

Introduction
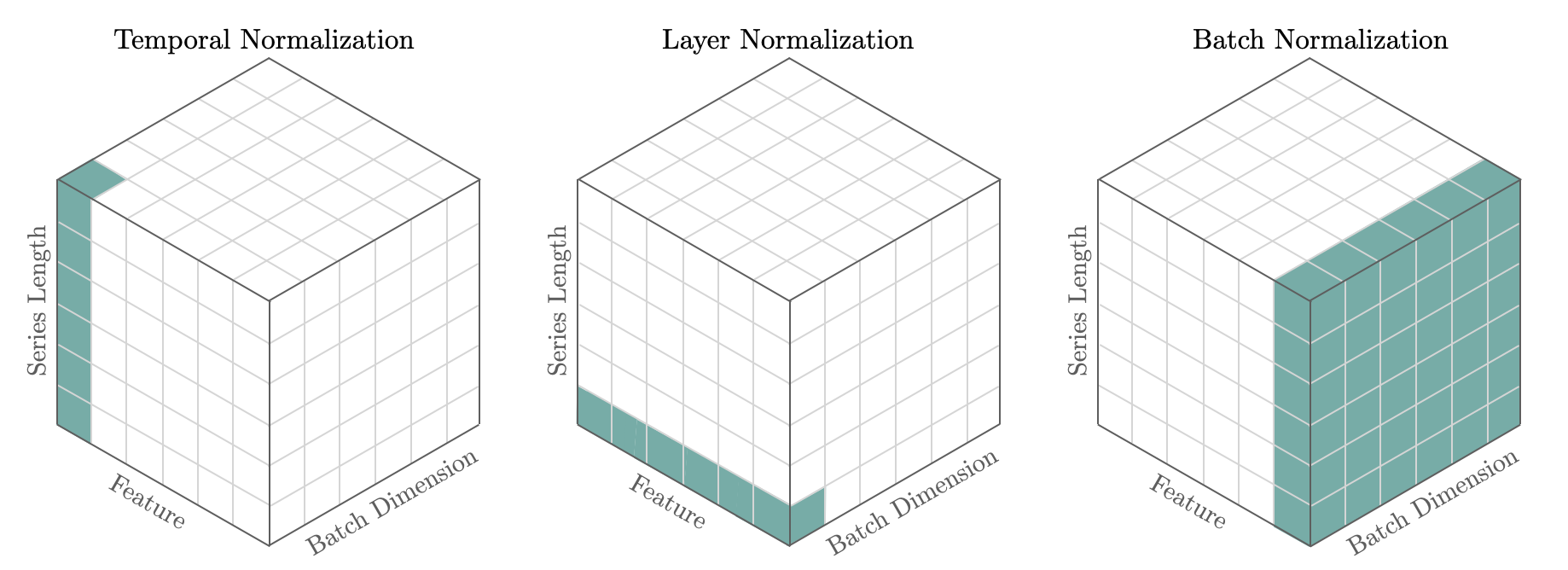
Temporal normalization has proven to be essential in neural forecasting tasks, as it enables network’s non-linearities to express themselves. Forecasting scaling methods take particular interest in the temporal dimension where most of the variance dwells, contrary to other deep learning techniques likeBatchNorm that normalizes across batch and temporal dimensions, and
LayerNorm that normalizes across the feature dimension. Currently we support the following techniques: std, median, norm, norm1, invariant,
revin.
References
- Kin G. Olivares, David Luo, Cristian Challu, Stefania La Vattiata, Max Mergenthaler, Artur Dubrawski (2023). “HINT: Hierarchical Mixture Networks For Coherent Probabilistic Forecasting”. Neural Information Processing Systems, submitted. Working Paper version available at arxiv.
- Taesung Kim and Jinhee Kim and Yunwon Tae and Cheonbok Park and Jang-Ho Choi and Jaegul Choo. “Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift”. ICLR 2022.
- David Salinas, Valentin Flunkert, Jan Gasthaus, Tim Januschowski (2020). “DeepAR: Probabilistic forecasting with autoregressive recurrent networks”. International Journal of Forecasting.
1. Auxiliary Functions
masked_median
x along dim, ignoring values where
mask is False. x and mask need to be broadcastable.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
x | Tensor | Tensor to compute median of along dim dimension. | required |
mask | Tensor | Tensor bool with same shape as x, where x is valid and False where x should be masked. Mask should not be all False in any column of dimension dim to avoid NaNs from zero division. | required |
dim | int | Dimension to take median of. Defaults to -1. | -1 |
keepdim | bool | Keep dimension of x or not. Defaults to True. | True |
| Type | Description |
|---|---|
| torch.Tensor: Normalized values. |
masked_mean
x along dimension, ignoring values where
mask is False. x and mask need to be broadcastable.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
x | Tensor | Tensor to compute mean of along dim dimension. | required |
mask | Tensor | Tensor bool with same shape as x, where x is valid and False where x should be masked. Mask should not be all False in any column of dimension dim to avoid NaNs from zero division. | required |
dim | int | Dimension to take mean of. Defaults to -1. | -1 |
keepdim | bool | Keep dimension of x or not. Defaults to True. | True |
| Type | Description |
|---|---|
| torch.Tensor: Normalized values. |
2. Scalers
minmax_statistics
| Name | Type | Description | Default |
|---|---|---|---|
x | Tensor | Input tensor. | required |
mask | Tensor | Tensor bool, same dimension as x, indicates where x is valid and False where x should be masked. Mask should not be all False in any column of dimension dim to avoid NaNs from zero division. | required |
eps | float | Small value to avoid division by zero. Defaults to 1e-6. | 1e-06 |
dim | int | Dimension over to compute min and max. Defaults to -1. | -1 |
| Type | Description |
|---|---|
torch.Tensor: Same shape as x, except scaled. |
minmax1_statistics
| Name | Type | Description | Default |
|---|---|---|---|
x | Tensor | Input tensor. | required |
mask | Tensor | Tensor bool, same dimension as x, indicates where x is valid and False where x should be masked. Mask should not be all False in any column of dimension dim to avoid NaNs from zero division. | required |
eps | float | Small value to avoid division by zero. Defaults to 1e-6. | 1e-06 |
dim | int | Dimension over to compute min and max. Defaults to -1. | -1 |
| Type | Description |
|---|---|
torch.Tensor: Same shape as x, except scaled. |
std_statistics
dim dimension.
For example, for base_windows models, the scaled features are obtained as (with dim=1):
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
x | Tensor | Input tensor. | required |
mask | Tensor | Tensor bool, same dimension as x, indicates where x is valid and False where x should be masked. Mask should not be all False in any column of dimension dim to avoid NaNs from zero division. | required |
eps | float | Small value to avoid division by zero. Defaults to 1e-6. | 1e-06 |
dim | int | Dimension over to compute mean and std. Defaults to -1. | -1 |
| Type | Description |
|---|---|
torch.Tensor: Same shape as x, except scaled. |
robust_statistics
base_windows models, the scaled features are obtained as (with dim=1):
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
x | Tensor | Input tensor. | required |
mask | Tensor | Tensor bool, same dimension as x, indicates where x is valid and False where x should be masked. Mask should not be all False in any column of dimension dim to avoid NaNs from zero division. | required |
eps | float | Small value to avoid division by zero. Defaults to 1e-6. | 1e-06 |
dim | int | Dimension over to compute median and mad. Defaults to -1. | -1 |
| Type | Description |
|---|---|
torch.Tensor: Same shape as x, except scaled. |
invariant_statistics
base_windows models, the scaled features are obtained as (with dim=1):
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
x | Tensor | Input tensor. | required |
mask | Tensor | Tensor bool, same dimension as x, indicates where x is valid and False where x should be masked. Mask should not be all False in any column of dimension dim to avoid NaNs from zero division. | required |
eps | float | Small value to avoid division by zero. Defaults to 1e-6. | 1e-06 |
dim | int | Dimension over to compute median and mad. Defaults to -1. | -1 |
| Type | Description |
|---|---|
torch.Tensor: Same shape as x, except scaled. |
identity_statistics
| Name | Type | Description | Default |
|---|---|---|---|
x | Tensor | Input tensor. | required |
mask | Tensor | Tensor bool, same dimension as x, indicates where x is valid and False where x should be masked. Mask should not be all False in any column of dimension dim to avoid NaNs from zero division. | required |
eps | float | Small value to avoid division by zero. Defaults to 1e-6. | 1e-06 |
dim | int | Dimension over to compute median and mad. Defaults to -1. | -1 |
| Type | Description |
|---|---|
torch.Tensor: Original x. |
3. TemporalNorm Module
TemporalNorm
Module
Temporal Normalization
Standardization of the features is a common requirement for many
machine learning estimators, and it is commonly achieved by removing
the level and scaling its variance. The TemporalNorm module applies
temporal normalization over the batch of inputs as defined by the type of scaler.
If scaler_type is revin learnable normalization parameters are added on top of
the usual normalization technique, the parameters are learned through scale decouple
global skip connections. The technique is available for point and probabilistic outputs.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
scaler_type | str | Defines the type of scaler used by TemporalNorm. Available [identity, standard, robust, minmax, minmax1, invariant, revin]. Defaults to “robust”. | ‘robust’ |
dim (int, optional): Dimension over to compute scale and shift. Defaults to -1.
eps (float, optional): Small value to avoid division by zero. Defaults to 1e-6.
num_features (int, optional): For RevIN-like learnable affine parameters initialization. Defaults to None.
TemporalNorm.transform
Returns:
| Type | Description |
|---|---|
torch.Tensor: Same shape as x, except scaled. |
TemporalNorm.inverse_transform
Returns:
| Type | Description |
|---|---|
| torch.Tensor: Original data. |