

1. Scale-dependent Errors
Mean Absolute Error
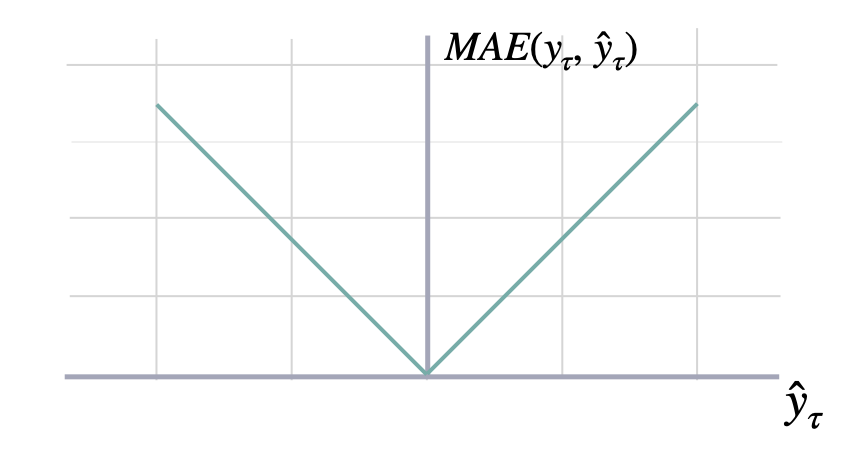
mae
Mean Squared Error
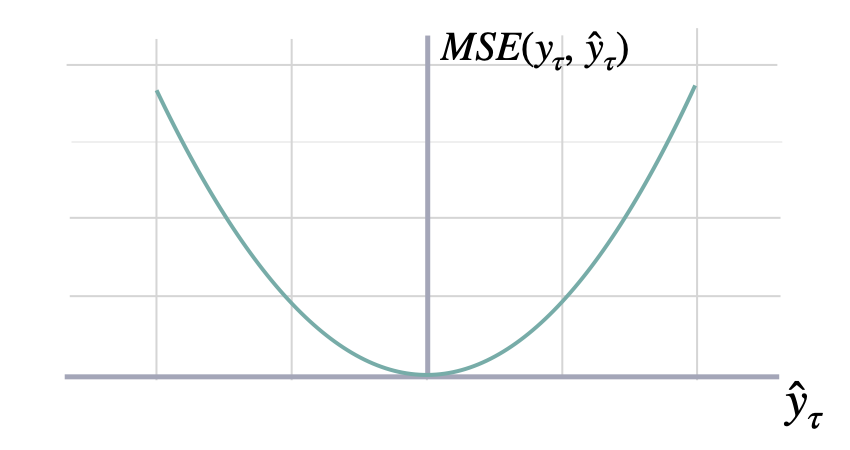
mse
Root Mean Squared Error
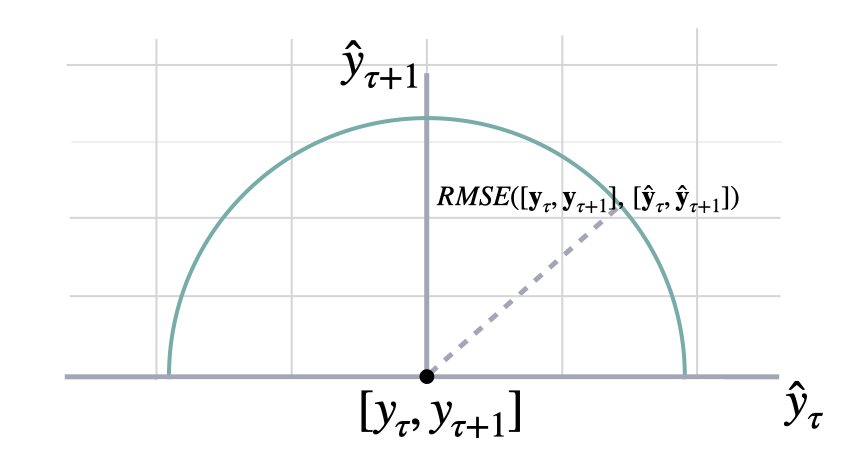
rmse
Bias
bias
Cumulative Forecast Error
cfe
Absolute Periods In Stock
pis
Linex
where must be .linex
- If a > 0, under-forecasting () is penalized more.
