Detailed description of all the functionalities that MLForecast provides.
Data setup
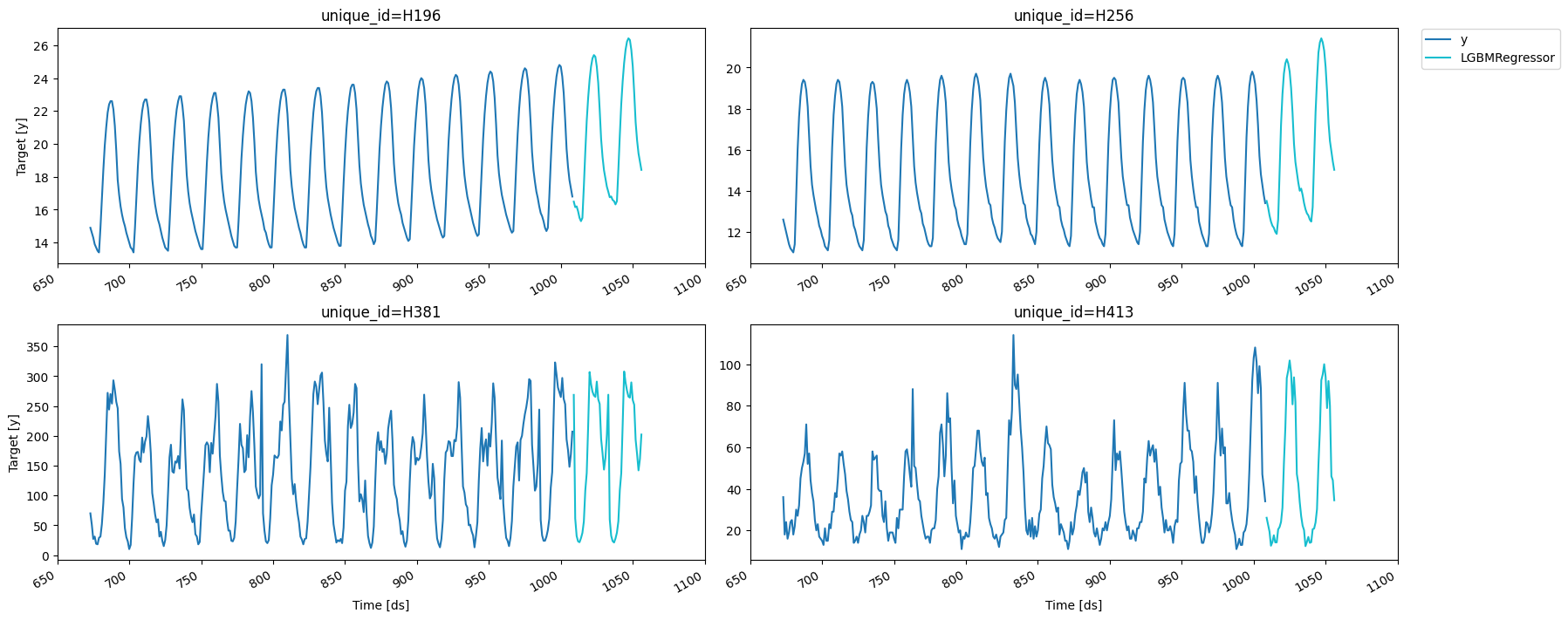
For this example we’ll use a subset of the M4 hourly dataset. You can find the a notebook with the full dataset here.EDA
We’ll take a look at our series to get ideas for transformations and features.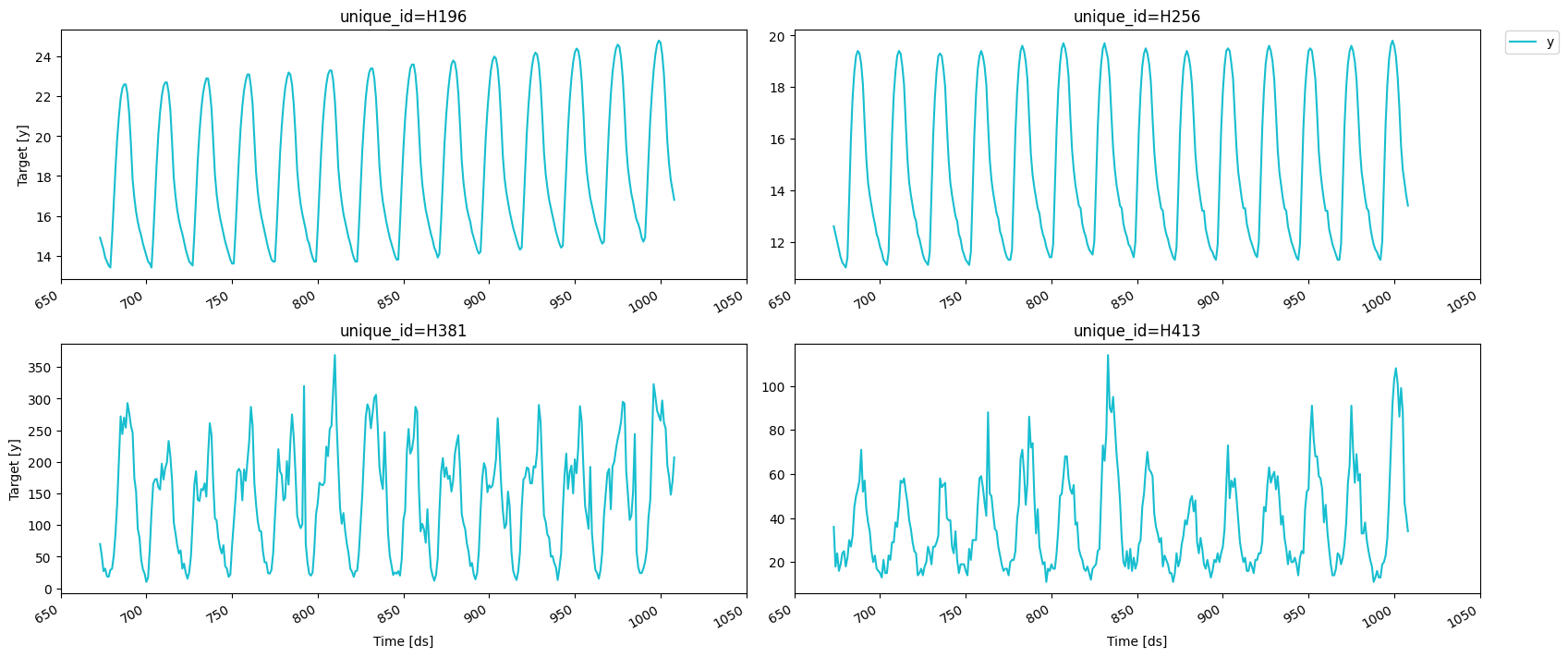
MLForecast.preprocess method to explore different
transformations. It looks like these series have a strong seasonality on
the hour of the day, so we can subtract the value from the same hour in
the previous day to remove it. This can be done with the
mlforecast.target_transforms.Differences transformer, which we pass
through target_transforms.
This has subtracted the lag 24 from each value, we can see what our
series look like now.
