

MLForecast. It walks through
the full process of building scalable time series pipelines-from
baseline model training to monthly incremental updates-illustrating how
update() enables efficient, real-time forecast refreshes without full
retraining. The focus is on designing sustainable, production-grade
forecasting workflows that balance speed, adaptability, and long-term
accuracy.
Table of Contents
- Introduction
- Why Incremental Forecasting Matters
- Why You Should Not Retrain at Every Step
- When Full Retraining Becomes Necessary
- A Hybrid Cadence for Reliable Forecasting Pipelines
- Model Design and Implementation Flow
- Comparing Incremental Updates and Full Retraining
- Visual Analysis of Forecast Behavior
- Conclusion
Introduction
When a forecasting system goes live, the flow of data doesn’t stop. Each month - or even each week - new observations arrive, and decision-makers expect your forecasts to adjust in real time. Yet, retraining the entire model every time new data comes in, is often the default reaction. It seems simple, but it’s computationally expensive, time-consuming, and can introduce instability into production workflows. This is where incremental forecasting becomes essential. Instead of retraining from scratch, we can incrementally update the model to reflect the latest data while preserving its learned patterns and parameters. InMLForecast, the update() method provides this
capability by allowing a trained forecasting object to absorb new
observations without retraining the underlying estimator. It extends the
historical window for each series, recalculates lag and date features,
and ensures that subsequent forecasts are generated using the most
recent actuals.
Why You Shouldn’t Retrain Every Time
Once your forecasting system is operational, new data becomes a constant. Each cycle - be it daily, weekly, or monthly - brings new observations that reflect the latest market conditions. The instinctive reaction is to retrain the entire model whenever new data arrives, under the assumption that a fresh model guarantees higher accuracy. In practice, however, frequent retraining is neither efficient nor necessary. Retraining a global model across thousands of time series is computationally expensive and can introduce instability into production pipelines. Each retrain recalculates lag features, re-splits data, re-fits hyperparameters, and may slightly shift model weights due to stochastic effects, creating subtle variations in forecast outputs that can confuse downstream systems or decision-makers. Moreover, most new observations tend to reinforce existing patterns rather than alter them drastically. The incremental update approach offers a more robust alternative. Instead of discarding the existing model, MLForecast’supdate() method
allows you to append new observations to the existing historical window.
It recalculates lag, lag_transforms, and date features while keeping the
learned model parameters fixed. This ensures that your forecasts stay
aligned with the most recent actuals without triggering a full
retraining cycle. The table below summarizes the difference between
Retraining the model and Incremental Learning.
When to Retrain Anyway
Incremental updates are powerful, but they are not a permanent substitute for model retraining. Over time, even the most robust forecasting systems experience concept drift - subtle or abrupt changes in the underlying data-generating process. When this happens, the relationships your model once learned no longer represent reality. In other words, the past stops being a reliable guide to the future. Retraining becomes necessary when the environment changes in ways that cannot be captured by simply appending new observations. Some common triggers include:1. Structural breaks in the data
Events such as product rebranding, changes in packaging, or shifts in demand patterns can cause discontinuities in historical trends. These “structural breaks” disrupt the temporal consistency that incremental updates rely on. A retraining cycle helps the model recalibrate to the new baseline. How to identify structural changes2. Distributional or Seasonal Drift
If the statistical properties of the series - mean, variance, or seasonal amplitudes - start deviating consistently from past patterns, your lag-based features become less predictive. How to identify distributional or seasonal drift3. Changes in Exogenous Features
When the relationship between the target and external drivers changes, the model’s learned dependencies no longer reflect how the real world behaves. These changes often arise from broader business or environmental shifts rather than from the time series itself. For example, sudden changes in import tariffs can make certain products more expensive and reduce sensitivity to discounts, altering long-standing price–demand relationships. The COVID-19 pandemic is another well known example where mobility restrictions, work-from-home adoption, and shifts in consumer priorities changed the way promotions, holidays, and even weather patterns influenced demand. Fuel price spikes can change commuting behaviour and affect categories like ready-to-eat foods, travel accessories, or home improvement. Unexpected supply shortages can change how customers respond to stockouts or substitute products. Even store refurbishments, new competitor entries, or changes in brand positioning can shift the effectiveness of promotions or alter the response to price changes. In all these scenarios, the external features have not simply drifted in value; the way they influence demand has changed. Models relying on outdated relationships need retraining to correctly learn the new dependency structure.4. Model degradation in Monitoring Metrics
A steady rise in forecast error such as RMSSE or MAPE across a meaningful portion of the portfolio is one of the clearest signals that incremental updates are no longer sufficient. In practice, this degradation is detected through rolling or windowed error tracking, residual stability checks, horizon specific error monitoring, and cohort level breakdowns, all of which were discussed in earlier sections. When these monitoring signals begin to trend upward consistently, or when residuals show persistent bias or variance inflation, it indicates that the model is drifting away from the underlying data generating process. At this point, incremental updates can no longer correct the misalignment and a full retraining cycle becomes necessary to restore performance stability.5. Major Business or Market Shifts
Major business or market shifts can reshape demand patterns so abruptly that previously learned temporal relationships no longer hold. External shocks such as sudden supply chain disruptions, unexpected policy changes, or rapid demand surges create new regimes that the model has never seen before. Examples include widespread stockouts during global logistics delays, regulatory changes affecting product availability, or short-term spikes in demand triggered by festivals, weather anomalies, or viral social trends. As discussed earlier, these shifts often operate outside the time series itself and override the stability that incremental updates rely on. When such events realign consumer behaviour or operational constraints, a full retraining cycle becomes necessary to ensure the model adapts to the new environment.A Hybrid Cadence for Sustainable Forecasting
Retraining and updating are not competing strategies - they’re complementary. In a well-engineered forecasting pipeline, the two work together to balance adaptability, efficiency, and stability. This balanced cadence ensures your model evolves with data drift while avoiding unnecessary computational overhead. A hybrid cadence combines three operational layers:1. Routine Incremental Updates (Short-Term Adaptation)
Use MLForecast’supdate() method every time new data arrives -
typically weekly or monthly. This keeps forecasts current by
recalculating lag and date features using the latest observations,
without retraining the model.
- Objective: Maintain freshness of forecasts
- Cost: Minimal (light computation)
- When to use: After each data ingestion cycle
2. Scheduled Retraining (Periodic Refresh)
Perform full model retraining at regular intervals - for instance, quarterly or semi-annually. This refreshes feature relationships, captures gradual drift, and resets model parameters to reflect long-term trends.- Objective: Recalibrate the model to evolving seasonal or macro patterns
- Cost: Moderate to high (training time and resource usage)
- When to use: On a fixed calendar schedule or after major seasonal transitions
3. Drift-Triggered Retraining (Event-Based Correction)
Deploy monitoring scripts that track forecast accuracy (e.g., RMSSE, MAPE, WAPE) and detect statistical drift using tools such as the Kolmogorov–Smirnov test or rolling error windows. If accuracy degrades beyond a defined threshold, initiate an unscheduled retrain.- Objective: Respond to sudden or unanticipated changes
- Cost: High but justified by regained accuracy
- When to use: When metrics indicate model degradation or feature distribution shifts
Quantitative Validation
To evaluate the effectiveness of this cadence, compare update-only vs. retrain strategies using MLForecast’scross_validation():
refit=Falsesimulates incremental updates (trained once, updated continuously)refit=Truesimulates retraining at each historical window Ifrefit=Trueconsistently outperformsrefit=False, it signals that drift is significant and retraining yields real gains.
Why This Matters
This cadence matters because forecasting systems fail silently when they rely on only one mechanism of adaptation. Incremental updates alone cannot correct for long-term drift, and full retraining alone cannot deliver the responsiveness modern pipelines require. By combining both, you create a system that stays fresh in the short term, stable in the long term, and resilient when unexpected changes occur. It ensures that the model not only keeps pace with new data but also remains aligned with the deeper structural patterns that drive forecasting accuracy. In practice this means fewer operational surprises, fewer degradations that go unnoticed, and forecasts that remain dependable even as the business and the environment around it evolve. In essence, incremental updates keep your model agile; retraining keeps it honest.Code Implementation Overview
Installing mlforecast and Required Libraries
Before we dive into incremental forecasting, let’s set up the
environment by installing all necessary dependencies. We’ll use
mlforecast, along with common Python libraries for data handling and
visualization. You can open it in colab in this
link.
💡 Tip: If you’re running this in Google Colab or a fresh environment, it’s a good idea to restart the kernel after installation to ensure all dependencies are properly loaded.
Loading the M3 Dataset
For this demonstration, we’ll use the M3 forecasting competition dataset, a widely used benchmark for evaluating time series models.Specifically, we’ll focus on the
M1 series from the Monthly (M)
group.
The M3 dataset provides multiple time series across different
frequencies -Yearly, Quarterly, Monthly, and Others.By selecting one unique identifier (
unique_id = 'M1'), we can
visualize and test how incremental forecasting behaves on a single,
interpretable time series.
📘 Note: The dataset is loaded usingdatasetsforecastpackage, which automatically structures the data in the expected format for MLForecast - columnsunique_id,ds(date), andy(target value).
Defining the Simulation Scenario
To replicate a real-world production forecasting setup, we’ll simulate how forecasts evolve as new data arrives over time, without retraining the model. This helps us understand howupdate() method can
efficiently keep forecasts current in a live environment.
Here’s how we’ll structure the simulation:
- Data from 1991-06-30 to 1994-05-31 serves as the baseline training period (Month 0) - the last available data before the model is deployed.
- We then simulate three consecutive production updates, where new
observations gradually arrive:
- Month 1: Includes actuals for 1994-06-30
- Month 2: Includes actuals for 1994-07-31
- Month 3: Includes actuals for 1994-08-31
update() method, allowing it to absorb new observations, recompute
lags and date features, and produce refreshed forecasts without
undergoing a full retraining cycle.
Model specification - XGBoost with lags and lag_transforms
For this demonstration we use XGBoost Regressor together with a small set of lag features and lag_transforms. The goal is to keep the model simple and interpretable while preserving enough temporal information to produce reliable incremental forecasts. In the next block we define the complete forecasting setup for Month Zero. We create an MLForecast object that includes the XGBoost Regressor, the time frequency of the series and a structured set of lag features and lag based statistical transforms. The same block also defines a compact evaluation function that usesutilsforecast to merge predictions with the test set and
compute MAE and RMSE. This keeps the evaluation process
consistent for all forecasting stages that follow.
Incremental Learning for Month 1, 2 and 3
Updating the Model for Month One
Now that we have the actuals for Month One (June 1994), we’ll simulate how a forecasting system incorporates this new data without retraining. Instead of rebuilding the model from scratch, we’ll use theupdate()
method to incrementally refresh the forecasting object.This operation allows the model to:
- Absorb the latest observation into its internal history
- Recompute lag and date-based features
- Generate forecasts that reflect the most recent trend
Updating the Model for Month Two
Next, we simulate the arrival of Month Two (July 1994) data. By this point, our model has already been incrementally updated with the June actuals. Now, we extend the historical window once more by incorporating the July observation.Updating the Model for Month Three
Finally, we simulate the arrival of Month Three (August 1994) actuals. By this stage, the model has already incorporated data from June and July through successive incremental updates. Now, we’ll perform one moreupdate() to include the August observation.
Full Retrain for Month 1, 2 and 3
The following function reconstructs the entire MLForecast pipeline and trains a fresh model on the supplied dataset. It defines a new XGBoost regressor, rebuilds all lag features, regenerates lag based statistical transforms and recreates the date features for every retraining cycle. This function is used when we want to evaluate how the model performs with full retraining after Month 1, Month 2 and Month 3.Full retrain for Month One
Full retrain for Month Two
Full retrain for Month Three
Displaying the Forecast for incremental updates and full retraining
MAE and RMSE comparison across Incremental Updates and Full Retraining
The table below compares the MAE and RMSE produced by the incremental forecasting approach and the full retraining approach for Month One, Month Two and Month Three. This comparison helps illustrate how forecast accuracy changes when the model is updated versus fully retrained on expanded training windows.Visualizing Actuals and Forecasts for Incremental Updates and Full Retraining
