.predict, and
StatsForecast.cross_validation.
We will use a classical benchmarking dataset from the M4 competition.
The dataset includes time series from different domains like finance,
economy and sales. In this example, we will use a subset of the Hourly
dataset.
We will model each time series globally Therefore, you will train a set
of models for the whole dataset, and then select the best model for each
individual time series. NeuralForecast focuses on speed, simplicity, and
scalability, which makes it ideal for this task.
Outline:
- Install packages.
- Read the data.
- Explore the data.
- Train many models globally for the entire dataset.
- Evaluate the model’s performance using cross-validation.
- Select the best model for every unique time series.
Not Covered in this guide
- Using external regressors or exogenous variables
- Follow this tutorial to include exogenous variables like weather or holidays or static variables like category or family.
- Probabilistic forecasting
- Follow this tutorial to generate probabilistic forecasts
- Transfer Learning
- Train a model and use it to forecast on different data using this tutorial
Tip You can use Colab to run this Notebook interactively
Warning
To reduce the computation time, it is recommended to use GPU. Using
Colab, do not forget to activate it. Just go to
Runtime>Change runtime type and select GPU as hardware accelerator.
1. Install libraries
We assume you haveNeuralForecast already installed. Check this guide
for instructions on how to install
NeuralForecast.
2. Read the data
We will use pandas to read the M4 Hourly data set stored in a parquet file for efficiency. You can use ordinary pandas operations to read your data in other formats likes.csv.
The input to NeuralForecast is always a data frame in long
format with
three columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp or int) column should be either an integer indexing time or a datestampe ideally like YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast. We will rename the
This dataset contains 414 unique series with 900 observations on
average. For this example and reproducibility’s sake, we will select
only 10 unique IDs. Depending on your processing infrastructure feel
free to select more or less series.
Note Processing time is dependent on the available computing resources. Running this example with the complete dataset takes around 10 minutes in a c5d.24xlarge (96 cores) instance from AWS.
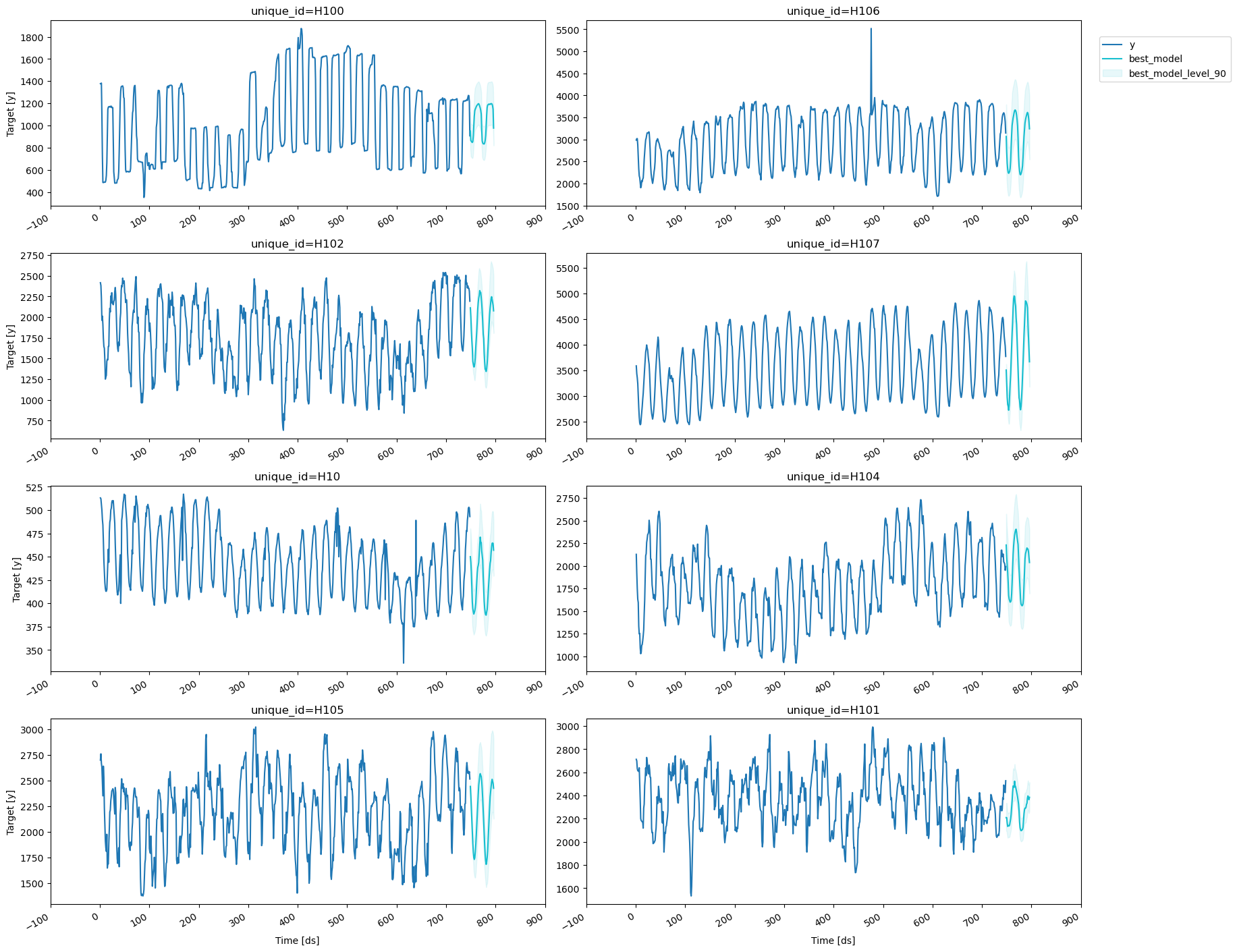
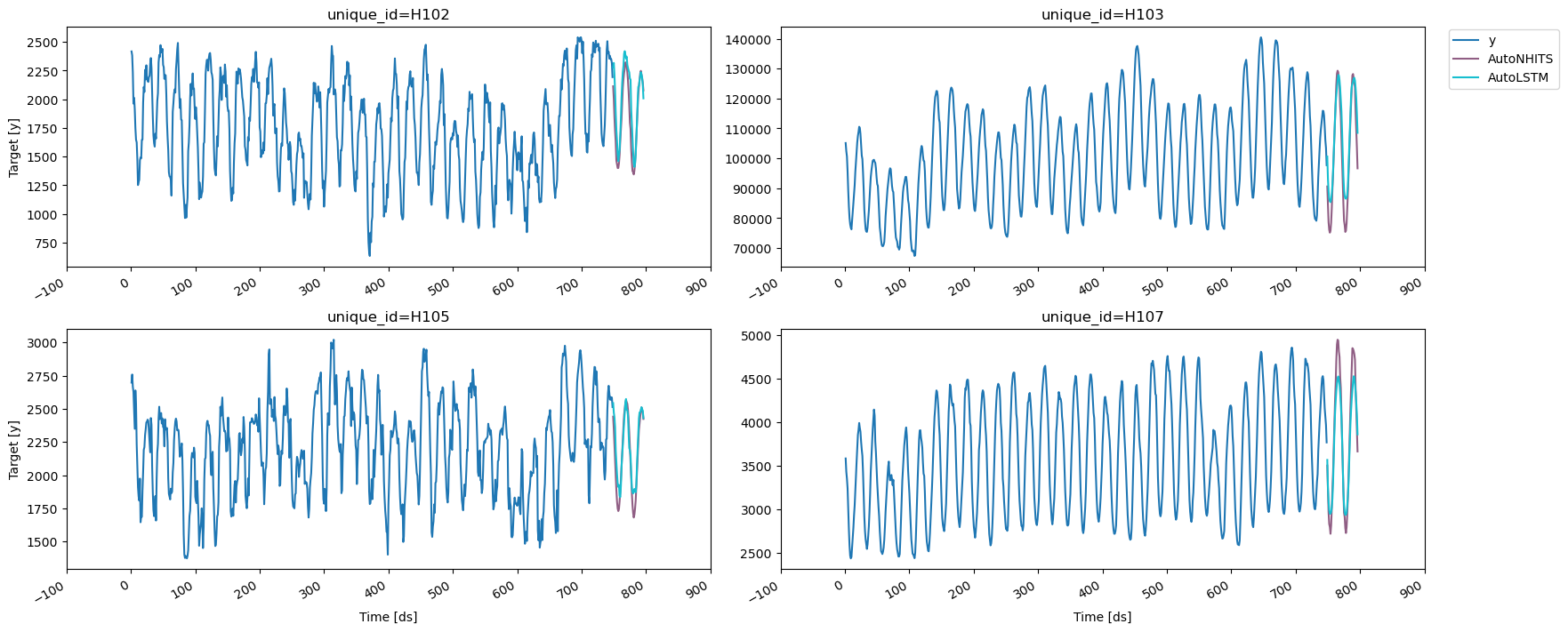
3. Explore Data with the plot_series function
Plot some series using theplot_series function from the
utilsforecast library. This method prints 8 random series from the
dataset and is useful for basic EDA.
Note Theplot_seriesfunction uses matplotlib as a default engine. You can change to plotly by settingengine="plotly".
4. Train multiple models for many series
NeuralForecast can train many models on many time series globally and
efficiently.
Auto model contains a default search space that was extensively
tested on multiple large-scale datasets. Additionally, users can define
specific search spaces tailored for particular datasets and tasks.
First, we create a custom search space for the AutoNHITS and
AutoLSTM models. Search spaces are specified with dictionaries, where
keys corresponds to the model’s hyperparameter and the value is a Tune
function to specify how the hyperparameter will be sampled. For example,
use randint to sample integers uniformly, and choice to sample
values of a list.
Auto model you need to define:
h: forecasting horizon.loss: training and validation loss fromneuralforecast.losses.pytorch.config: hyperparameter search space. IfNone, theAutoclass will use a pre-defined suggested hyperparameter space.search_alg: search algorithmnum_samples: number of configurations explored.
h as 48, use the MQLoss distribution
loss for training and validation, and use the default search algorithm.
Tip The number of samples,Next, we use thenum_samples, is a crucial parameter! Larger values will usually produce better results as we explore more configurations in the search space, but it will increase training times. Larger search spaces will usually require more samples. As a general rule, we recommend settingnum_sampleshigher than 20.
Neuralforecast class to train the Auto model. In
this step, Auto models will automatically perform hyperparameter
tuning training multiple models with different hyperparameters,
producing the forecasts on the validation set, and evaluating them. The
best configuration is selected based on the error on a validation set.