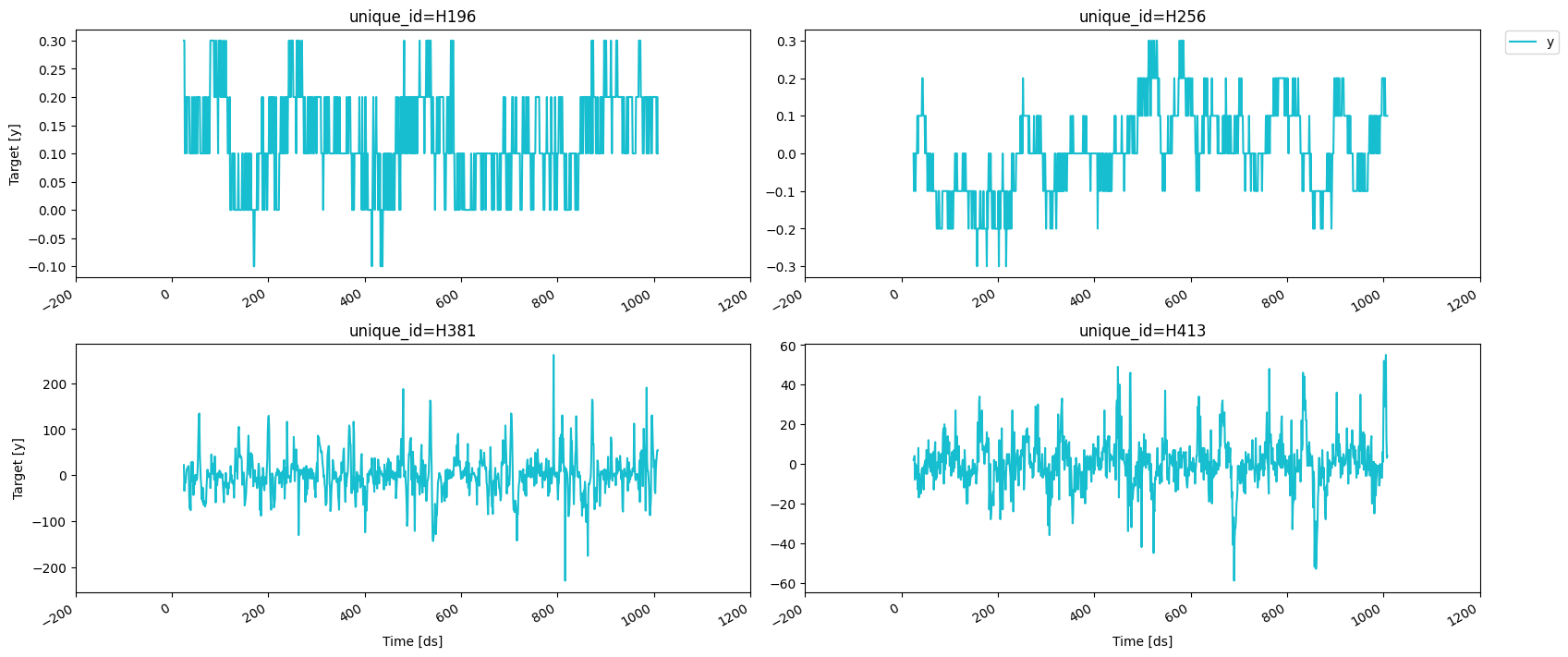
Adding features
Lags
Looks like the seasonality is gone, we can now try adding some lag features.Lag transforms
Lag transforms are defined as a dictionary where the keys are the lags and the values are the transformations that we want to apply to that lag. The lag transformations can be either objects from themlforecast.lag_transforms module or numba
jitted functions (so that computing the features doesn’t become a
bottleneck and we can bypass the GIL when using multithreading), we have
some implemented in the window-ops
package but you can also
implement your own.
You can see that both approaches get to the same result, you can use
whichever one you feel most comfortable with.
Date features
If your time column is made of timestamps then it might make sense to extract features like week, dayofweek, quarter, etc. You can do that by passing a list of strings with pandas time/date components. You can also pass functions that will take the time column as input, as we’ll show here.Target transformations
If you want to do some transformation to your target before computing the features and then re-apply it after predicting you can use thetarget_transforms argument, which takes a list of transformations. You
can find the implemented ones in mlforecast.target_transforms or you
can implement your own as described in the target transformations
guide.
