

Introduction to Hierarchical Forecasting using HierarchicalForecast
You can run these experiments using CPU or GPU with Google Colab.
1. Hierarchical Series
In many applications, a set of time series is hierarchically organized. Examples include the presence of geographic levels, products, or categories that define different types of aggregations. In such scenarios, forecasters are often required to provide predictions for all disaggregate and aggregate series. A natural desire is for those predictions to be “coherent”, that is, for the bottom series to add up precisely to the forecasts of the aggregated series.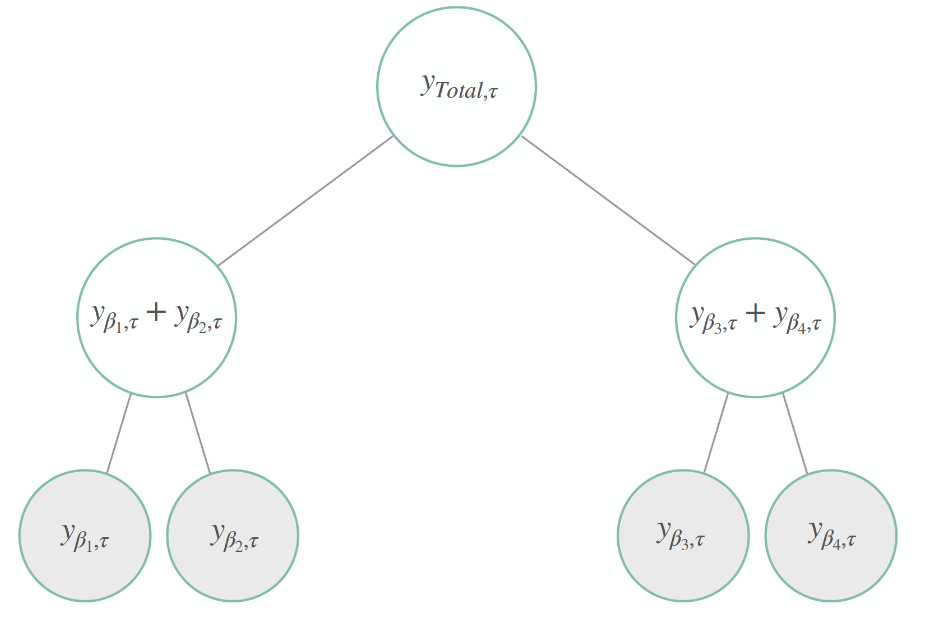 The above figure shows a simple hierarchical structure where we have
four bottom-level series, two middle-level series, and the top level
representing the total aggregation. Its hierarchical aggregations or
coherency constraints are:
Luckily these constraints can be compactly expressed with the following
matrices:
where aggregates the bottom series to the upper
levels, and is an identity matrix. The
representation of the hierarchical series is then:
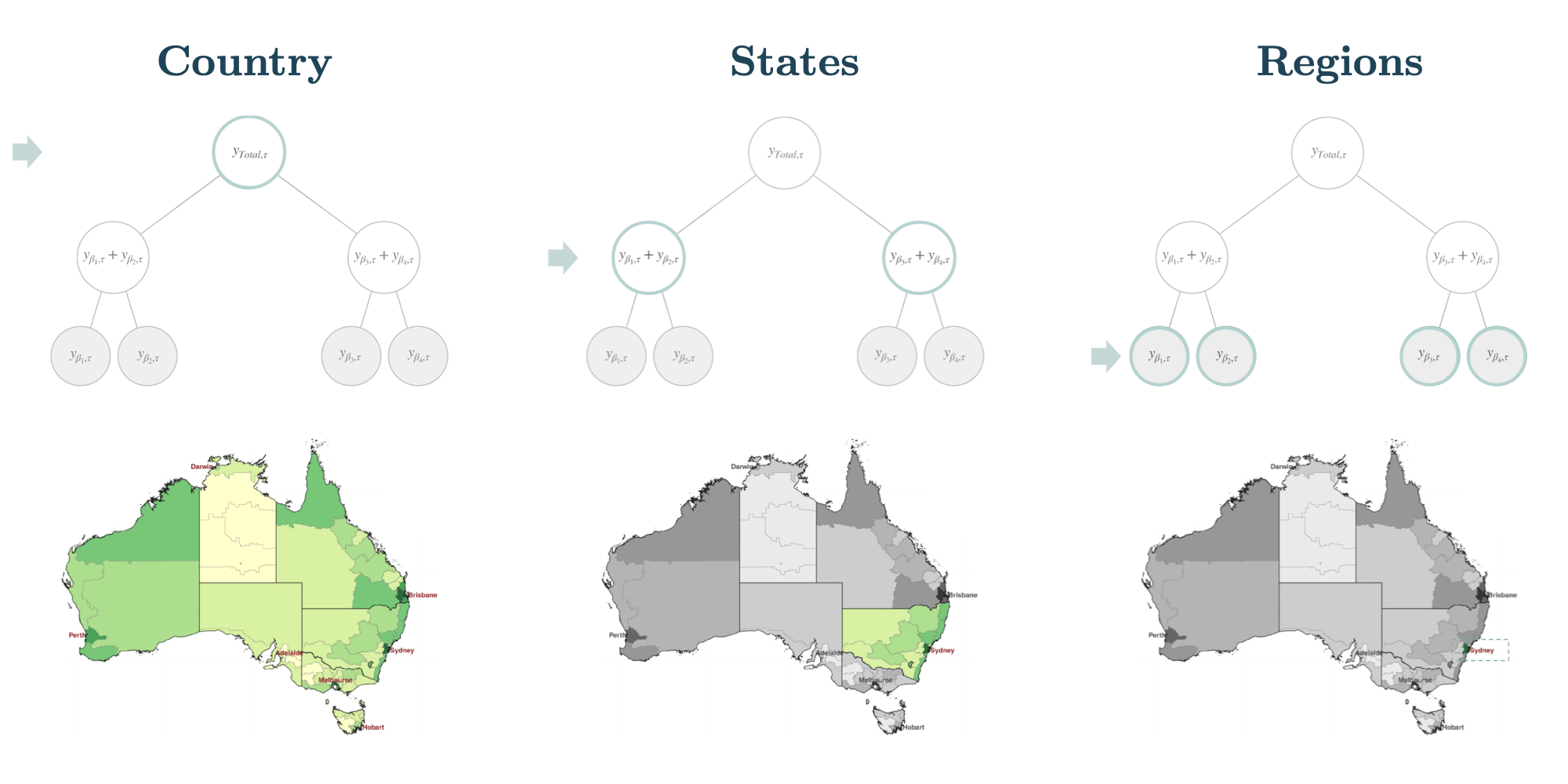
To visualize an example, in Figure 2, one can think of the hierarchical
time series structure levels to represent different geographical
aggregations. For example, in Figure 2, the top level is the total
aggregation of series within a country, the middle level being its
states and the bottom level its regions.
The above figure shows a simple hierarchical structure where we have
four bottom-level series, two middle-level series, and the top level
representing the total aggregation. Its hierarchical aggregations or
coherency constraints are:
Luckily these constraints can be compactly expressed with the following
matrices:
where aggregates the bottom series to the upper
levels, and is an identity matrix. The
representation of the hierarchical series is then:
To visualize an example, in Figure 2, one can think of the hierarchical
time series structure levels to represent different geographical
