

Prediction intervals in forecasting models using
mlforecast.
During this walkthrough, we will become familiar with the main
MlForecast class and some relevant methods such as MLForecast.fit,
MLForecast.predict and MLForecast.cross_validation in other.
Let’s start!!!
Table of contents
- Introduction
- Forecasts and prediction intervals
- Installing mlforecast
- Loading libraries and data
- Explore Data with the plot method
- Split the data into training and testing
- Modeling with mlforecast
- References
Introduction
The target of our prediction is something unknown (otherwise we wouldn’t be making a prediction), so we can think of it as a random variable. For example, the total sales for the next month could have different possible values, and we won’t know what the exact value will be until we get the actual sales at the end of the month. Until next month’s sales are known, this is a random amount. By the time the next month draws near, we usually have a pretty good idea of possible sales values. However, if we are forecasting sales for the same month next year, the possible values can vary much more. In most forecasting cases, the variability associated with what we are forecasting reduces as we get closer to the event. In other words, the further back in time we make the prediction, the more uncertainty there is. We can imagine many possible future scenarios, each yielding a different value for what we are trying to forecast. When we obtain a forecast, we are estimating the middle of the range of possible values the random variable could take. Often, a forecast is accompanied by a prediction interval giving a range of values the random variable could take with relatively high probability. For example, a 95% prediction interval contains a range of values which should include the actual future value with probability 95%. Rather than plotting individual possible futures , we usually show these prediction intervals instead. When we generate a forecast, we usually produce a single value known as the point forecast. This value, however, doesn’t tell us anything about the uncertainty associated with the forecast. To have a measure of this uncertainty, we need prediction intervals. A prediction interval is a range of values that the forecast can take with a given probability. Hence, a 95% prediction interval should contain a range of values that include the actual future value with probability 95%. Probabilistic forecasting aims to generate the full forecast distribution. Point forecasting, on the other hand, usually returns the mean or the median or said distribution. However, in real-world scenarios, it is better to forecast not only the most probable future outcome, but many alternative outcomes as well. The problem is that some timeseries models provide forecast distributions, but some other ones only provide point forecasts. How can we then estimate the uncertainty of predictions?Forecasts and prediction intervals
There are at least four sources of uncertainty in forecasting using time series models:- The random error term;
- The parameter estimates;
- The choice of model for the historical data;
- The continuation of the historical data generating process into the future.
Forecast distributions
We use forecast distributions to express the uncertainty in our predictions. These probability distributions describe the probability of observing different future values using the fitted model. The point forecast corresponds to the mean of this distribution. Most time series models generate forecasts that follow a normal distribution, which implies that we assume that possible future values follow a normal distribution. However, later in this section we will look at some alternatives to normal distributions.Importance of Confidence Interval Prediction in Time Series:
- Uncertainty Estimation: The confidence interval provides a measure of the uncertainty associated with time series predictions. It enables variability and the range of possible future values to be quantified, which is essential for making informed decisions.
- Precision evaluation: By having a confidence interval, the precision of the predictions can be evaluated. If the interval is narrow, it indicates that the forecast is more accurate and reliable. On the other hand, if the interval is wide, it indicates greater uncertainty and less precision in the predictions.
- Risk management: The confidence interval helps in risk management by providing information about possible future scenarios. It allows identifying the ranges in which the real values could be located and making decisions based on those possible scenarios.
- Effective communication: The confidence interval is a useful tool for communicating predictions clearly and accurately. It allows the variability and uncertainty associated with the predictions to be conveyed to the stakeholders, avoiding a wrong or overly optimistic interpretation of the results.
Prediction intervals
A prediction interval gives us a range in which we expect to lie with a specified probability. For example, if we assume that the distribution of future observations follows a normal distribution, a 95% prediction interval for the forecast of step h would be represented by the range Where is an estimate of the standard deviation of the h -step forecast distribution. More generally, a prediction interval can be written as In this context, the term “multiplier c” is associated with the probability of coverage. In this article, intervals of 80% and 95% are typically calculated, but any other percentage can be used. The table below shows the values of c corresponding to different coverage probabilities, assuming a normal forecast distribution.
Prediction intervals are valuable because they reflect the uncertainty
in the predictions. If we only generate point forecasts, we cannot
assess how accurate those forecasts are. However, by providing
prediction intervals, the amount of uncertainty associated with each
forecast becomes apparent. For this reason, point forecasts may lack
significant value without the inclusion of corresponding forecast
intervals.