To understand how the forecasting behavior evolves over time, we now visualize the actual series together with the forecasted values generated at each stage for both incremental updates and full retraining. This includes predictions from Month 0, Month 1, Month 2 and Month 3 for both approaches.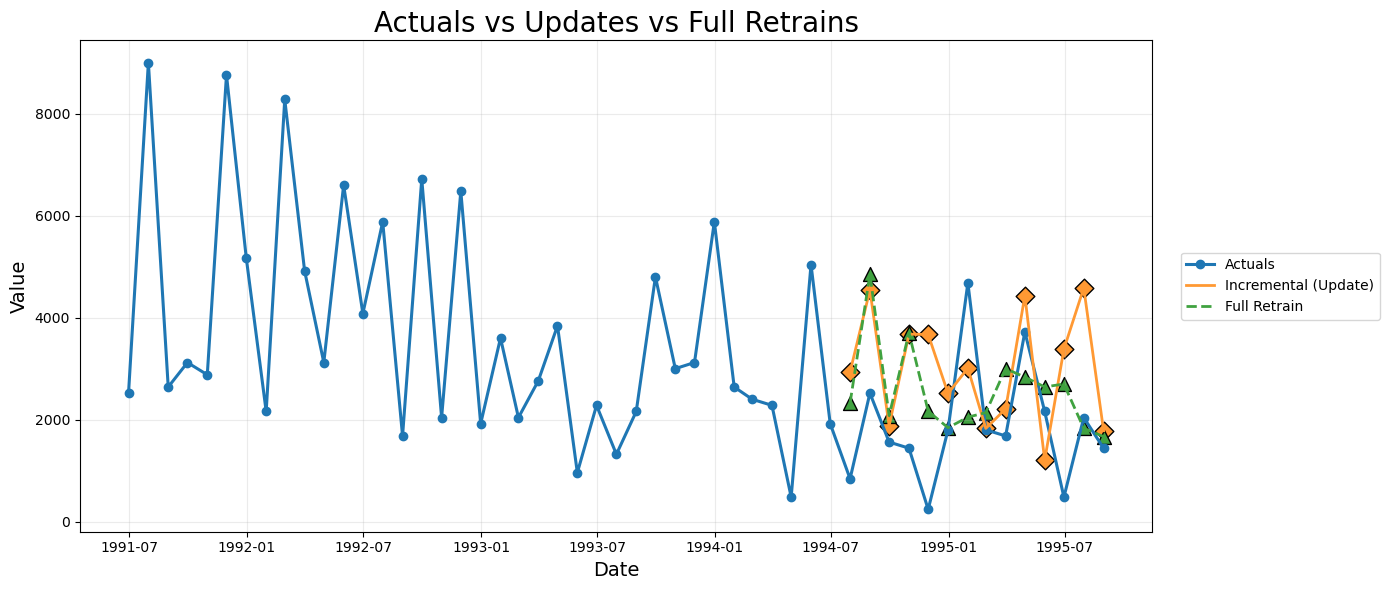
Comparative analysis of Incremental Updates and Full Retraining
The plots and RMSE comparison table together provide a complete picture of how the two forecasting strategies behave as new data becomes available. Both methods process the same series, but their update mechanisms differ. Incremental forecasting updates only the data window while preserving the learned model parameters. Full retraining rebuilds the entire model on each expanded dataset. The following points summarise the observed behaviour.1. Responsiveness to new observations
- Incremental updates shift the forecasts quickly toward the newest actual points. This is visible in the plot where each successive update pulls the forecast curves closer to the recent downward and upward movements in Month 1, 2 and 3.
- Full retraining is also responsive, but sometimes overshoots or undershoots depending on how the newly retrained model interprets the expanded historical window. The variance introduced in the retrained curves is visible in the colour coded lines for FullRetrain M1, M2 and M3.
2. Stability and continuity of the forecast path
- The incremental method produces smoother transitions, since the model parameters do not change. Only the lagged features derived from the newly appended data shift the forecasts. This preserves the character of the initial model and avoids abrupt structural changes.
- Full retraining reoptimises the model with every cycle. This can cause sudden changes in the shape of the predictions.
3. Accuracy across the three cycles
- For Month One and Month Two, the incremental approach produces lower MAE and RMSE than the retrained model. This suggests that the original model was already well tuned and preserving its parameters provided better generalisation.
- For Month Three, the trend reverses and the fully retrained model performs better. This indicates that by the third update the model benefits from incorporating the longer training history and reoptimising its parameters.
4. Practical interpretation
- Incremental forecasting is more stable, less computationally heavy and adapts quickly to new information. It is suitable for real time or high frequency update environments.
- Full retraining can provide benefits once enough new data accumulates, especially if the underlying pattern has shifted. However, it is more sensitive to small data variations and may introduce unnecessary volatility when used too frequently.
Conclusion
This tutorial shows that incremental forecasting with MLForecast provides a practical and efficient way to manage evolving time series. By combining lag based feature engineering withupdate() mechanisms,
the approach keeps forecasts aligned with incoming data while avoiding
the cost of frequent full model rebuilds. The results highlight how
incremental updates maintain stability and continuity, making them
suitable for production settings where new observations arrive
regularly. Full retraining still has value when enough new information
accumulates, but incremental updates offer a reliable and scalable
foundation for ongoing forecasting operations.
References
- Nixtla Team. (2024). MLForecast: Scalable Machine Learning for Time Series Forecasting.
-
Makridakis, S., & Hibon, M. (2000). The M3-Competition: Results,
Conclusions and Implications.
International Journal of Forecasting, 16(4), 451–476.
DOI: 10.1016/S0169-2070(00)00057-1 - Chaudhuri, S., (2025). A Practical Guide to Incremental Updates and Transfer Learning for Scalable New-Product Forecasting using MLForecast. Available at: Article by Satyajit Chaudhuri on Medium