aggregations. For example, in Figure 2, the top level is the total
aggregation of series within a country, the middle level being its
states and the bottom level its regions.
2. Hierarchical Forecast
To achieve “coherency”, most statistical solutions to the hierarchical forecasting challenge implement a two-stage reconciliation process.- First, we obtain a set of the base forecast
- Later, we reconcile them into coherent forecasts .
BottomUp,
TopDown, MiddleOut, MinTrace, ERM. Among its probabilistic
coherent methods we have Normality, Bootstrap, PERMBU.
3. Minimal Example
Wrangling Data
Y_hier_df dataframe.
The aggregation constraints matrix is captured
within the S_df dataframe.
Finally tags contains a dictionary of lists within Y_hier_df
composing each hierarchical level, for example the tags['top_level']
contains Australia’s aggregated series index.
Base Predictions
Next, we compute the base forecast for each time series using thenaive model. Observe that Y_hat_df contains the forecasts but they
are not coherent.
Reconciliation
References
- Hyndman, R.J., & Athanasopoulos, G. (2021). “Forecasting:
principles and practice, 3rd edition: Chapter 11: Forecasting
hierarchical and grouped series.”. OTexts: Melbourne, Australia.
OTexts.com/fpp3 Accessed on July
2022.
- Orcutt, G.H., Watts, H.W., & Edwards, J.B.(1968). Data aggregation
and information loss. The American Economic Review, 58 ,
773(787).
- Disaggregation methods to expedite product line forecasting.
Journal of Forecasting, 9 , 233–254.
doi:10.1002/for.3980090304.
- Wickramasuriya, S. L., Athanasopoulos, G., & Hyndman, R. J. (2019).
“Optimal forecast reconciliation for hierarchical and grouped time
series through trace minimization”. Journal of the American
Statistical Association, 114 , 804–819.
doi:10.1080/01621459.2018.1448825.
- Ben Taieb, S., & Koo, B. (2019). Regularized regression for
hierarchical forecasting without unbiasedness conditions. In
Proceedings of the 25th ACM SIGKDD International Conference on
Knowledge Discovery & Data Mining KDD ’19 (p. 1337(1347). New York,
NY, USA: Association for Computing
Machinery.