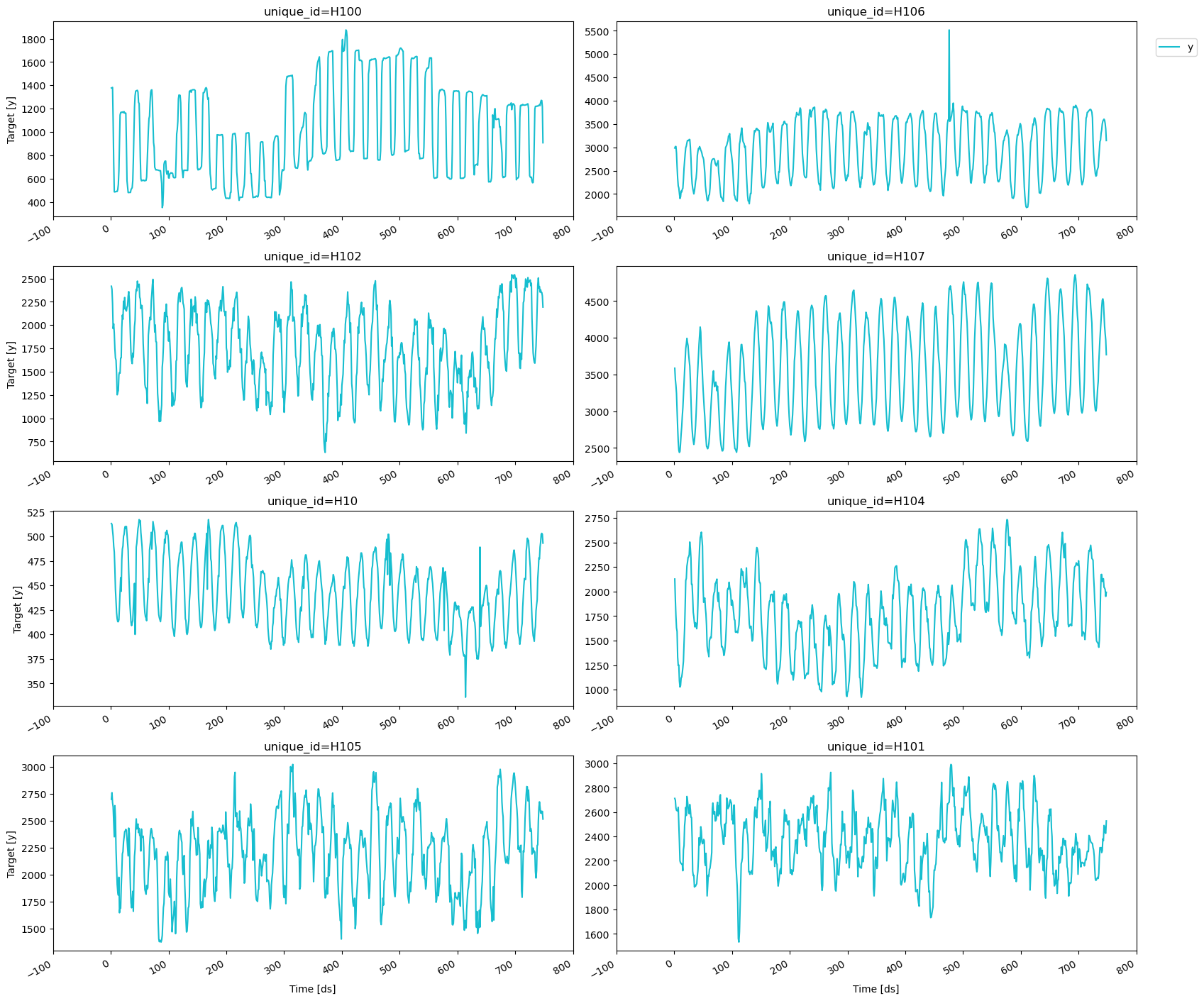
Only the best model is stored and used during inference.
predict method to forecast the next 48 days using the
optimal hyperparameters.
