> ## Documentation Index
> Fetch the complete documentation index at: https://nixtlaverse.nixtla.io/llms.txt
> Use this file to discover all available pages before exploring further.
# AutoARIMAProphet Adapter
> AutoArima is faster and more accurate than FB-Prophet in most cases.
> Replace it with two lines of code.
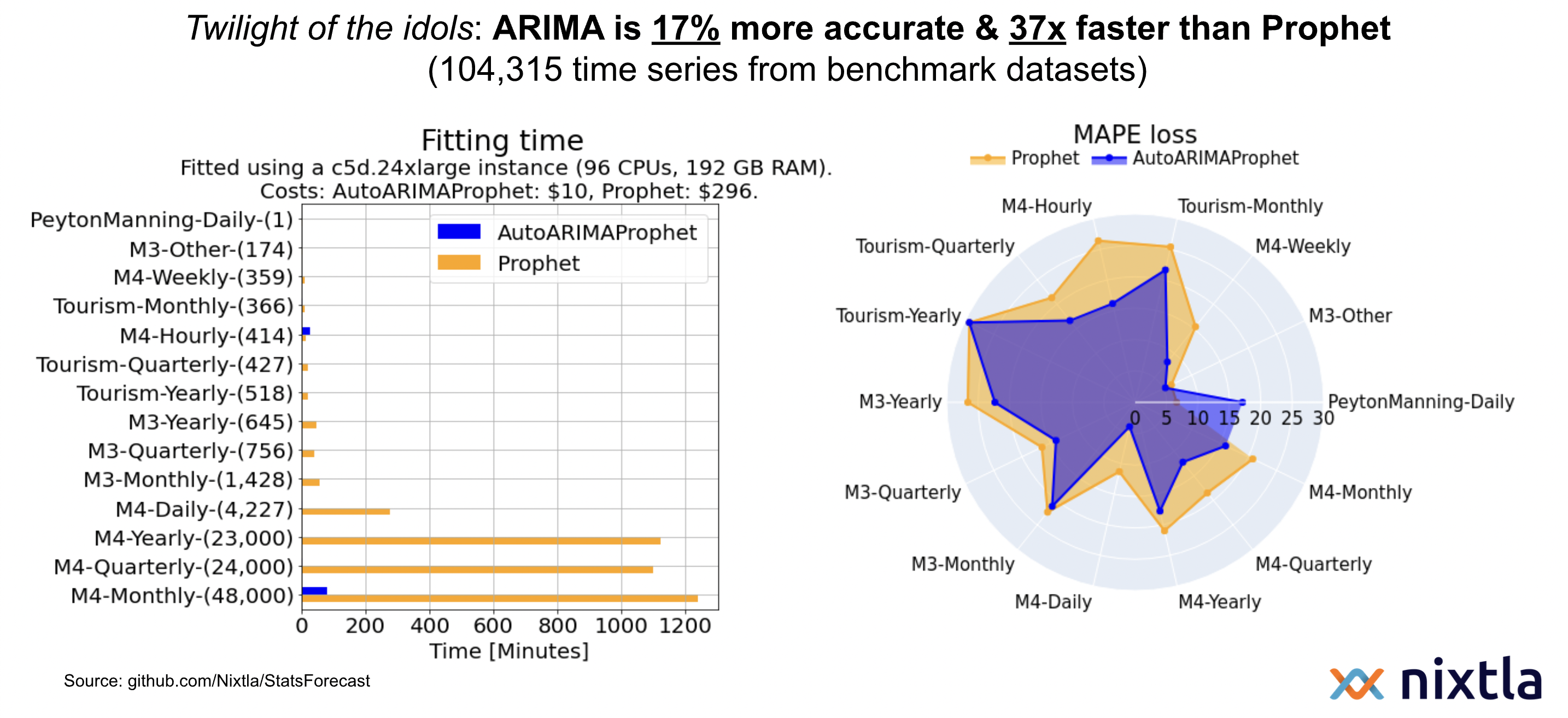
We benchmarked on more than 100K series and show that you can improve
*MAPE* and *sMAPE* forecast accuracy by *17%* and *15%* with *37x* less
computational time.
Now you can replace Prophet with two lines of code and verify it for
yourself.
