

api_key and give it a try yourself!
Table of Contents
1. Data introduction
In this notebook, we’re working with an aggregated dataset from the M5 Forecasting - Accuracy competition. This dataset includes 7 daily time series, each with 1,941 data points. The last 28 data points of each series are set aside as the test set, allowing us to evaluate model performance on unseen data.| ds | y | ||||||
|---|---|---|---|---|---|---|---|
| min | max | count | min | mean | median | max | |
| unique_id | |||||||
| FOODS_1 | 2011-01-29 | 2016-05-22 | 1941 | 0.0 | 2674.085523 | 2665.0 | 5493.0 |
| FOODS_2 | 2011-01-29 | 2016-05-22 | 1941 | 0.0 | 4015.984029 | 3894.0 | 9069.0 |
| FOODS_3 | 2011-01-29 | 2016-05-22 | 1941 | 10.0 | 16969.089129 | 16548.0 | 28663.0 |
| HOBBIES_1 | 2011-01-29 | 2016-05-22 | 1941 | 0.0 | 2936.122617 | 2908.0 | 5009.0 |
| HOBBIES_2 | 2011-01-29 | 2016-05-22 | 1941 | 0.0 | 279.053065 | 248.0 | 871.0 |
| HOUSEHOLD_1 | 2011-01-29 | 2016-05-22 | 1941 | 0.0 | 6039.594539 | 5984.0 | 11106.0 |
| HOUSEHOLD_2 | 2011-01-29 | 2016-05-22 | 1941 | 0.0 | 1566.840289 | 1520.0 | 2926.0 |
2. Model Fitting (TimeGPT, ARIMA, LightGBM, N-HiTS)
2.1 TimeGPT
TimeGPT offers a powerful, streamlined solution for time series forecasting, delivering state-of-the-art results with minimal effort. With TimeGPT, there’s no need for data preprocessing or feature engineering – simply initiate the Nixtla client and callnixtla_client.forecast to produce accurate, high-performance forecasts
tailored to your unique time series.
2.2 Classical Models (ARIMA):
Next, we applied ARIMA, a traditional statistical model, to the same forecasting task. Classical models use historical trends and seasonality to make predictions by relying on linear assumptions. However, they struggled to capture the complex, non-linear patterns within the data, leading to lower accuracy compared to other approaches. Additionally, ARIMA was slower due to its iterative parameter estimation process, which becomes computationally intensive for larger datasets.📘 Why Use TimeGPT over Classical Models?
- Complex Patterns: TimeGPT captures non-linear trends classical models miss.
- Minimal Preprocessing: TimeGPT requires little to no data preparation.
- Scalability: TimeGPT can efficiently scales across multiple series without retraining.
2.3 Machine Learning Models (LightGBM)
Thirdly, we used a machine learning model, LightGBM, for the same forecasting task, implemented through the automated pipeline provided by our mlforecast library. While LightGBM can capture seasonality and patterns, achieving the best performance often requires detailed feature engineering, careful hyperparameter tuning, and domain knowledge. You can try our mlforecast library to simplify this process and get started quickly!📘 Why Use TimeGPT over Machine Learning Models?
- Automatic Pattern Recognition: Captures complex patterns from raw data, bypassing the need for feature engineering.
- Minimal Tuning: Works well without extensive tuning.
- Scalability: Forecasts across multiple series without retraining.
2.4 N-HiTS
Lastly, we used N-HiTS, a state-of-the-art deep learning model designed for time series forecasting. The model produced accurate results, demonstrating its ability to capture complex, non-linear patterns within the data. However, setting up and tuning N-HiTS required significantly more time and computational resources compared to TimeGPT.📘 Why Use TimeGPT Over Deep Learning Models?
- Faster Setup: Quick setup and forecasting, unlike the lengthy configuration and training times of neural networks.
- Less Tuning: Performs well with minimal tuning and preprocessing, while neural networks often need extensive adjustments.
- Ease of Use: Simple deployment with high accuracy, making it accessible without deep technical expertise.
3. Performance Comparison and Results:
The performance of each model is evaluated using RMSE (Root Mean Squared Error) and SMAPE (Symmetric Mean Absolute Percentage Error). While RMSE emphasizes the models’ ability to control significant errors, SMAPE provides a relative performance perspective by normalizing errors as percentages. Below, we present a snapshot of performance across all groups. The results demonstrate that TimeGPT outperforms other models on both metrics. 🌟 For a deeper dive into benchmarking, check out our benchmark repository. The summarized results are displayed below:Overall Performance Metrics
| Model | RMSE | SMAPE |
|---|---|---|
| ARIMA | 724.9 | 5.50% |
| LightGBM | 687.8 | 5.14% |
| N-HiTS | 605.0 | 5.34% |
| TimeGPT | 592.6 | 4.94% |
Breakdown for Each Time-series
Followed below are the metrics for each individual time series groups. TimeGPT consistently delivers accurate forecasts across all time series groups. In many cases, it performs as well as or better than data-specific models, showing its versatility and reliability across different datasets.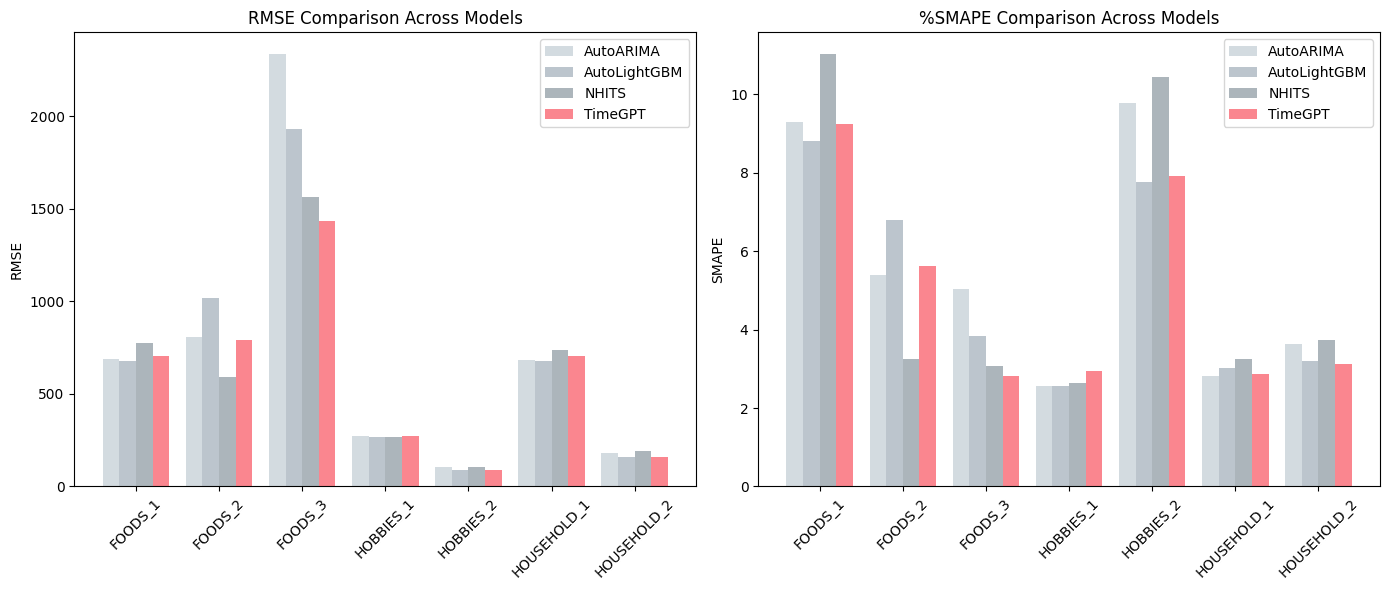
Benchmark Results
For a more comprehensive dive into model accuracy and performance, explore our Time Series Model Arena! TimeGPT continues to lead the pack with exceptional performance across benchmarks! 🌟
4. Conclusion
At the end of this notebook, we’ve put together a handy table to show you exactly where TimeGPT shines brightest compared to other forecasting models. ☀️ Think of it as your quick guide to choosing the best model for your unique project needs. We’re confident that TimeGPT will be a valuable tool in your forecasting journey. Don’t forget to visit our dashboard to generate your TimeGPTapi_key and get started today! Happy forecasting, and enjoy the
insights ahead!
| Scenario | TimeGPT | Classical Models (e.g., ARIMA) | Machine Learning Models (e.g., XGB, LGBM) | Deep Learning Models (e.g., N-HITS) |
|---|---|---|---|---|
| Seasonal Patterns | ✅ Performs well with minimal setup | ✅ Handles seasonality with adjustments (e.g., SARIMA) | ✅ Performs well with feature engineering | ✅ Captures seasonal patterns effectively |
| Non-Linear Patterns | ✅ Excels, especially with complex non-linear patterns | ❌ Limited performance | ❌ Struggles without extensive feature engineering | ✅ Performs well with non-linear relationships |
| Large Dataset | ✅ Highly scalable across many series | ❌ Slow and resource-intensive | ✅ Scalable with optimized implementations | ❌ Requires significant resources for large datasets |
| Small Dataset | ✅ Performs well; requires only one data point to start | ✅ Performs well; may struggle with very sparse data | ✅ Performs adequately if enough features are extracted | ❌ May need a minimum data size to learn effectively |
| Preprocessing Required | ✅ Minimal preprocessing needed | ❌ Requires scaling, log-transform, etc., to meet model assumptions | ❌ Requires extensive feature engineering for complex patterns | ❌ Needs data normalization and preprocessing |
| Accuracy Requirement | ✅ Achieves high accuracy with minimal tuning | ❌ May struggle with complex accuracy requirements | ✅ Can achieve good accuracy with tuning | ✅ High accuracy possible but with significant resource use |
| Scalability | ✅ Highly scalable with minimal task-specific configuration | ❌ Not easily scalable | ✅ Moderate scalability, with feature engineering and tuning per task | ❌ Limited scalability due to resource demands |
| Computational Resources | ✅ Highly efficient, operates seamlessly on CPU, no GPU needed | ✅ Light to moderate, scales poorly with large datasets | ❌ Moderate, depends on feature complexity | ❌ High resource consumption, often requires GPU |
| Memory Requirement | ✅ Efficient memory usage for large datasets | ✅ Moderate memory requirements | ❌ High memory usage for larger datasets or many series cases | ❌ High memory consumption for larger datasets and multiple series |
| Technical Requirements & Domain Knowledge | ✅ Low; minimal technical setup and no domain expertise needed | ✅ Low to moderate; needs understanding of stationarity | ❌ Moderate to high; requires feature engineering and tuning | ❌ High; complex architecture and tuning |