Access and interpret the models after fitting
Data setup
Training
Suppose that you want to train a linear regression model using the day of the week and lag1 as features.MLForecast.fit does is save the required data for the predict
step and also train the models (in this case the linear regression). The
trained models are available in the MLForecast.models_ attribute,
which is a dictionary where the keys are the model names and the values
are the model themselves.
Inspect parameters
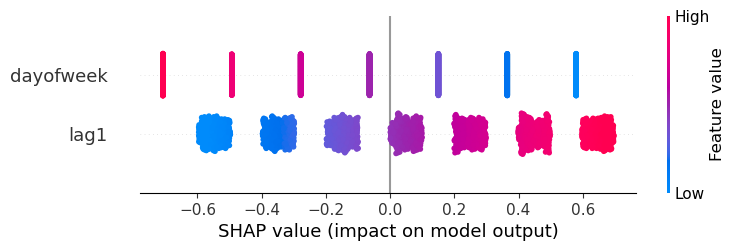
We can access the linear regression coefficients in the following way:SHAP
Training set
If you need to generate the training data you can useMLForecast.preprocess.
We extract the X, which involves dropping the info columns (id + times)
and the target
We can now compute the shap values
Predictions
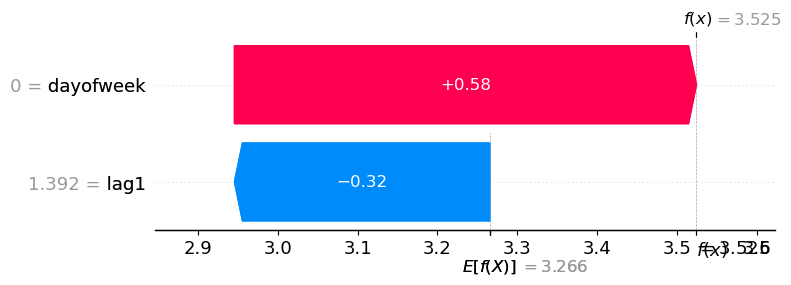
Sometimes you want to determine why the model gave a specific prediction. In order to do this you need the input features, which aren’t returned by default, but you can retrieve them using a callback.
You can now retrieve the features by using
SaveFeatures.get_features
And use those features to compute the shap values.
'id_4'.