One-step prediction intervals
When making a prediction for a future step, it is possible to estimate the standard deviation of the forecast distribution using the standard deviation of the residuals, which is calculated by where is the number of parameters estimated in the forecasting method, and is the number of missing values in the residuals. (For example, for a naive forecast, because we can’t forecast the first observation.)Multi-step prediction intervals
A typical feature of forecast intervals is that they tend to increase in length as the forecast horizon lengthens. As we move further out in time, there is greater uncertainty associated with the prediction, resulting in wider prediction intervals. In general, σh tends to increase as h increases (although there are some nonlinear forecasting methods that do not follow this property). To generate a prediction interval, it is necessary to have an estimate of σh. As mentioned above, for one-step forecasts (h=1), equation (1) provides a good estimate of the standard deviation of the forecast, σ1. However, for multi-step forecasts, a more complex calculation method is required. These calculations assume that the residuals are uncorrelated with each other.Benchmark methods
For the four benchmark methods, it is possible to mathematically derive the forecast standard deviation under the assumption of uncorrelated residuals. If denotes the standard deviation of the -step forecast distribution, and is the residual standard deviation given by (1), then we can use the expressions shown in next Table. Note that when and is large, these all give the same approximate value .
Note that when and is large, these all give the same
approximate value .
Prediction intervals from bootstrapped residuals
When a normal distribution for the residuals is an unreasonable assumption, one alternative is to use bootstrapping, which only assumes that the residuals are uncorrelated with constant variance. We will illustrate the procedure using a naïve forecasting method. A one-step forecast error is defined as . For a naïve forecasting method, , so we can rewrite this as Assuming future errors will be similar to past errors, when we can replace by sampling from the collection of errors we have seen in the past (i.e., the residuals). So we can simulate the next observation of a time series using where is a randomly sampled error from the past, and is the possible future value that would arise if that particular error value occurred. We use We use a * to indicate that this is not the observed value, but one possible future that could occur. Adding the new simulated observation to our data set, we can repeat the process to obtain where is another draw from the collection of residuals. Continuing in this way, we can simulate an entire set of future values for our time series.Conformal Prediction
Multi-quantile losses and statistical models can provide provide prediction intervals, but the problem is that these are uncalibrated, meaning that the actual frequency of observations falling within the interval does not align with the confidence level associated with it. For example, a calibrated 95% prediction interval should contain the true value 95% of the time in repeated sampling. An uncalibrated 95% prediction interval, on the other hand, might contain the true value only 80% of the time, or perhaps 99% of the time. In the first case, the interval is too narrow and underestimates the uncertainty, while in the second case, it is too wide and overestimates the uncertainty. Statistical methods also assume normality. Here, we talk about another method called conformal prediction that doesn’t require any distributional assumptions. Conformal prediction intervals use cross-validation on a point forecaster model to generate the intervals. This means that no prior probabilities are needed, and the output is well-calibrated. No additional training is needed, and the model is treated as a black box. The approach is compatible with any model mlforecast now supports Conformal Prediction on all available models.Installing mlforecast
-
using pip:
pip install mlforecast -
using with conda:
conda install -c conda-forge mlforecast
Loading libraries and data
Read Data
The input to MlForecast is always a data frame in long format with three
columns: unique_id, ds and y:
-
The
unique_id(string, int or category) represents an identifier for the series. -
The
ds(datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. -
The
y(numeric) represents the measurement we wish to forecast.
Explore Data with the plot method
Plot some series using the plot method from the StatsForecast class. This method prints 8 random series from the dataset and is useful for basic EDA.
The Augmented Dickey-Fuller Test
The Augmented Dickey-Fuller (ADF) test is a type of statistical test that determines whether a unit root is present in time series data. Unit roots can cause unpredictable results in time series analysis. A null hypothesis is formed in the unit root test to determine how strongly time series data is affected by a trend. By accepting the null hypothesis, we accept the evidence that the time series data is not stationary. By rejecting the null hypothesis or accepting the alternative hypothesis, we accept the evidence that the time series data is generated by a stationary process. This process is also known as stationary trend. The values of the ADF test statistic are negative. Lower ADF values indicate a stronger rejection of the null hypothesis. Augmented Dickey-Fuller Test is a common statistical test used to test whether a given time series is stationary or not. We can achieve this by defining the null and alternate hypothesis.- Null Hypothesis: Time Series is non-stationary. It gives a time-dependent trend.
- Alternate Hypothesis: Time Series is stationary. In another term, the series doesn’t depend on time.
- ADF or t Statistic < critical values: Reject the null hypothesis, time series is stationary.
- ADF or t Statistic > critical values: Failed to reject the null hypothesis, time series is non-stationary.
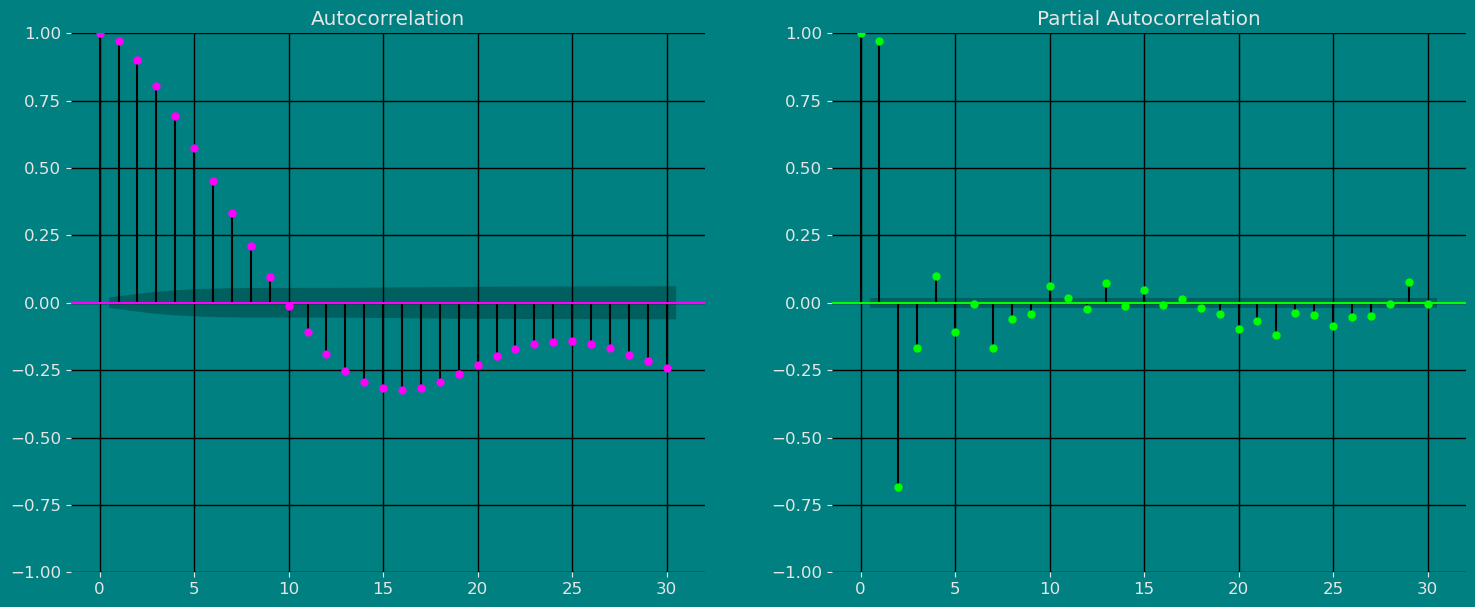
Autocorrelation plots
Autocorrelation Function
Definition 1. Let be a time series sample of size n from . 1. is called the sample mean of . 2. is known as the sample autocovariance function of . 3. is said to be the sample autocorrelation function of . Note the following remarks about this definition:- Like most literature, this guide uses ACF to denote the sample autocorrelation function as well as the autocorrelation function. What is denoted by ACF can easily be identified in context.
- Clearly c0 is the sample variance of . Besides, and for any integer .
- When we compute the ACF of any sample series with a fixed length , we cannot put too much confidence in the values of for large k’s, since fewer pairs of are available for calculating as is large. One rule of thumb is not to estimate for , and another is . In any case, it is always a good idea to be careful.
- We also compute the ACF of a nonstationary time series sample by Definition 1. In this case, however, the ACF or very slowly or hardly tapers off as increases.
- Plotting the ACF against lag is easy but very helpful in analyzing time series sample. Such an ACF plot is known as a correlogram.
- If is stationary with and for all , that is, it is a white noise series, then the sampling distribution of is asymptotically normal with the mean 0 and the variance of . Hence, there is about 95% chance that falls in the interval .
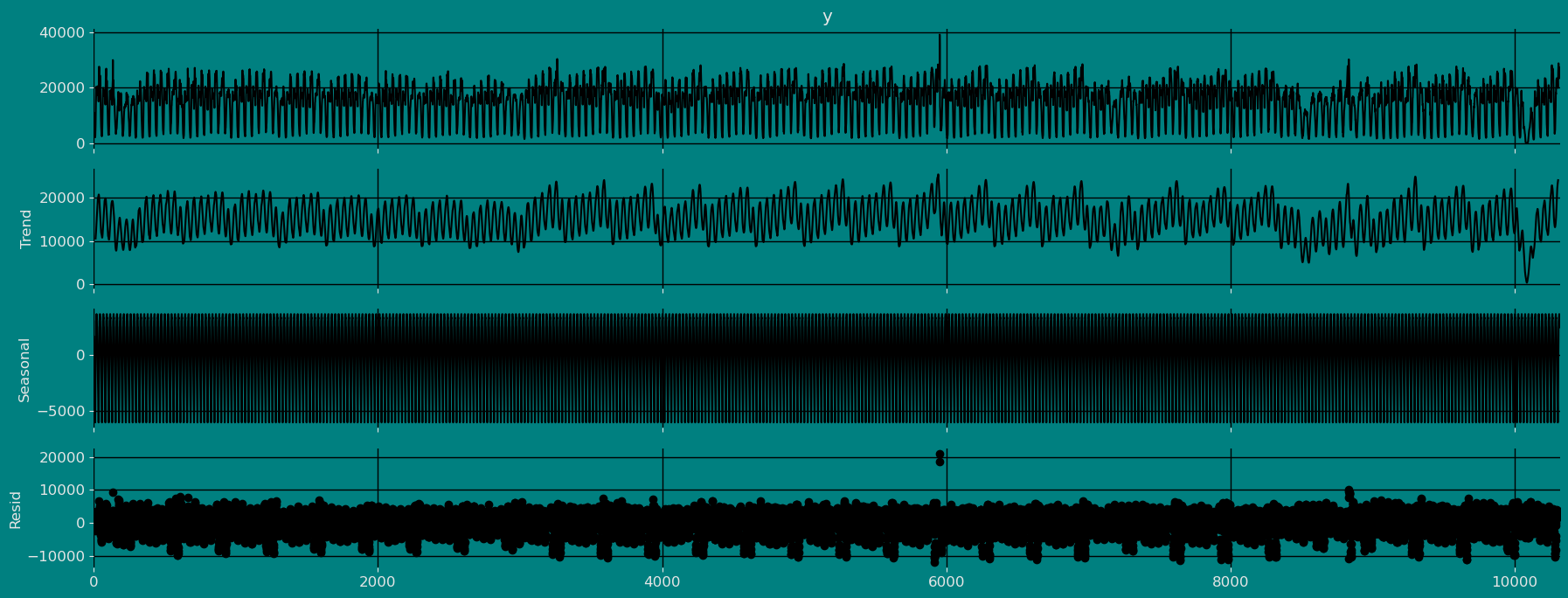
Decomposition of the time series
How to decompose a time series and why? In time series analysis to forecast new values, it is very important to know past data. More formally, we can say that it is very important to know the patterns that values follow over time. There can be many reasons that cause our forecast values to fall in the wrong direction. Basically, a time series consists of four components. The variation of those components causes the change in the pattern of the time series. These components are:- Level: This is the primary value that averages over time.
- Trend: The trend is the value that causes increasing or decreasing patterns in a time series.
- Seasonality: This is a cyclical event that occurs in a time series for a short time and causes short-term increasing or decreasing patterns in a time series.
- Residual/Noise: These are the random variations in the time series.
Multiplicative time series
If the components of the time series are multiplicative together, then the time series is called a multiplicative time series. For visualization, if the time series is having exponential growth or decline with time, then the time series can be considered as the multiplicative time series. The mathematical function of the multiplicative time series can be represented as.Additive
Multiplicative
Split the data into training and testing
Let’s divide our data into sets 1. Data to train our model. 2. Data to test our model For the test data we will use the last 500 hours to test and evaluate the performance of our model.
Modeling with mlforecast
Building Model
We define the model that we want to use, for our example we are going to use theXGBoost model.
MLForecast.preprocess method to explore different
transformations.
If it is true that the series we are working with is a stationary series
see (Dickey fuller test), however for the sake of practice and
instruction in this guide, we will apply the difference to our series,
we will do this using the target_transforms parameter and calling the
diff function like: mlforecast.target_transforms.Differences
target_transforms=[Differences([1])] in case the series is stationary
we can use a difference, or in the case that the series is not
stationary, we can use more than one difference so that the series is
constant over time, that is, that it is constant in mean and in
variance.
This has subtracted the lag 1 from each value, we can see what our
series look like now.

Adding features
Lags
Looks like the seasonality is gone, we can now try adding some lag features.Lag transforms
Lag transforms are defined as a dictionary where the keys are the lags and the values are lists of the transformations that we want to apply to that lag. You can refer to the lag transformations guide for more details.
You can see that both approaches get to the same result, you can use
whichever one you feel most comfortable with.
Date features
If your time column is made of timestamps then it might make sense to extract features like week, dayofweek, quarter, etc. You can do that by passing a list of strings with pandas time/date components. You can also pass functions that will take the time column as input, as we’ll show here.Fit the Model
XGBoost model. We
can observe it with the following instruction:
Let us now visualize the fitted values of our models.
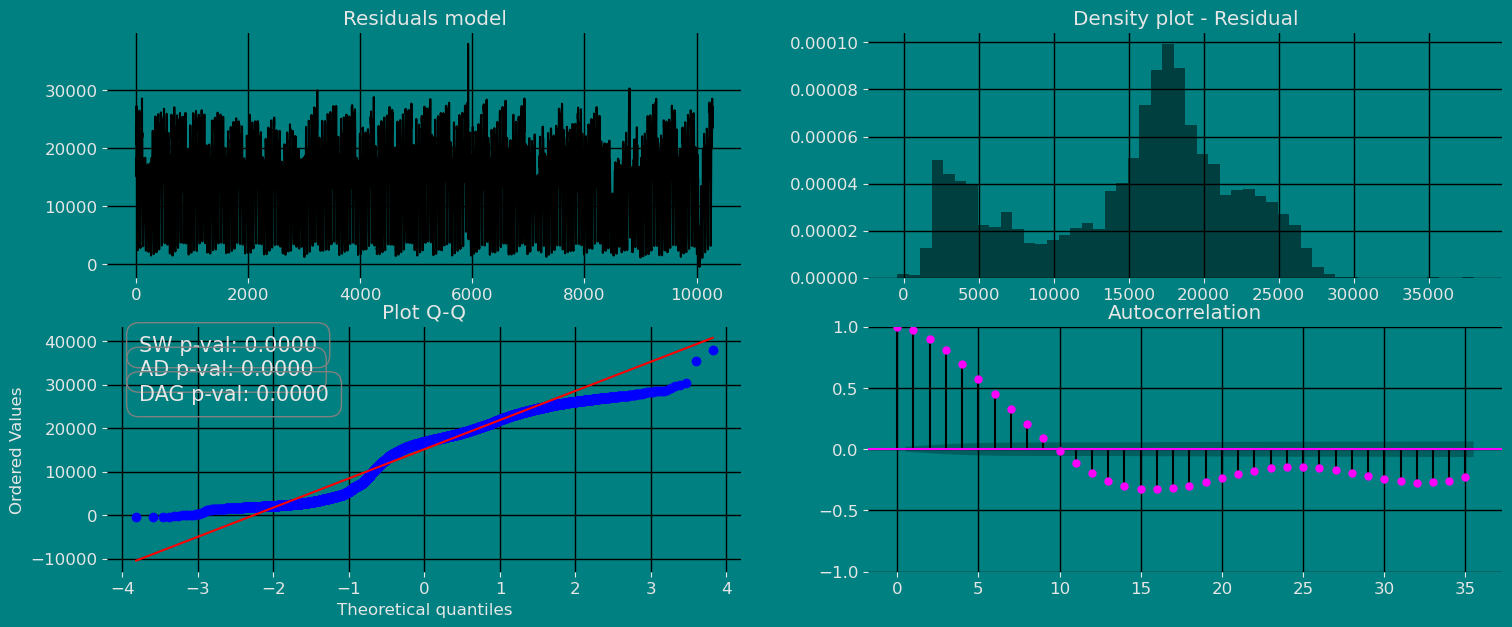
Predict method with prediction intervals
To generate forecasts use the predict method.Plot prediction intervals
Now let’s visualize the result of our forecast and the historical data of our time series, also let’s draw the confidence interval that we have obtained when making the prediction with 95% confidence.
References
- Changquan Huang • Alla Petukhina. Springer series (2022). Applied Time Series Analysis and Forecasting with Python.
- Ivan Svetunkov. Forecasting and Analytics with the Augmented Dynamic Adaptive Model (ADAM)
- James D. Hamilton. Time Series Analysis Princeton University Press, Princeton, New Jersey, 1st Edition, 1994.
- Nixtla Parameters for Mlforecast
- Pandas available frequencies.
- Rob J. Hyndman and George Athanasopoulos (2018). “Forecasting principles and practice, Time series cross-validation”..
- Seasonal periods- Rob J Hyndman.