1. Libraries
2. Load ERCOT Data
The input to NeuralForecast is always a data frame in long format with three columns:unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp or int) column should be either an integer indexing time or a datestamp ideally like YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast. We will rename the
3. Model training and forecast
First, instantiate theAutoTFT model. The AutoTFT class will
automatically perform hyperparamter tunning using Tune
library, exploring a
user-defined or default search space. Models are selected based on the
error on a validation set and the best model is then stored and used
during inference.
To instantiate AutoTFT you need to define:
h: forecasting horizonloss: training lossconfig: hyperparameter search space. IfNone, theAutoTFTclass will use a pre-defined suggested hyperparameter space.num_samples: number of configurations explored.
Tip Increase thenum_samplesparameter to explore a wider set of configurations for the selected models. As a rule of thumb choose it to be bigger than15. Withnum_samples=3this example should run in around 20 minutes.
Tip
All our models can be used for both point and probabilistic
forecasting. For producing probabilistic outputs, simply modify the
loss to one of our DistributionLoss. The complete list of losses is
available in this
link
Important TFT is a very large model and can require a lot of memory! If you are running out of GPU memory, try declaring your config search space and decrease theThehidden_size,n_heads, andwindows_batch_sizeparameters. This are all the parameters of the config:
NeuralForecast class has built-in methods to simplify the
forecasting pipelines, such as fit, predit, and cross_validation.
Instantiate a NeuralForecast object with the following required
parameters:
-
models: a list of models. -
freq: a string indicating the frequency of the data. (See panda’s available frequencies.)
fit method to train the AutoTFT model on the ERCOT
data. The total training time will depend on the hardware and the
explored configurations, it should take between 10 and 30 minutes.
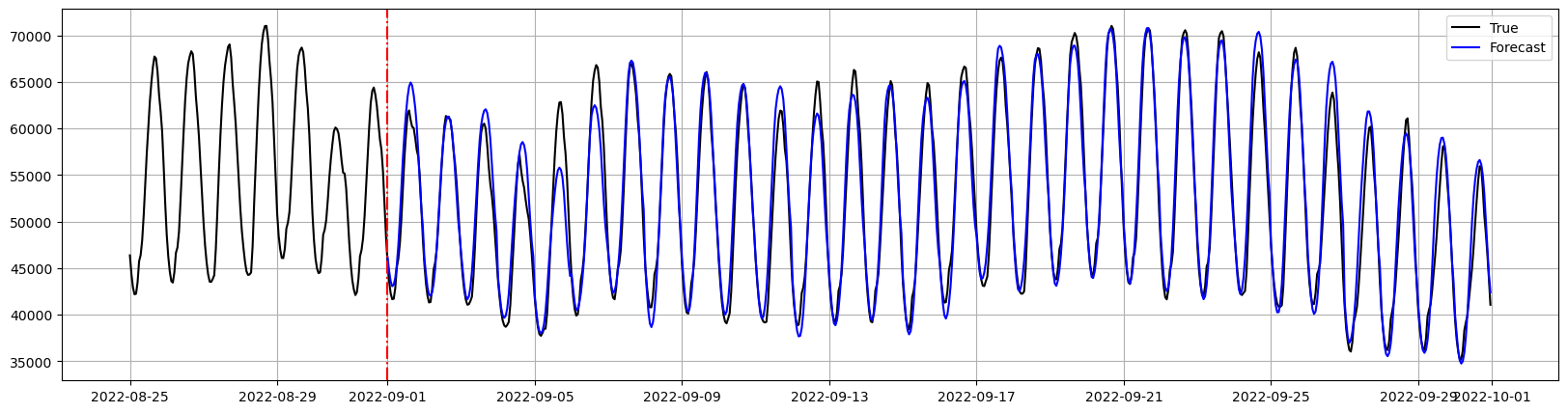
predict method to forecast the next 24 hours after
the training data and plot the forecasts.
Plot the results with matplot lib
4. Cross validation for multiple historic forecasts
Thecross_validation method allows you to simulate multiple historic
forecasts, greatly simplifying pipelines by replacing for loops with
fit and predict methods. See this
tutorial
for an animation of how the windows are defined.
With time series data, cross validation is done by defining a sliding
window across the historical data and predicting the period following
it. This form of cross validation allows us to arrive at a better
estimation of our model’s predictive abilities across a wider range of
temporal instances while also keeping the data in the training set
contiguous as is required by our models. The cross_validation method
will use the validation set for hyperparameter selection, and will then
produce the forecasts for the test set.
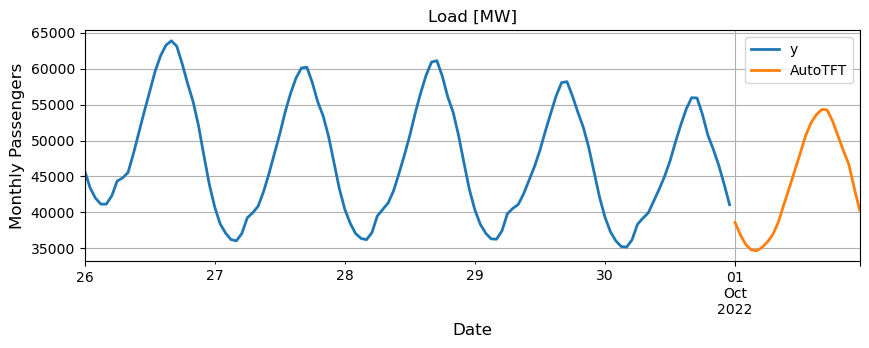
Use the cross_validation method to produce all the daily forecasts for
September. Set the validation and test sizes. To produce daily forecasts
set the forecasting set the step size between windows as 24, to only
produce one forecast per day.
Y_df dataset and plot the
forecasts.