

In this example we will show how to perform electricity load forecasting using MLForecast alongside many models. We also compare them against the prophet library.
Introduction
Some time series are generated from very low frequency data. These data generally exhibit multiple seasonalities. For example, hourly data may exhibit repeated patterns every hour (every 24 observations) or every day (every 24 * 7, hours per day, observations). This is the case for electricity load. Electricity load may vary hourly, e.g., during the evenings electricity consumption may be expected to increase. But also, the electricity load varies by week. Perhaps on weekends there is an increase in electrical activity. In this example we will show how to model the two seasonalities of the time series to generate accurate forecasts in a short time. We will use hourly PJM electricity load data. The original data can be found here.Libraries
In this example we will use the following libraries:mlforecast. Accurate and ⚡️ fast forecasting with classical machine learning models.prophet. Benchmark model developed by Facebook.utilsforecast. Library with different functions for forecasting evaluation.
Forecast using Multiple Seasonalities
Electricity Load Data
According to the dataset’s page,PJM Interconnection LLC (PJM) is a regional transmission organization (RTO) in the United States. It is part of the Eastern Interconnection grid operating an electric transmission system serving all or parts of Delaware, Illinois, Indiana, Kentucky, Maryland, Michigan, New Jersey, North Carolina, Ohio, Pennsylvania, Tennessee, Virginia, West Virginia, and the District of Columbia. The hourly power consumption data comes from PJM’s website and are in megawatts (MW).Let’s take a look to the data.

32,896 observations, so it is
necessary to use very computationally efficient methods to display them
in production.
We are going to split our series in order to create a train and test
set. The model will be tested using the last 24 hours of the timeseries.
Analizing Seasonalities
First we must visualize the seasonalities of the model. As mentioned before, the electricity load presents seasonalities every 24 hours (Hourly) and every 24 * 7 (Daily) hours. Therefore, we will use[24, 24 * 7] as the seasonalities for the model. In order to analize
how they affect our series we are going to use the Difference method.
MLForecast.preprocess method to explore different
transformations. It looks like these series have a strong seasonality on
the hour of the day, so we can subtract the value from the same hour in
the previous day to remove it. This can be done with the
