

NHITS specializes its partial outputs in the different frequencies of
the time series through hierarchical interpolation and multi-rate input
processing. We model the target time-series with Student’s
t-distribution. The NHITS will output the distribution parameters for
each timestamp.
In this notebook we show how to use NHITS on the
ETTm2 benchmark dataset for
probabilistic forecasting. This data set includes data points for 2
Electricity Transformers at 2 stations, including load, oil temperature.
We will show you how to load data, train, and perform automatic
hyperparameter tuning, to achieve SoTA performance, outperforming
even the latest Transformer architectures for a fraction of their
computational cost (50x faster).
You can run these experiments using GPU with Google Colab.
1. Libraries
2. Load ETTm2 Data
TheLongHorizon class will automatically download the complete ETTm2
dataset and process it.
It return three Dataframes: Y_df contains the values for the target
variables, X_df contains exogenous calendar features and S_df
contains static features for each time-series (none for ETTm2). For this
example we will only use Y_df.
If you want to use your own data just replace Y_df. Be sure to use a
long format and have a similar structure to our data set.
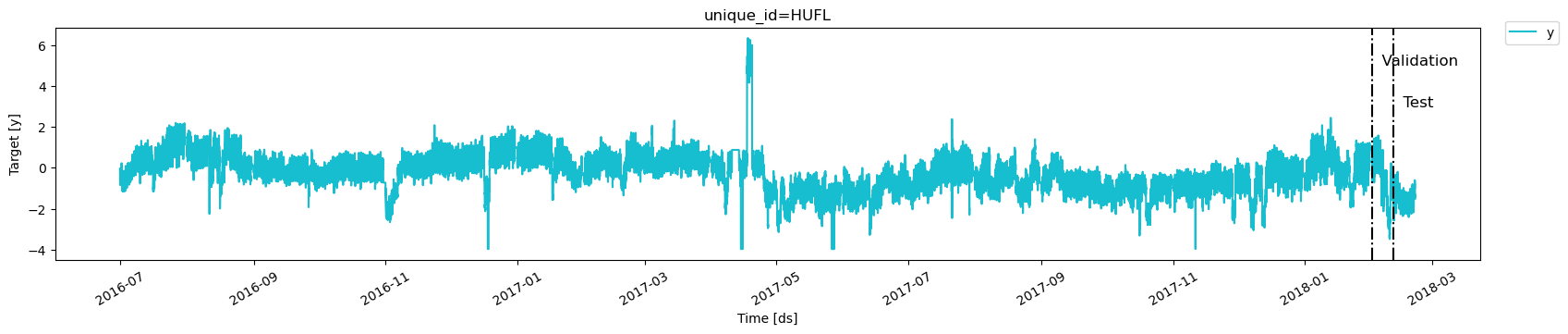
Important DataFrames must include allNext, plot the['unique_id', 'ds', 'y']columns. Make sureycolumn does not have missing or non-numeric values.
HUFL variable marking the validation and train splits.
3. Hyperparameter selection and forecasting
TheAutoNHITS class will automatically perform hyperparamter tunning
using Tune library,
exploring a user-defined or default search space. Models are selected
based on the error on a validation set and the best model is then stored
and used during inference.
The AutoNHITS.default_config attribute contains a suggested
hyperparameter space. Here, we specify a different search space
following the paper’s hyperparameters. Notice that 1000 Stochastic
Gradient Steps are enough to achieve SoTA performance. Feel free to
play around with this space.
Tip Refer to https://docs.ray.io/en/latest/tune/index.html for more information on the different space options, such as lists and continous intervals.mTo instantiate
AutoNHITS you need to define:
h: forecasting horizonloss: training loss. Use theDistributionLossto produce probabilistic forecasts.config: hyperparameter search space. IfNone, theAutoNHITSclass will use a pre-defined suggested hyperparameter space.num_samples: number of configurations explored.
NeuralForecast object with the
following required parameters:
-
models: a list of models. -
freq: a string indicating the frequency of the data. (See panda’s available frequencies.)
cross_validation method allows you to simulate multiple historic
forecasts, greatly simplifying pipelines by replacing for loops with
fit and predict methods.
With time series data, cross validation is done by defining a sliding
window across the historical data and predicting the period following
it. This form of cross validation allows us to arrive at a better
estimation of our model’s predictive abilities across a wider range of
temporal instances while also keeping the data in the training set
contiguous as is required by our models.
The cross_validation method will use the validation set for
hyperparameter selection, and will then produce the forecasts for the
test set.
4. Visualization
Finally, we merge the forecasts with theY_df dataset and plot the
forecasts.