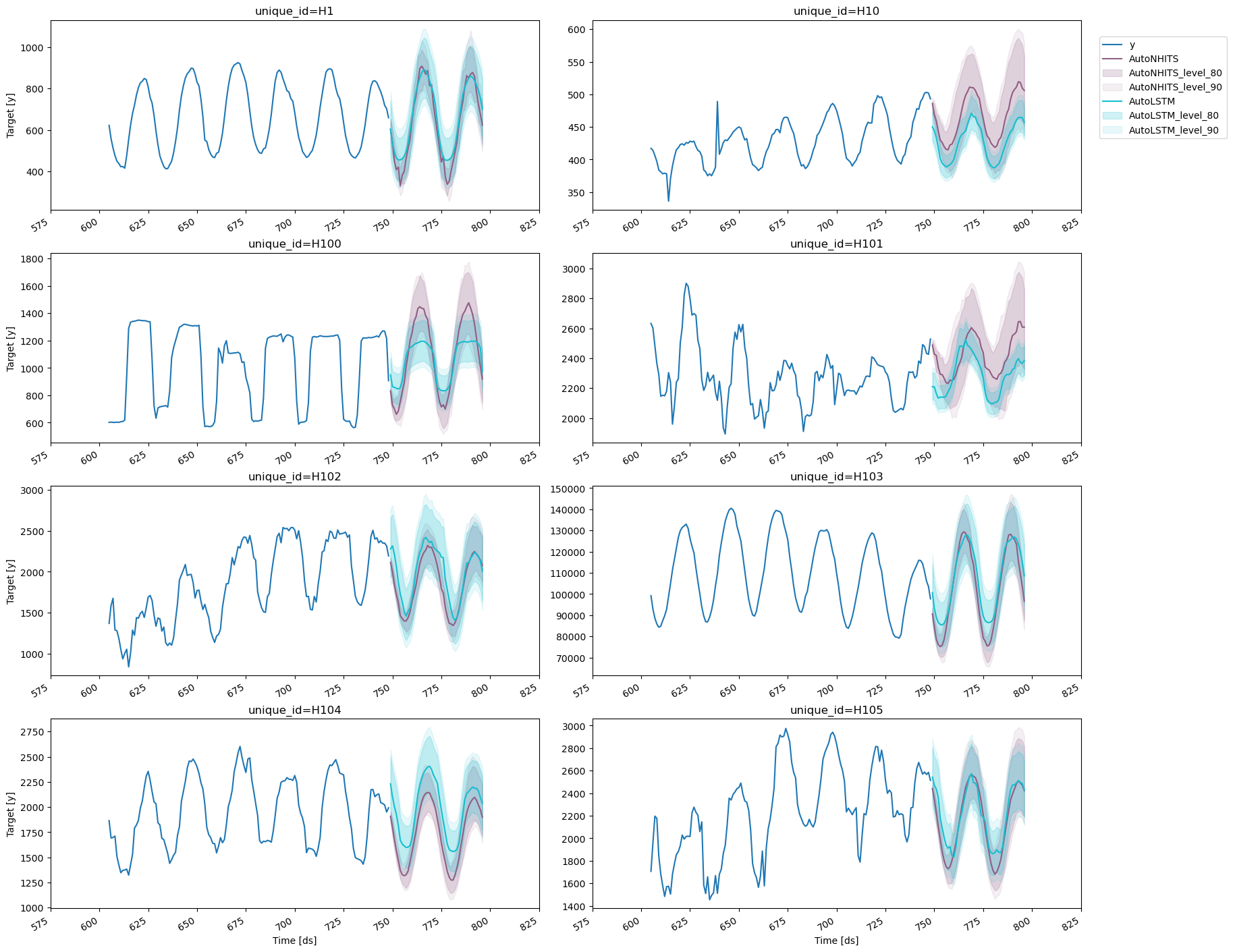
plot_series function allows for further customization. For
example, plot the results of the different models and unique ids.


5. Evaluate the model’s performance
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation. With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models. The following graph depicts such a Cross Validation Strategy:
Tip
Setting n_windows=1 mirrors a traditional train-test split with our
historical data serving as the training set and the last 48 hours
serving as the testing set.
The cross_validation method from the NeuralForecast class takes the
following arguments.
-
df: training data frame -
step_size(int): step size between each window. In other words: how often do you want to run the forecasting processes. -
n_windows(int): number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
cv_df object is a new data frame that includes the following
columns:
unique_id: identifies each time seriesds: datestamp or temporal indexcutoff: the last datestamp or temporal index for the n_windows. If n_windows=1, then one unique cuttoff value, if n_windows=2 then two unique cutoff values.y: true value"model": columns with the model’s name and fitted value.