mlforecast.target_transforms.Differences transformer, which we pass
through target_transforms.
In order to analize the trends individually and combined we are going to
plot them individually and combined. Therefore, we can compare them
against the original series. We can use the next function for that.
24 hours (daily) and 24*7
(weekly) we are going to subtract them from the serie using
Differences([24, 24*7]) and plot them.
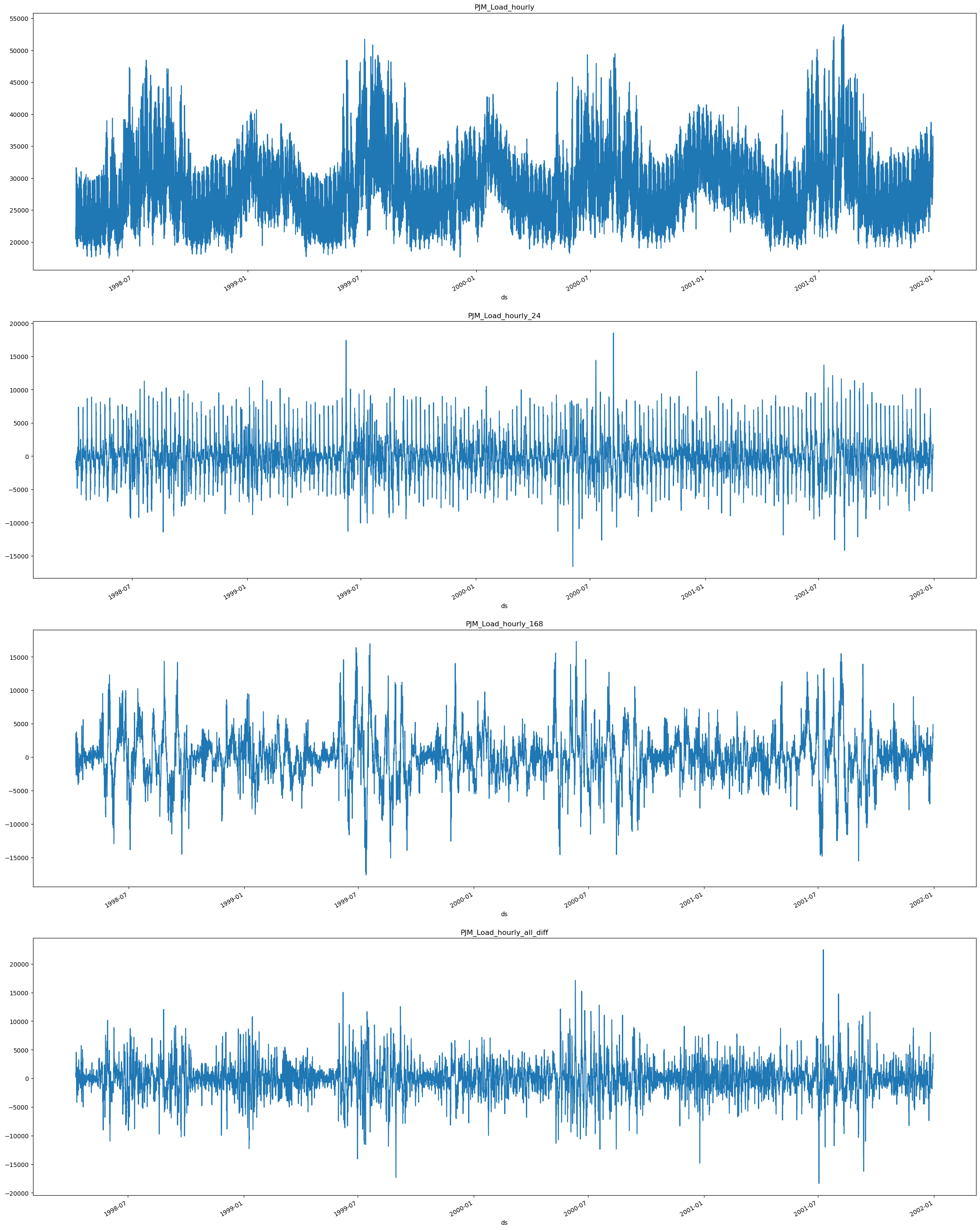
PJM_Load_hourly_24 the series seem to stabilize since the peaks seem
more uniform in comparison with the original series PJM_Load_hourly.
When we extract the 24*7 (weekly) PJM_Load_hourly_168 difference we
can see there is more periodicity in the peaks in comparison with the
original series.
Finally we can see the result from the combined result from subtracting
all the differences PJM_Load_hourly_all_diff.
For modeling we are going to use both difference for the forecasting,
therefore we are setting the argument target_transforms from the
MLForecast object equal to [Differences([24, 24*7])], if we wanted
to include a yearly difference we would need to add the term 24*365.
Model Selection with Cross-Validation
We can test many models simultaneously using MLForecastcross_validation. We can import lightgbm and scikit-learn models
and try different combinations of them, alongside different target
transformations (as the ones we created previously) and historical
variables.You can see an in-depth tutorial on how to use
MLForecast Cross
Validation methods
here
Naive model that uses the electricity load
of the last hour as prediction lag1 as showed in the next cell. You
can create your own models and try them with MLForecast using the same
structure.
scikit-learn library: Lasso,
LinearRegression, Ridge, KNN, MLP and Random Forest alongside
the LightGBM. You can add any model to the dictionary to train and
compare them by adding them to the dictionary (models) as shown.
MLForecast class with the models we want to
try along side target_transforms, lags, lag_transforms, and
date_features. All this features are applied to the models we
selected.
In this case we use the 1st, 12th and 24th lag, which are passed as a
list. Potentially you could pass a range.
Here we add month, hour and dayofweek features:
cross_validation method to train and evalaute the
models. + df: Receives the training data + h: Forecast horizon +
n_windows: The number of folds we want to predict
You can specify the names of the time series id, time and target
columns. + id_col:Column that identifies each serie ( Default
unique_id ) + time_col: Column that identifies each timestep, its
values can be timestamps or integer( Default ds ) +
target_col:Column that contains the target ( Default y )
Now we can plot each model and window (fold) to see how it behaves
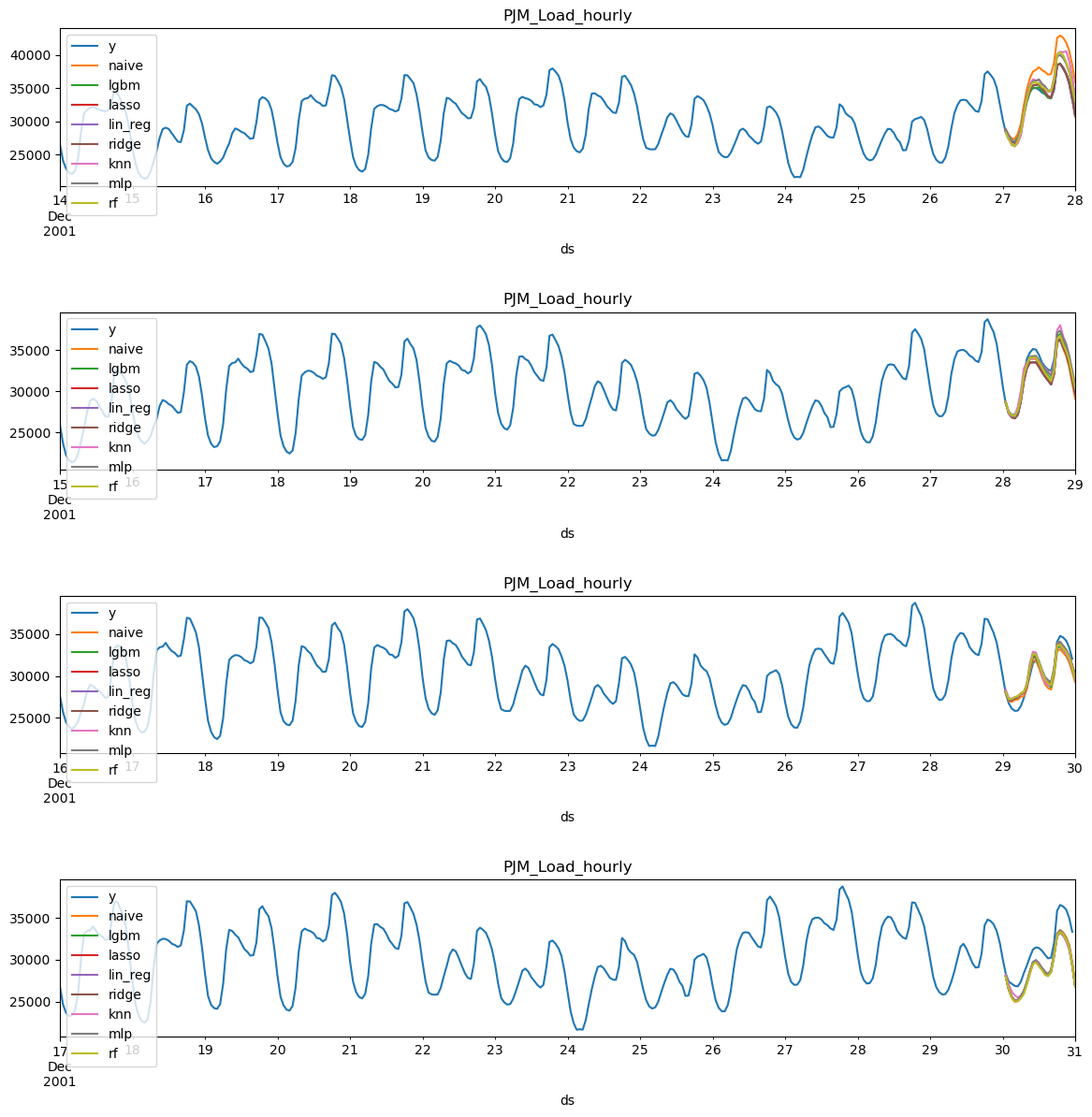
We can see that the model
lgbm has top performance in most metrics
followed by the lasso regression. Both models perform way better than
the naive.
Test Evaluation
Now we are going to evaluate their performance in the test set. We can use both of them for forecasting the test alongside some prediction intervals. For that we can use thePredictionIntervals
function in mlforecast.utils.You can see an in-depth tutorial of Probabilistic Forecasting here
fit method, which takes the
following arguments:
df: Series data in long format.id_col: Column that identifies each series. In our case, unique_id.time_col: Column that identifies each timestep, its values can be timestamps or integers. In our case, ds.target_col: Column that contains the target. In our case, y.
PredictionIntervals function is used to compute prediction
intervals for the models using Conformal
Prediction.
The function takes the following arguments: + n_windows: represents
the number of cross-validation windows used to calibrate the intervals +
h: the forecast horizon
predict method so we can compare them to our test
data. Additionally, we are going to create prediction intervals at
levels [90,95].
The
predict method returns a DataFrame witht the predictions for each
model (lasso and lgbm) along side the prediction tresholds. The
high-threshold is indicated by the keyword hi, the low-threshold by
the keyword lo, and the level by the number in the column names.
Now we can evaluate the metrics and performance in the
test set.
We can see that the
lasso regression performed slightly better than
the LightGBM for the test set. Additionally, we can also plot the
forecasts alongside their prediction intervals. For that we can use the
plot_series method available in utilsforecast.plotting.
We can plot one or many models at once alongside their confidence
intervals.

Comparison with Prophet
One of the most widely used models for time series forecasting isProphet. This model is known for its ability to model different
seasonalities (weekly, daily yearly). We will use this model as a
benchmark to see if the lgbm alongside MLForecast adds value for
this time series.
As we can see
lgbm had consistently better metrics than prophet.
lgbm with MLForecast was able to provide metrics at
least twice as good as Prophet as seen in the column improvement
above, and way faster.