

TimeGPT, understanding the intricate needs of time series forecasting,
incorporates the cross_validation method, designed to streamline the
validation process for time series models. This functionality enables
practitioners to rigorously test their forecasting models against
historical data, assessing their effectiveness while tuning them for
optimal performance. This tutorial will guide you through the nuanced
process of conducting cross-validation within the
NixtlaClient
class, ensuring your time series forecasting models are not just
well-constructed, but also validated for trustworthiness and precision.
1. Import packages
First, we install and import the required packages and initialize the Nixtla client. We start off by initializing an instance ofNixtlaClient.
👍 Use an Azure AI endpoint To use an Azure AI endpoint, remember to set also thebase_urlargument:nixtla_client = NixtlaClient(base_url="you azure ai endpoint", api_key="your api_key")
2. Load data
Let’s see an example, using the Peyton Manning dataset.3. Cross-validation
Thecross_validation method within the TimeGPT class is an advanced
functionality crafted to perform systematic validation on time series
forecasting models. This method necessitates a dataframe comprising
time-ordered data and employs a rolling-window scheme to meticulously
evaluate the model’s performance across different time periods, thereby
ensuring the model’s reliability and stability over time. The animation
below shows how TimeGPT performs cross-validation.
 Key parameters include
Key parameters include freq, which denotes the data’s frequency and is
automatically inferred if not specified. The id_col, time_col, and
target_col parameters designate the respective columns for each
series’ identifier, time step, and target values. The method offers
customization through parameters like n_windows, indicating the number
of separate time windows on which the model is assessed, and
step_size, determining the gap between these windows. If step_size
is unspecified, it defaults to the forecast horizon h.
The process also allows for model refinement via finetune_steps,
specifying the number of iterations for model fine-tuning on new data.
Data pre-processing is manageable through clean_ex_first, deciding
whether to cleanse the exogenous signal prior to forecasting.
Additionally, the method supports enhanced feature engineering from time
data through the date_features parameter, which can automatically
generate crucial date-related features or accept custom functions for
bespoke feature creation. The date_features_to_one_hot parameter
further enables the transformation of categorical date features into a
format suitable for machine learning models.
In execution, cross_validation assesses the model’s forecasting
accuracy in each window, providing a robust view of the model’s
performance variability over time and potential overfitting. This
detailed evaluation ensures the forecasts generated are not only
accurate but also consistent across diverse temporal contexts.
| unique_id | ds | cutoff | y | TimeGPT | |
|---|---|---|---|---|---|
| 0 | 0 | 2015-12-17 | 2015-12-16 | 7.591862 | 7.939553 |
| 1 | 0 | 2015-12-18 | 2015-12-16 | 7.528869 | 7.887512 |
| 2 | 0 | 2015-12-19 | 2015-12-16 | 7.171657 | 7.766617 |
| 3 | 0 | 2015-12-20 | 2015-12-16 | 7.891331 | 7.931502 |
| 4 | 0 | 2015-12-21 | 2015-12-16 | 8.360071 | 8.312632 |
📘 Available models in Azure AI If you are using an Azure AI endpoint, please be sure to setmodel="azureai":nixtla_client.cross_validation(..., model="azureai")For the public API, we support two models:timegpt-1andtimegpt-1-long-horizon. By default,timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.
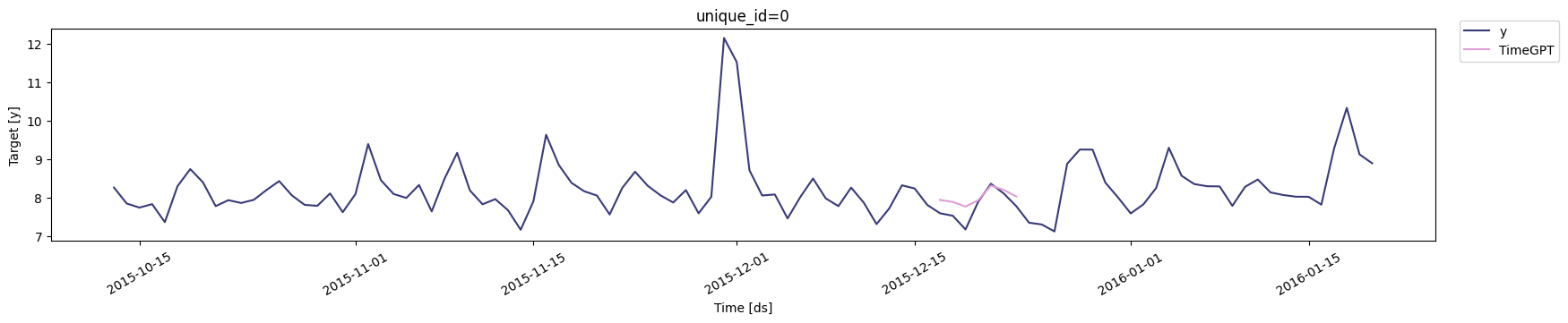
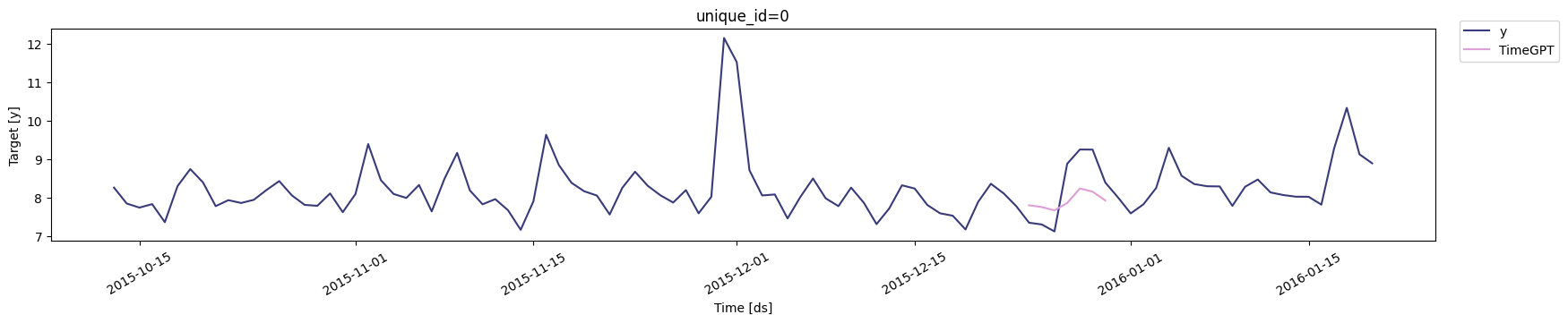
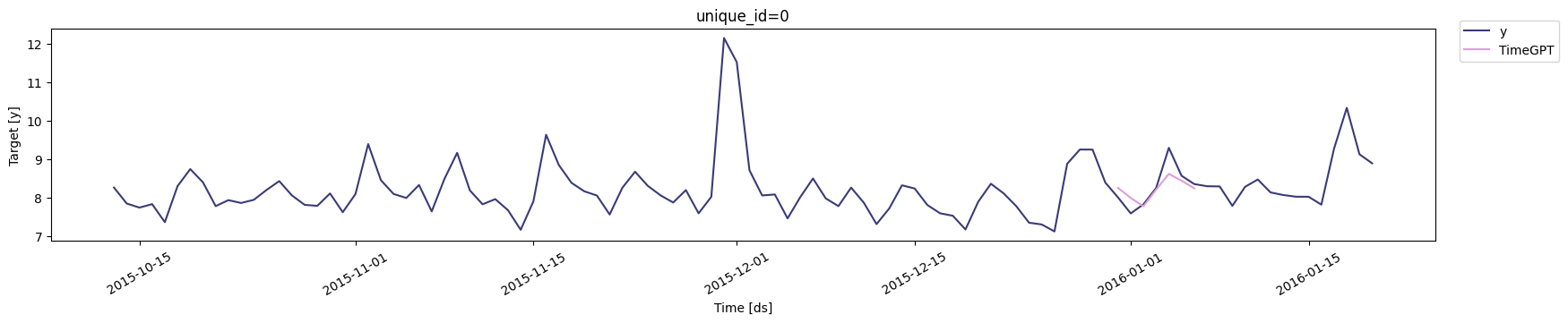
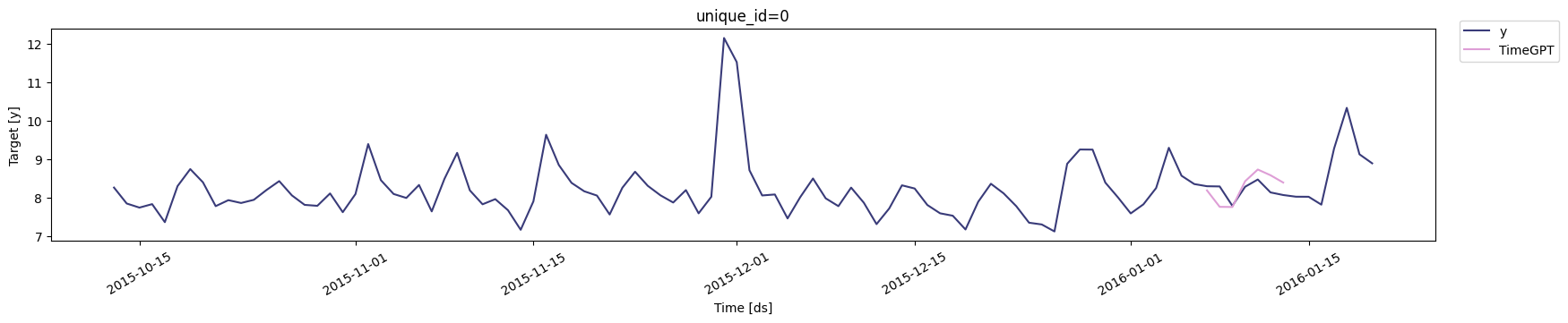
4. Cross-validation with prediction intervals
It is also possible to generate prediction intervals during cross-validation. To do so, we simply use thelevel argument.
| unique_id | ds | cutoff | y | TimeGPT | TimeGPT-hi-80 | TimeGPT-hi-90 | TimeGPT-lo-80 | TimeGPT-lo-90 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2015-12-17 | 2015-12-16 | 7.591862 | 7.939553 | 8.201465 | 8.314956 | 7.677642 | 7.564151 |
| 1 | 0 | 2015-12-18 | 2015-12-16 | 7.528869 | 7.887512 | 8.175414 | 8.207470 | 7.599609 | 7.567553 |
| 2 | 0 | 2015-12-19 | 2015-12-16 | 7.171657 | 7.766617 | 8.267363 | 8.386674 | 7.265871 | 7.146560 |
| 3 | 0 | 2015-12-20 | 2015-12-16 | 7.891331 | 7.931502 | 8.205929 | 8.369983 | 7.657075 | 7.493020 |
| 4 | 0 | 2015-12-21 | 2015-12-16 | 8.360071 | 8.312632 | 9.184893 | 9.625794 | 7.440371 | 6.999469 |
📘 Available models in Azure AI If you are using an Azure AI endpoint, please be sure to setmodel="azureai":nixtla_client.cross_validation(..., model="azureai")For the public API, we support two models:timegpt-1andtimegpt-1-long-horizon. By default,timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.





5. Cross-validation with exogenous variables
Time features
It is possible to include exogenous variables when performing cross-validation. Here we use thedate_features parameter to create
labels for each month. These features are then used by the model to make
predictions during cross-validation.
| unique_id | ds | cutoff | y | TimeGPT | TimeGPT-hi-80 | TimeGPT-hi-90 | TimeGPT-lo-80 | TimeGPT-lo-90 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 2015-12-17 | 2015-12-16 | 7.591862 | 8.426320 | 8.721996 | 8.824101 | 8.130644 | 8.028540 |
| 1 | 0.0 | 2015-12-18 | 2015-12-16 | 7.528869 | 8.049962 | 8.452083 | 8.658603 | 7.647842 | 7.441321 |
| 2 | 0.0 | 2015-12-19 | 2015-12-16 | 7.171657 | 7.509098 | 7.984788 | 8.138017 | 7.033409 | 6.880180 |
| 3 | 0.0 | 2015-12-20 | 2015-12-16 | 7.891331 | 7.739536 | 8.306914 | 8.641355 | 7.172158 | 6.837718 |
| 4 | 0.0 | 2015-12-21 | 2015-12-16 | 8.360071 | 8.027471 | 8.722828 | 9.152306 | 7.332113 | 6.902636 |





Dynamic features
Additionally you can pass dynamic exogenous variables to better informTimeGPT about the data. You just simply have to add the exogenous
regressors after the target column.
TimeGPT considering this information


📘 Available models in Azure AI If you are using an Azure AI endpoint, please be sure to setmodel="azureai":nixtla_client.cross_validation(..., model="azureai")For the public API, we support two models:timegpt-1andtimegpt-1-long-horizon. By default,timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.
6. Cross-validation with different TimeGPT instances
Also, you can generate cross validation for different instances ofTimeGPT using the model argument. Here we use the base model and the
model for long-horizon forecasting.


📘 Available models in Azure AI If you are using an Azure AI endpoint, please be sure to setmodel="azureai":nixtla_client.cross_validation(..., model="azureai")For the public API, we support two models:timegpt-1andtimegpt-1-long-horizon. By default,timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.