We can define a naive model to test this
We compare this with the last values of our series
Training
Once you’ve decided the features, transformations and models that you want to use you can use theMLForecast.fit method instead, which will
do the preprocessing and then train the models. The models can be
specified as a list (which will name them by using their class name and
an index if there are repeated classes) or as a dictionary where the
keys are the names you want to give to the models, i.e. the name of the
column that will hold their predictions, and the values are the models
themselves.
Forecasting
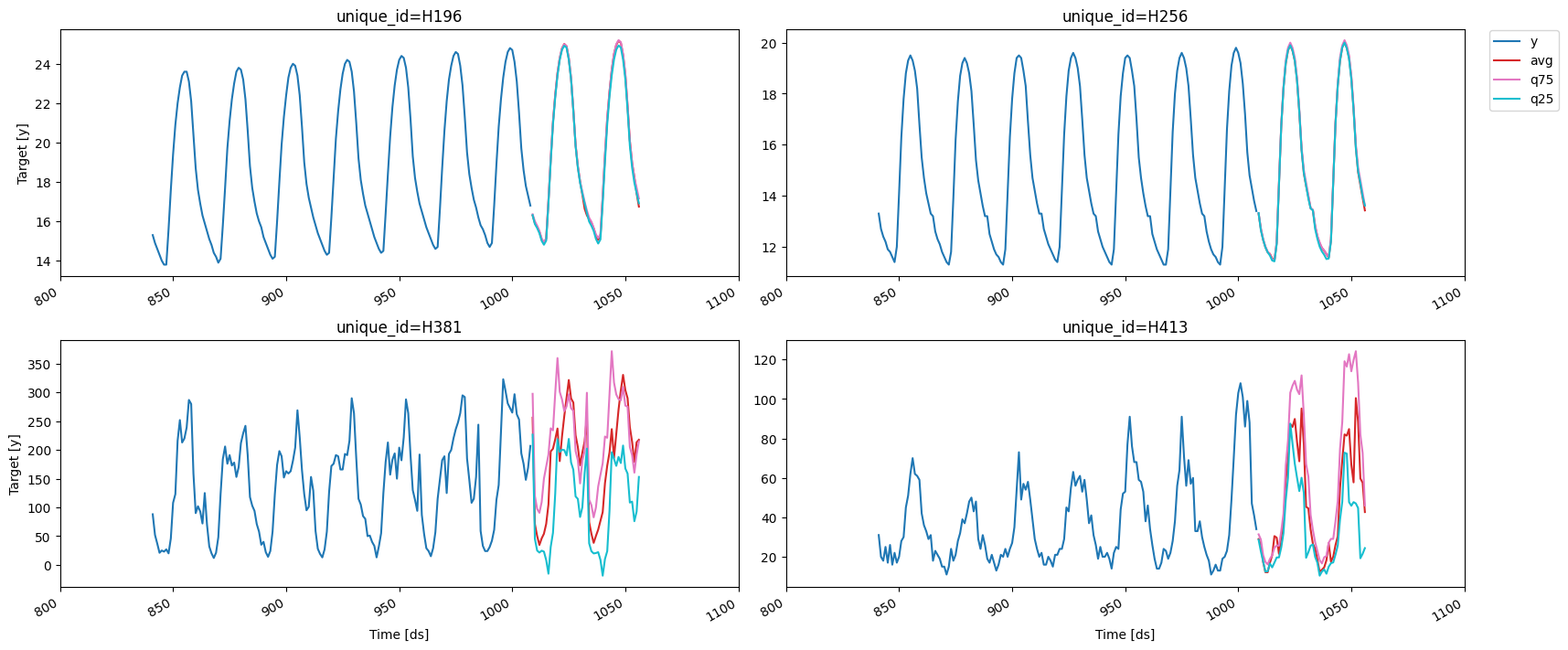
Saving and loading
The MLForecast class has theMLForecast.save and MLForecast.load to
store and then load the forecast object.
Updating series’ values
After you’ve trained a forecast object you can save and load it with the previous methods. If by the time you want to use it you already know the following values of the target you can use theMLForecast.update
method to incorporate these, which will allow you to use these new
values when computing predictions.
- If no new values are provided for a series that’s currently stored, only the previous ones are kept.
- If new series are included they are added to the existing ones.
Estimating model performance
Cross validation
In order to get an estimate of how well our model will be when predicting future data we can perform cross validation, which consists of training a few models independently on different subsets of the data, using them to predict a validation set and measuring their performance. Since our data depends on time, we make our splits by removing the last portions of the series and using them as validation sets. This process is implemented inMLForecast.cross_validation.
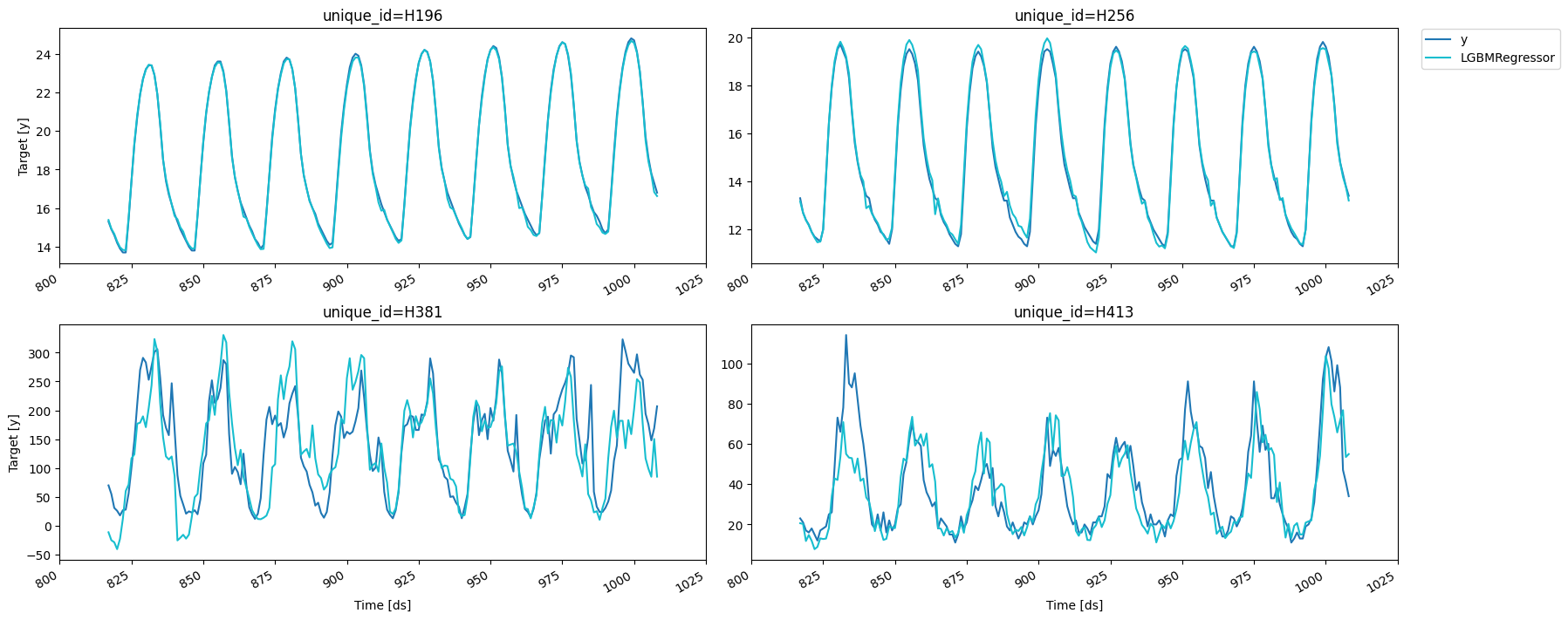
And the average RMSE across splits.
LightGBMCV
In the same spirit of estimating our model’s performance,LightGBMCV
allows us to train a few
LightGBM models on different
partitions of the data. The main differences with
MLForecast.cross_validation are:
- It can only train LightGBM models.
- It trains all models simultaneously and gives us per-iteration averages of the errors across the complete forecasting window, which allows us to find the best iteration.
eval_every argument) and performs early stopping (which can be
configured with early_stopping_evals and early_stopping_pct). If you
set compute_cv_preds=True the out-of-fold predictions are computed
using the best iteration found and are saved in the cv_preds_
attribute.
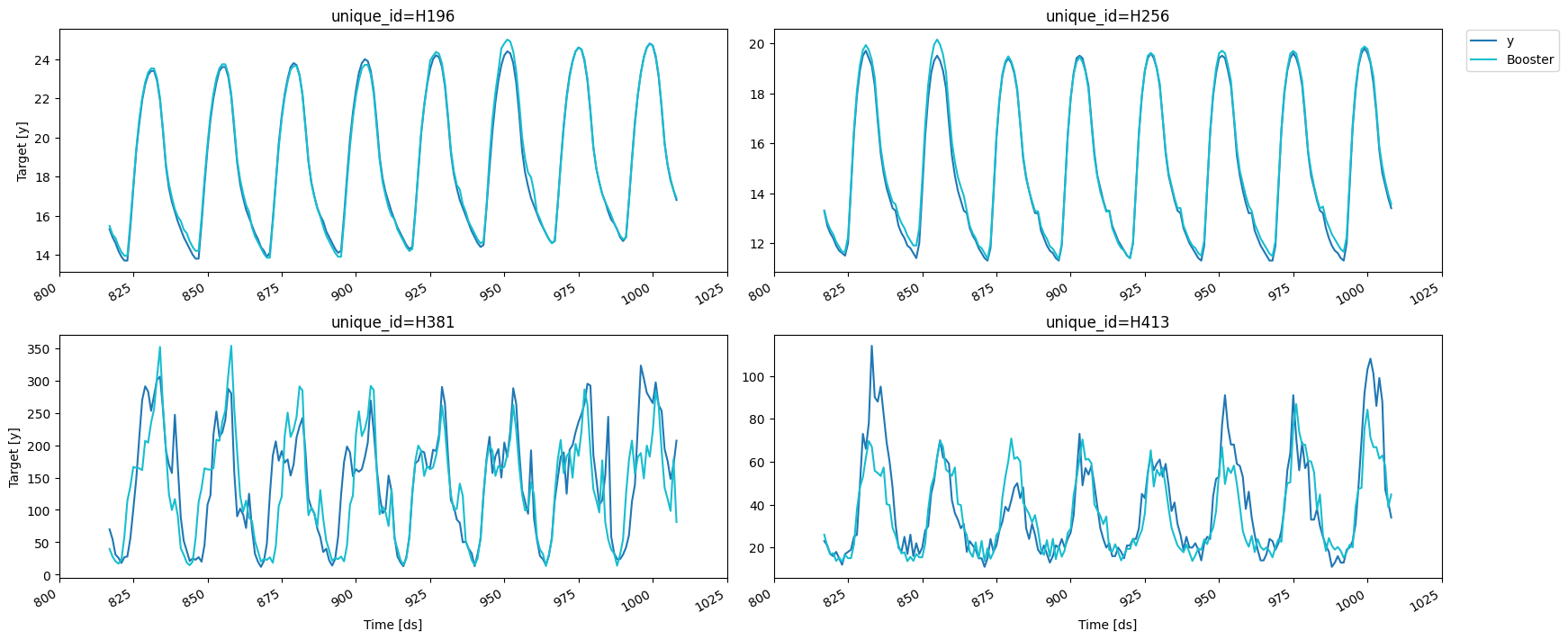
MLForecast object from the LightGBMCV one as
follows: