

Assign relative importance weights to individual timesteps when training a model.
Motivation
When working with time series data, it is possible that we want to assign a higher or lower importance to certain values or periods in the series. For example, historical sales data cover the abnormal COVID period, so the model should not learn too much from that historical sequence. Alternativaly, you might be interested in the model being very good at modeling periods when a promotion is running. Thus, we need to a way to tell the model when to assign more or less importance to specific timesteps.Understanding sample_weight
The sample_weight is a reserved column name, similar to how we expect
the data to have columns ["unique_id", "ds", "y"]. In that column, we
can assign a positive integer to indicate how important a timestep is.
- Assigning a value of 0 means the particular timestep does not contribute to the loss.
- Higher values increase the contribution to the loss, so the model learns “more” about these timesteps.
Key considerations
Deep learning models are trained with windows of data. Internally, we take the mean of thesample_weight for a window to get its relative
importance. Therefore, training windows are never completely ignored,
unless the entire window has timesteps with sample_weight of 0.
In most cases, windows with timesteps assigned to a sample_weight of 0
will have a lower “mean importance”, and so will contribute less to the
loss of the model.
Take the following example:
With
input_size=4 and h=4, NeuralForecast creates sliding windows of
8 timesteps. The sample_weight for each window is themean over its forecast horizon (the future portion):
Window 1 is completely excluded from training: its entire forecast
horizon falls within the zeroed period. Windows 2–4 contribute
progressively more as the horizon moves out of it. Window 5 trains
normally. The model still “sees” timesteps in the input context of
windows 2–5. It learns what happened during that period, without being
penalized for predicting its future.
Important notes
sample_weightmust be greater than or equal to 0- there is no upper bound for
sample_weight. It works as a relative importance. So a value of 2 vs 1 means “twice as important”. 100 vs 50 would be interpreted the same way.
Usage
Let’s see an example of howsample_weight can be used in practice. We
use the Air Passengers dataset and cover different scenarios.
Setup
Load data
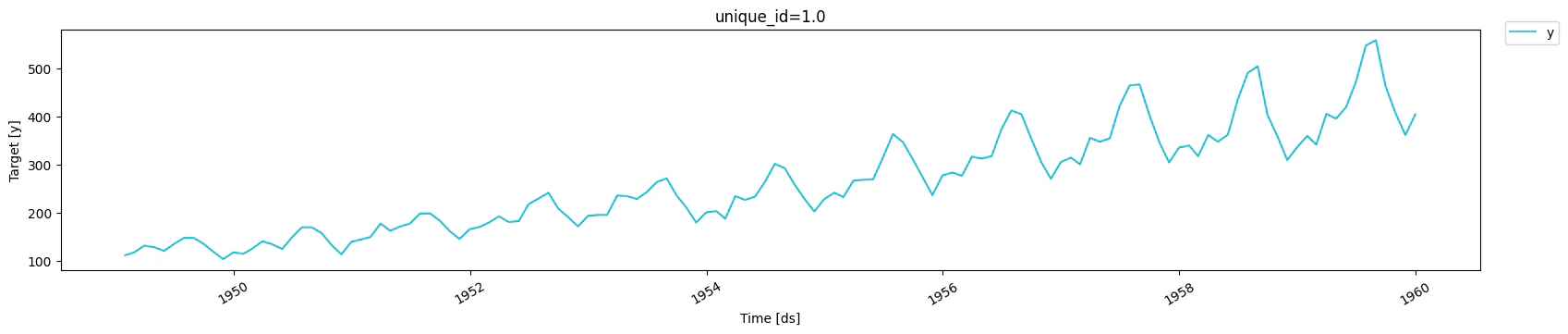
Prolonged anomaly
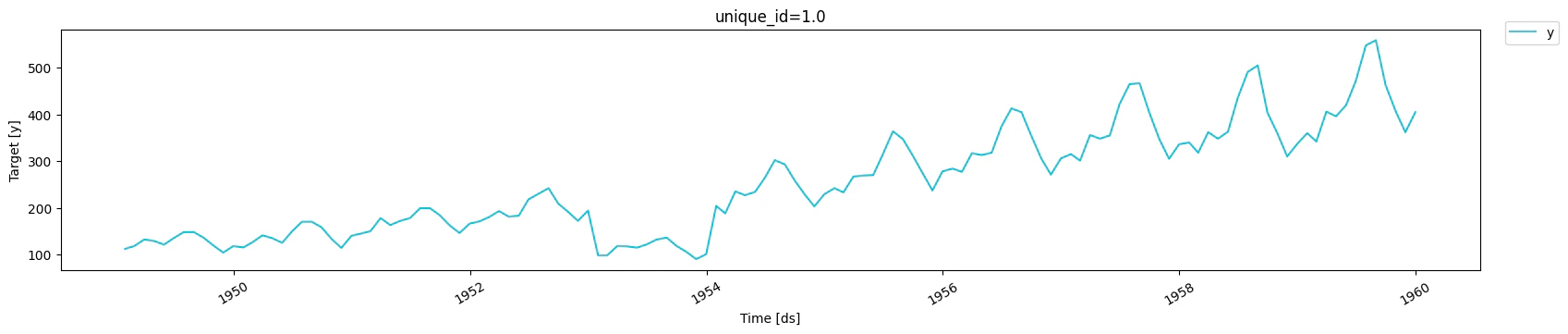
Here, we inject a prolonged anomaly where values are 50% lower than they actually are. For that anomalous period, we setsample_weight to 0,
and 1 otherwise. We then compare how the model performs when setting
sample_weight against using the default behavior.
Training and evaluating
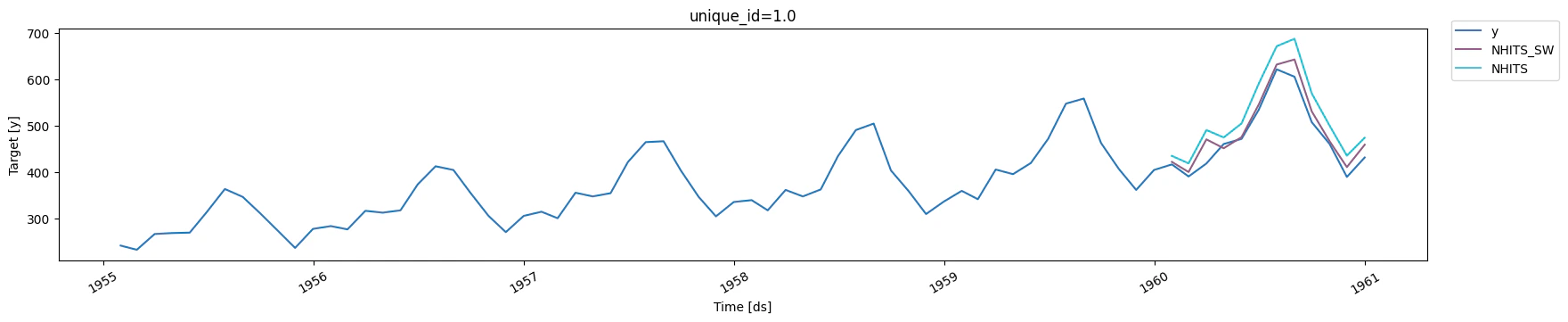
sample_weight improved the performance of the model as we assigned
less importance to the anomalous period.
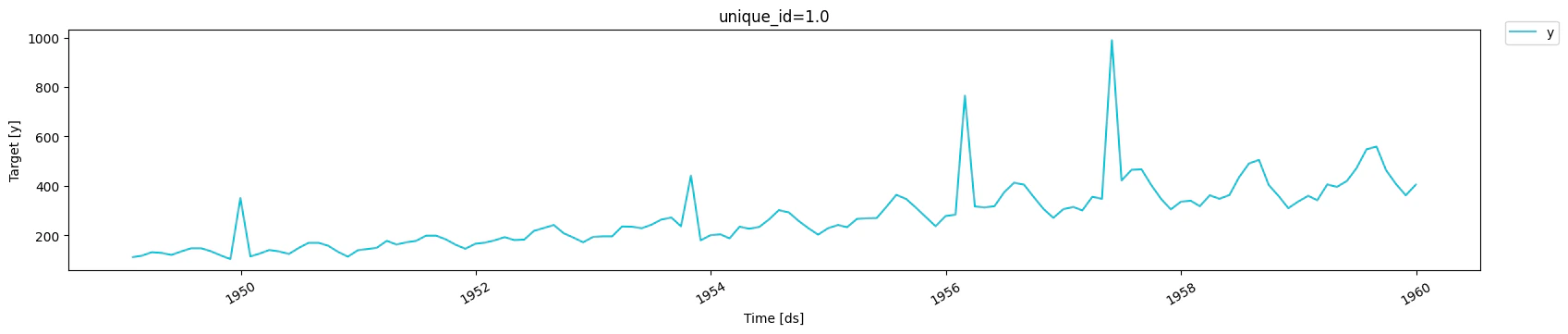
Isolated anomalies
Now, let’s consider a scenario where isolated anomalies occur in the data. As before, we assign asample_weight of 0 to those anomalies and
1 otherwise, and compare the performance.
Training and evaluating
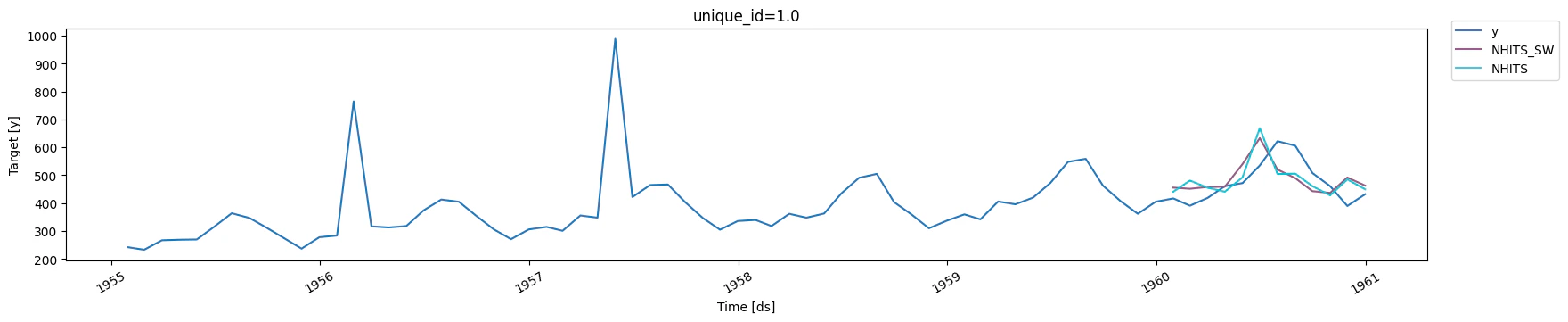
sample_weight is not sufficient. In fact, the
model performs slightly worse than not using sample_weight. Here, it
might be beneficial to use other methods robust to outliers, like
selecting the HuberLoss as the optimization objective.
Emphasize certain periods
Now, let’s consider the scenario where we want to give more importance to the summer months. Those are the months with the highest traffic, so we might want our model to be espcially good in those periods.
Training and evaluating
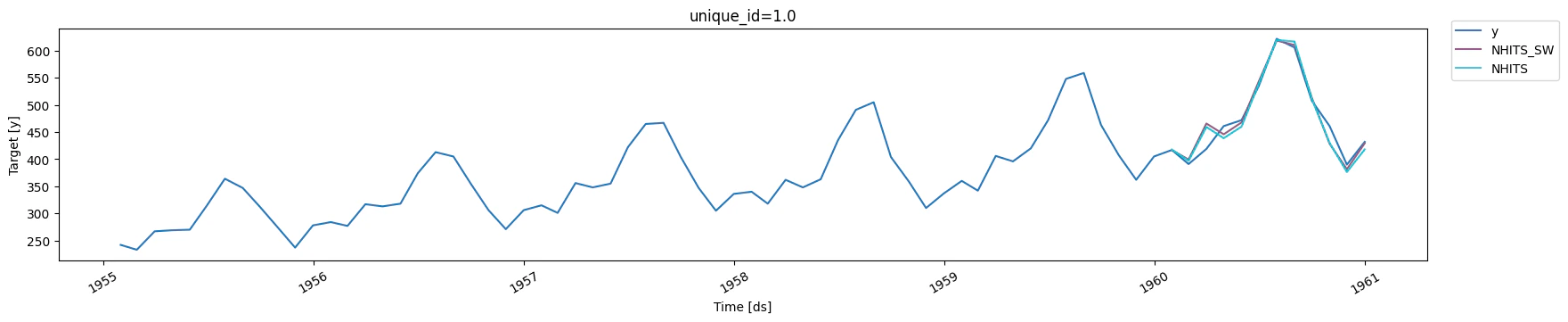
sample_weight improved the performance again.
Although it’s hard to see in the plot, the model trained with
sample_weight better forecasts the peaks of summer, resulting in a
performance gain.
Summary
NeuralForecast now supports thesample_weight column which is a
reserved column name to indicate the relative importance of each
timestep.
During training, the sample_weight of each window is the mean over the
forecast horizon. This helps the model either ignore anomalous sequences
or data points, or focus more on important periods.