Warning You can also use Mean Average Percentage Error (MAPE), however for granular forecasts, MAPE values are extremely hard to judge and not useful to assess forecasting quality.Create the data frame with the results of the evaluation of your cross-validation data frame using a Mean Squared Error metric.
Create a summary table with a model column and the number of series
where that model performs best.
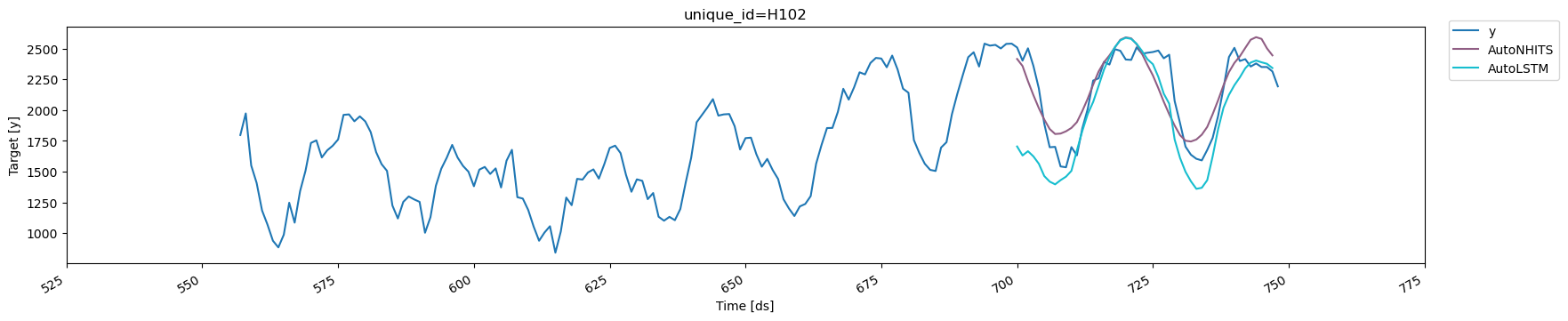
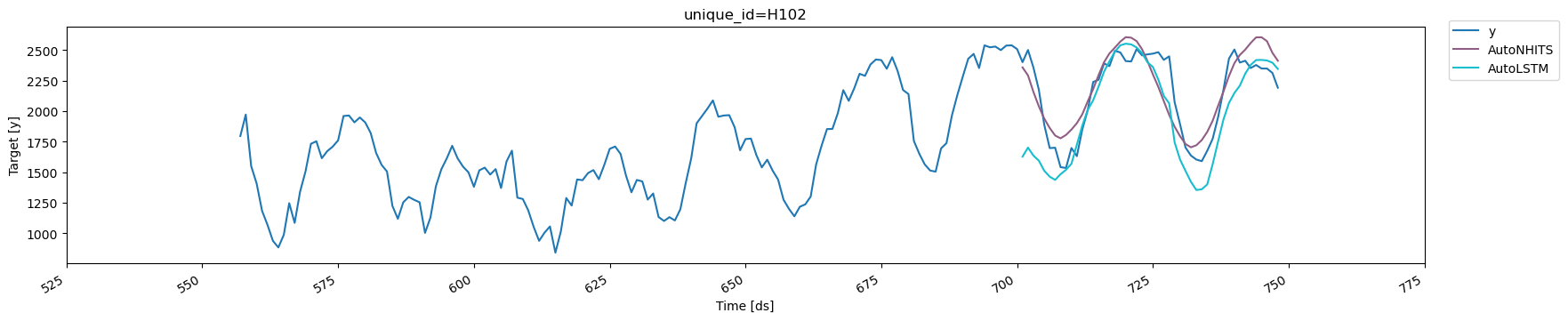
You can further explore your results by plotting the unique_ids where a
specific model wins.
6. Select the best model for every unique series
Define a utility function that takes your forecast’s data frame with the predictions and the evaluation data frame and returns a data frame with the best possible forecast for every unique_id.
Plot the results.