- If a < 0, over-forecasting () is penalized more.
- a must not be 0.
2. Percentage Errors
Mean Absolute Percentage Error
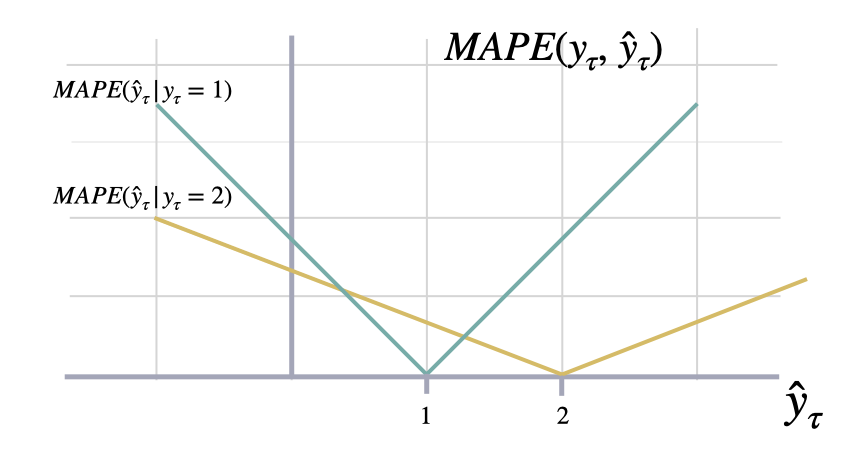
mape
Symmetric Mean Absolute Percentage Error
smape
3. Scale-independent Errors
Mean Absolute Scaled Error
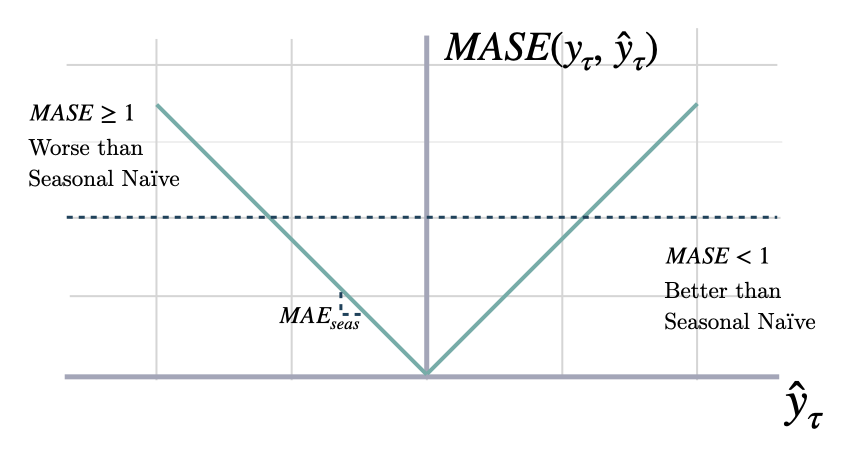
mase
Returns:
Relative Mean Absolute Error
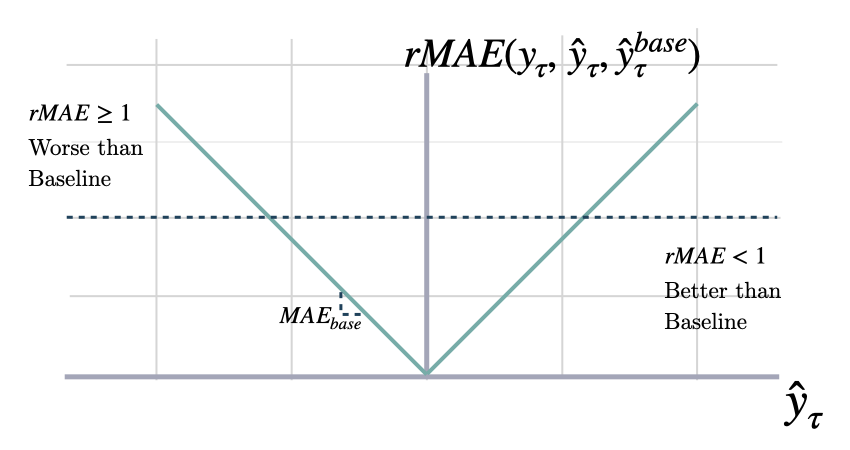
rmae
Returns:
Normalized Deviation
nd
Mean Squared Scaled Error
msse
Returns:
Root Mean Squared Scaled Error
rmsse
Returns:
Scaled Absolute Periods In Stock
where .spis
Returns:
4. Probabilistic Errors
Quantile Loss
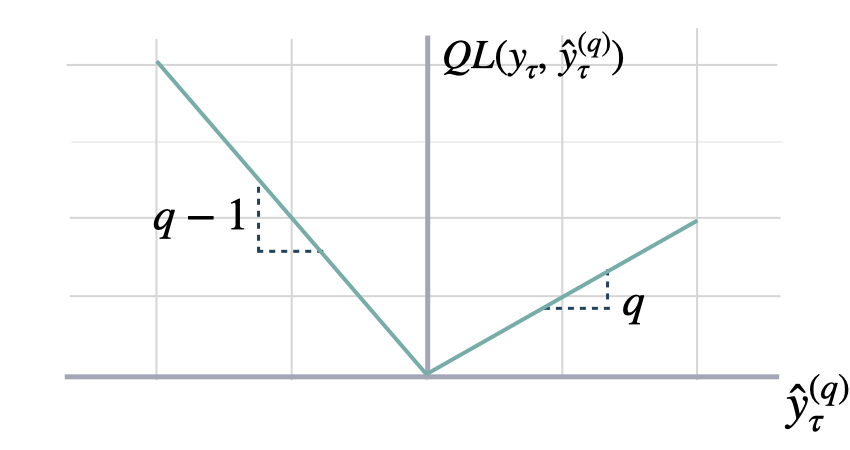
quantile_loss
Returns:
Scaled Quantile Loss
scaled_quantile_loss
Returns:
Multi-Quantile Loss
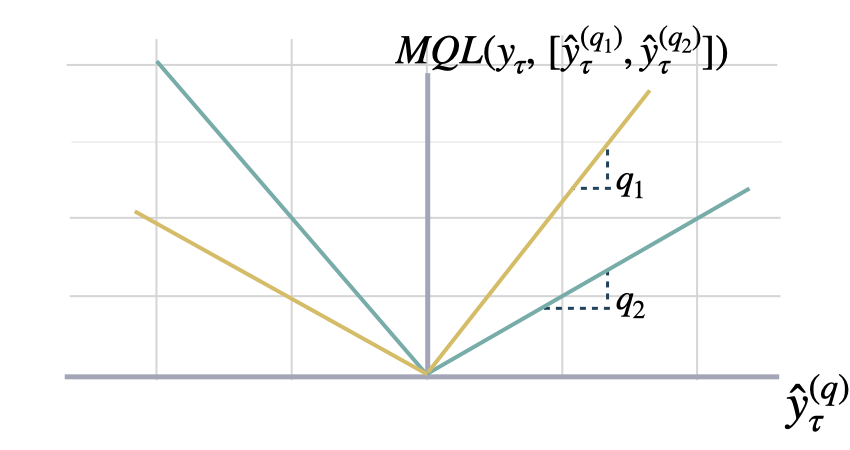
mqloss
Returns:
Scaled Multi-Quantile Loss
scaled_mqloss
Returns:
Coverage
coverage
Returns:
Calibration
calibration
Returns:
CRPS
Where is the an estimated multivariate distribution, and are its realizations.scaled_crps
y_hat compared to the observation y.
This metric averages percentual weighted absolute deviations as
defined by the quantile losses.
Parameters:
Returns:
Tweedie Deviance
For a set of forecasts and observations , the mean Tweedie deviance with power is where the unit-scaled deviance for each pair is- are the true values, the predicted means.
- controls the variance relationship .
- When , this smoothly interpolates between Poisson () and Gamma () deviance.
tweedie_deviance
power parameter defines the specific compound distribution:
- 1: Poisson
- (1, 2): Compound Poisson-Gamma
- 2: Gamma
-
2: Inverse Gaussian
Returns: