

1. Load and Prepare Data
We use the Australian Tourism dataset for this example.2. Compute Base Forecasts
3. Probabilistic Reconciliation Methods
Method Comparison Table
Key Technical Differences
Bootstrap vs Conformal residual handling: - Bootstrap: Adds residual blocks to raw forecasts, then applies reconciliation (SP @ (y_hat + residuals)) - Conformal: Computes scores from
reconciled forecasts, adds to reconciled predictions
(y_rec + scores)
4. Visualize Prediction Intervals
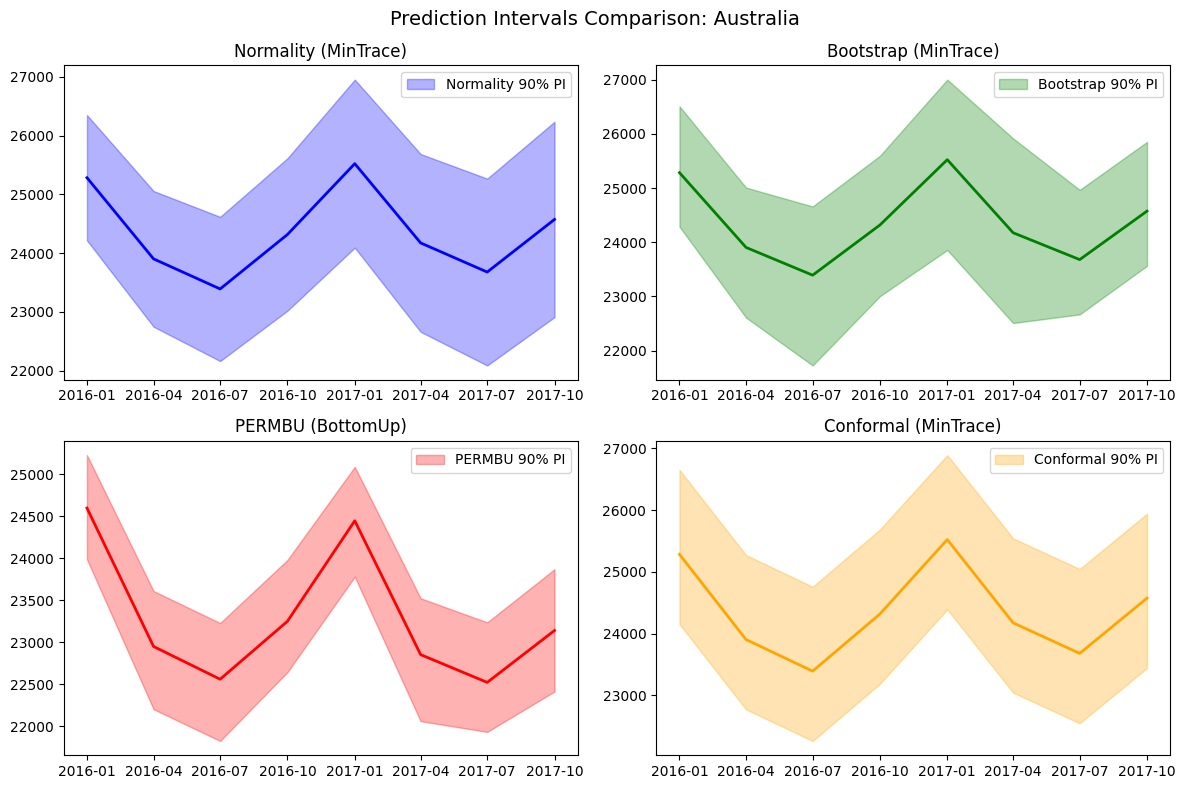
5. Evaluate Probabilistic Forecasts
We evaluate the probabilistic forecasts using the Scaled Continuous Ranked Probability Score (CRPS), which measures the quality of probabilistic predictions. Lower values indicate better calibrated prediction intervals.6. Method Pros and Cons
Normality
Pros: - Fast computation using closed-form solutions - Well-understood theoretical properties - Works with any reconciliation method and hierarchy structure - Supports different covariance estimators (ols, wls_var, mint_shrink, etc.)
Cons: - Assumes Gaussian distribution of errors - May underestimate
uncertainty for heavy-tailed or skewed distributions - Covariance
estimation can be unstable with limited data
Bootstrap
Pros: - Non-parametric: no distributional assumptions required - Captures empirical error distribution shape (skewness, heavy tails) - Preserves temporal correlation through block resampling - Works with any hierarchy structure Cons: - Requires sufficient historical residuals (at least horizon + some buffer) - Computationally more expensive than Normality - Coverage is asymptotic (no finite-sample guarantees)PERMBU
Pros: - Preserves empirical dependencies using copula-based approach - Respects marginal distributions at each level - Captures complex cross-series dependencies Cons: - Only works with strictly hierarchical structures (not grouped hierarchies) - Computationally intensive for large hierarchies - Requires careful handling of the permutation orderingConformal
Pros: - Distribution-free: no parametric assumptions required - Finite-sample coverage guarantee under exchangeability - Simple interpretation: intervals based on empirical quantiles of scores - Works with any hierarchy structure Cons: - Requires proper calibration set: Coverage guarantees assume the calibration data is independent from training data. When using in-sample residuals (fitted values from the same data used to train the model), this assumption is violated, potentially leading to overly optimistic (narrow) intervals - Exchangeability assumption may not hold for time series with trends or structural breaks - Coverage guarantees are marginal (per-series), not simultaneous across the hierarchy - May produce wider intervals than well-specified parametric methods ⚠️ Important Caveat for Conformal: In this example (and the default HierarchicalForecast API), we use in-sample fitted values as the calibration set. This is convenient but technically violates the split conformal prediction framework. For rigorous coverage guarantees, you should use a held-out validation set that was not used for model training.7. Recommendations
Decision Flowchart
- Is your hierarchy strictly hierarchical (no
cross-classifications)?
- Yes → Consider PERMBU if you need correlation preservation
- No → Use Normality, Bootstrap, or Conformal
- Do you have a proper held-out calibration set?
- Yes → Conformal provides finite-sample coverage guarantees
- No (using in-sample) → Bootstrap or Normality are more appropriate
- Do your residuals appear Gaussian?
- Yes → Normality is fast and efficient
- No / Unknown → Bootstrap adapts to any distribution