Temporal Hierarchical Forecasting on Australian Tourism DataIn many applications, a set of time series is hierarchically organized. Examples include the presence of geographic levels, products, or categories that define different types of aggregations. In such scenarios, forecasters are often required to provide predictions for all disaggregate and aggregate series. A natural desire is for those predictions to be “coherent”, that is, for the bottom series to add up precisely to the forecasts of the aggregated series. In this notebook we present an example on how to use
HierarchicalForecast to produce coherent forecasts between temporal
levels. We will use the classic Australian Domestic Tourism (Tourism)
dataset, which contains monthly time series of the number of visitors to
each state of Australia.
We will first load the Tourism data and produce base forecasts using
an AutoETS model from StatsForecast. Then, we reconciliate the
forecasts with several reconciliation algorithms from
HierarchicalForecast according to a temporal hierarchy.
You can run these experiments using CPU or GPU with Google Colab.
1. Load and Process Data
In this example we will use the Tourism dataset from the Forecasting: Principles and Practice book. The dataset only contains the time series at the lowest level, so we need to create the time series for all hierarchies.2. Temporal reconciliation
First, we add aunique_id to the data.
2a. Split Train/Test sets
We use the final two years (8 quarters) as test set. Consequently, our forecast horizon=8.2a. Aggregating the dataset according to temporal hierarchy
We first define the temporal aggregation spec. The spec is a dictionary in which the keys are the name of the aggregation and the value is the amount of bottom-level timesteps that should be aggregated in that aggregation. For example,year consists of 12 months, so we define a
key, value pair "yearly":12. We can do something similar for other
aggregations that we are interested in.
In this example, we choose a temporal aggregation of year,
semiannual and quarter. The bottom level timesteps have a quarterly
frequency.
aggregate_temporal function. Note that we have different aggregation
matrices S for the train- and test set, as the test set contains
temporal hierarchies that are not included in the train set.
If you don’t have a test set available, as is usually the case when
you’re making forecasts, it is necessary to create a future dataframe
that holds the correct bottom-level unique_ids and timestamps so that
they can be temporally aggregated. We can use the
make_future_dataframe helper function for that.
Y_test_df_new can be then used in aggregate_temporal to construct
the temporally aggregated structures:
Y_test_df_new doesn’t contain the ground truth values y.
3b. Computing base forecasts
Now, we need to compute base forecasts for each temporal aggregation. The following cell computes the base forecasts for each temporal aggregation inY_train_df using the AutoETS model. Observe that
Y_hat_df contains the forecasts but they are not coherent.
Note also that both frequency and horizon are different for each
temporal aggregation. In this example, the lowest level has a quarterly
frequency, and a horizon of 8 (constituting 2 years). The year
aggregation thus has a yearly frequency with a horizon of 2.
It is of course possible to choose a different model for each level in
the temporal aggregation - you can be as creative as you like!
3c. Reconcile forecasts
We can use theHierarchicalReconciliation class to reconcile the
forecasts. In this example we use BottomUp and MinTrace. Note that
we have to set temporal=True in the reconcile function.
Note that temporal reconcilation currently isn’t supported for insample
reconciliation methods, such as MinTrace(method='mint_shrink').
4. Evaluation
TheHierarchicalForecast package includes the evaluate function to
evaluate the different hierarchies.
We evaluate the temporally aggregated forecasts across all temporal
aggregations.
MinTrace(ols) is the best overall point method, scoring the lowest
mae on the year and semiannual aggregated forecasts as well as the
quarter bottom-level aggregated forecasts. However, the Base method
is better overall on the probabilistic measure crps, where it scores
the lowest, indicating that the uncertainty levels predicted with the
Base method are better in this example.
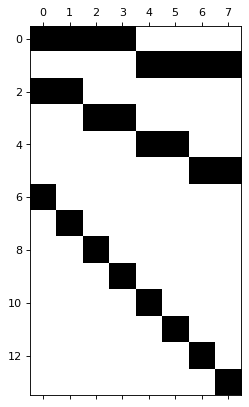
Appendix: plotting the S matrix
S matrix shows how the
aggregation 2016 can be obtained by summing the 4 quarters in 2016. *
The second row of the S matrix shows how the aggregation 2017 can be
obtained by summing the 4 quarters in 2017. * The next 4 rows show how
the semi-annual aggregations can be obtained. * The final rows are the
identity matrix for each quarter, denoting the bottom temporal level
(each quarter).