### Install StatsForecast
```bash theme={null}
pip install statsforecast
```
### Replace FB-Prophet to make your forecast a lot faster
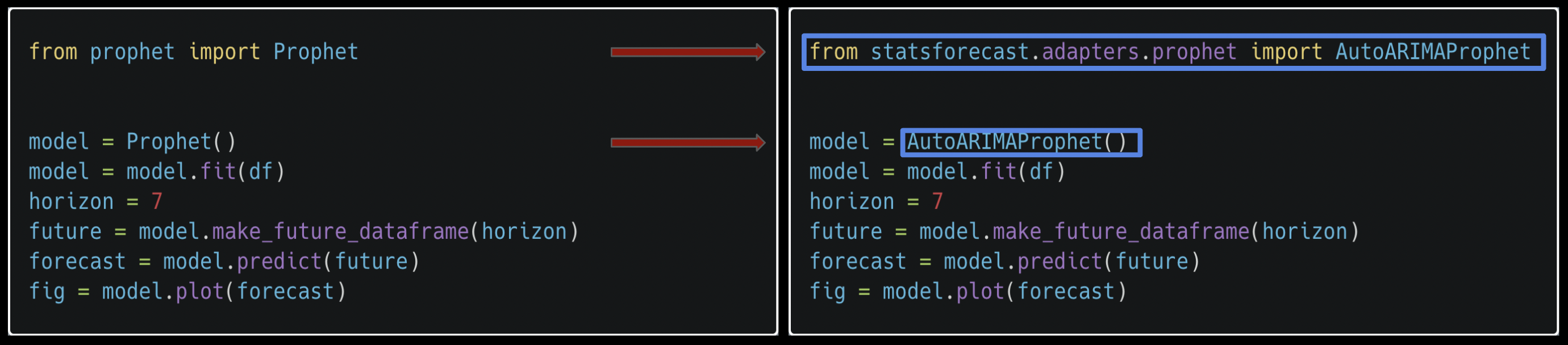 We respected the original Prophet syntax so your pipeline won’t get
affected.
## Results on M3, M4, Tourism and Peyton Manning
We respected the original Prophet syntax so your pipeline won’t get
affected.
## Results on M3, M4, Tourism and Peyton Manning
 ## Background
[FB-Prophet](https://github.com/facebook/prophet) is one of the world’s
most used time series forecasting models. Its GitHub repository has more
than 14 thousand stars, and more than a hundred repositories depend on
it. However, in many scenarios, [FB-Prophet does not offer good
performance in terms of time and
accuracy.](https://analyticsindiamag.com/why-are-people-bashing-facebook-prophet/)
This lacking performance suggests that the FB-Prophet’s success can be
explained mainly by its usability. For example, [adding exogenous and
calendar variables is almost
trivial.](https://facebook.github.io/prophet/docs/seasonality,_holiday_effects,_and_regressors.html)
To contribute to the forecasting community, we created a *FB-Prophet API
adapter* that lets you use Prophet’s useful methods without accuracy and
computational downsides. Just import this AutoARIMAProphet adapter and
replace the Prophet class to start using AutoARIMA in any of your
existing pipelines.
## Empirical validation
To validate the AutoARIMAProphet adapter, we designed a pipeline
considering the M3, M4, and Tourism datasets (standard benchmarks in the
forecasting practice) and the Peyton Manning data set originally used by
FB. The pipeline automatically selects ARIMA’s parameters with the AIC
criterion and selects Prophet’s parameters with time-series
cross-validation.
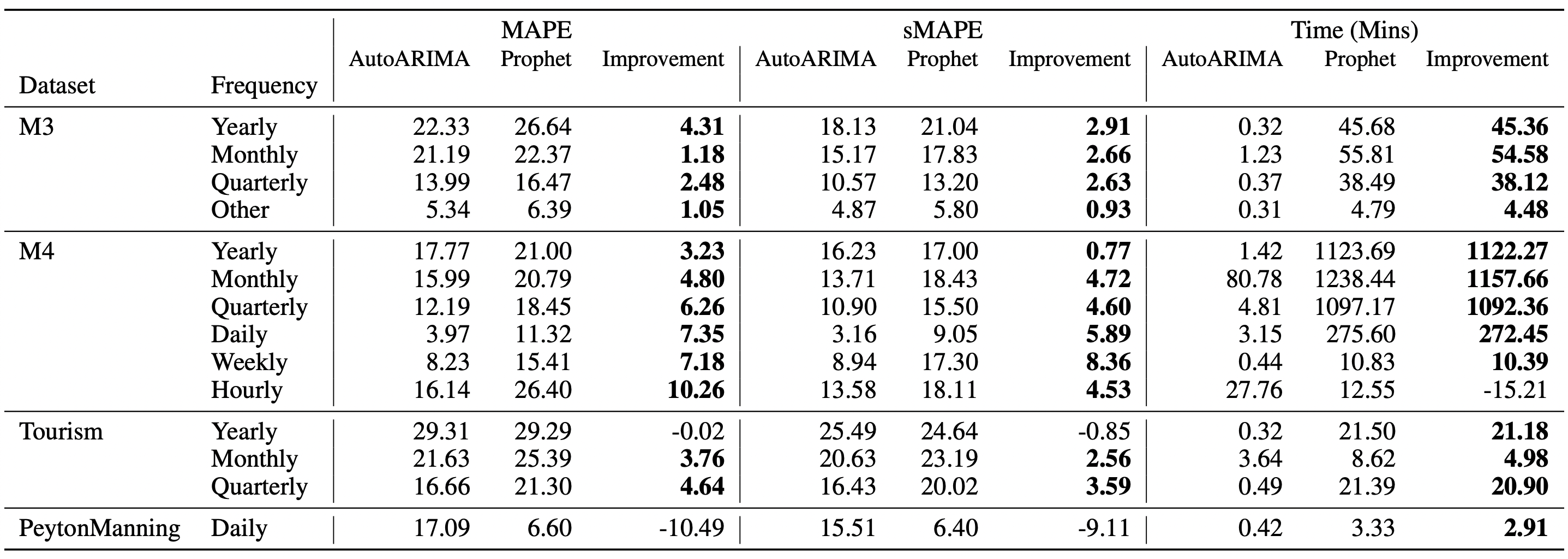
## Results
The following table shows the MAPE, sMAPE and Time (in minutes)
AutoARIMA improvements on Prophet for each dataset.
## Background
[FB-Prophet](https://github.com/facebook/prophet) is one of the world’s
most used time series forecasting models. Its GitHub repository has more
than 14 thousand stars, and more than a hundred repositories depend on
it. However, in many scenarios, [FB-Prophet does not offer good
performance in terms of time and
accuracy.](https://analyticsindiamag.com/why-are-people-bashing-facebook-prophet/)
This lacking performance suggests that the FB-Prophet’s success can be
explained mainly by its usability. For example, [adding exogenous and
calendar variables is almost
trivial.](https://facebook.github.io/prophet/docs/seasonality,_holiday_effects,_and_regressors.html)
To contribute to the forecasting community, we created a *FB-Prophet API
adapter* that lets you use Prophet’s useful methods without accuracy and
computational downsides. Just import this AutoARIMAProphet adapter and
replace the Prophet class to start using AutoARIMA in any of your
existing pipelines.
## Empirical validation
To validate the AutoARIMAProphet adapter, we designed a pipeline
considering the M3, M4, and Tourism datasets (standard benchmarks in the
forecasting practice) and the Peyton Manning data set originally used by
FB. The pipeline automatically selects ARIMA’s parameters with the AIC
criterion and selects Prophet’s parameters with time-series
cross-validation.
## Results
The following table shows the MAPE, sMAPE and Time (in minutes)
AutoARIMA improvements on Prophet for each dataset.
 ## Reproducibility
1. Create a conda environment `arima_prophet` using the
`environment.yml` file.
```shell theme={null}
conda env create -f environment.yml
```
2. Activate the conda environment using
```shell theme={null}
conda activate arima_prophet
```
3. Run the experiments for each dataset and each model using
```shell theme={null}
python -m src.experiment --dataset [dataset] --group [group] --model_name [model_name]
```
For `M4`, the groups are `Yearly`, `Monthly`, `Quarterly`, `Weekly`,
`Daily`, and `Hourly`. For `M3`, the groups are `Yearly`, `Monthly`,
`Quarterly`, and `Other`. For `Tourism`, the groups are `Yearly`,
`Monthly`, and `Quarterly`. Finally, for `PeytonManning` the group
is `Daily`.
4. Evaluate the results using
```shell theme={null}
python -m src.evaluation
```
## Conclusion
* Be mindful on what you read on Towards Data Science.
* Always use strong baselines when forecasting.
* Quick and easy results are sometimes
[misleading](https://en.wikipedia.org/wiki/Streetlight_effect).
* Simpler models are sometimes
[better](https://en.wikipedia.org/wiki/Occam%27s_razor).
* **Facebook’s Prophet might be many things, but it’s definitely not a
model for forecasting time series at scale.**
## Misc.
* [`StatsForecast`](https://github.com/nixtla/statsforecast) also
includes a variety of lightning fast baseline models.
* If you really need to do forecast at scale,
[here](https://github.com/nixtla/statsforecast/tree/main/experiments/ray)
we show how to forecast 1 million time series under 30 minutes using
[Ray](https://github.com/ray-project/ray).
* If you are interested in SOTA Deep Learning models, check
[`NeuralForecast`](https://github.com/nixtla/neuralforecast).
## Reproducibility
1. Create a conda environment `arima_prophet` using the
`environment.yml` file.
```shell theme={null}
conda env create -f environment.yml
```
2. Activate the conda environment using
```shell theme={null}
conda activate arima_prophet
```
3. Run the experiments for each dataset and each model using
```shell theme={null}
python -m src.experiment --dataset [dataset] --group [group] --model_name [model_name]
```
For `M4`, the groups are `Yearly`, `Monthly`, `Quarterly`, `Weekly`,
`Daily`, and `Hourly`. For `M3`, the groups are `Yearly`, `Monthly`,
`Quarterly`, and `Other`. For `Tourism`, the groups are `Yearly`,
`Monthly`, and `Quarterly`. Finally, for `PeytonManning` the group
is `Daily`.
4. Evaluate the results using
```shell theme={null}
python -m src.evaluation
```
## Conclusion
* Be mindful on what you read on Towards Data Science.
* Always use strong baselines when forecasting.
* Quick and easy results are sometimes
[misleading](https://en.wikipedia.org/wiki/Streetlight_effect).
* Simpler models are sometimes
[better](https://en.wikipedia.org/wiki/Occam%27s_razor).
* **Facebook’s Prophet might be many things, but it’s definitely not a
model for forecasting time series at scale.**
## Misc.
* [`StatsForecast`](https://github.com/nixtla/statsforecast) also
includes a variety of lightning fast baseline models.
* If you really need to do forecast at scale,
[here](https://github.com/nixtla/statsforecast/tree/main/experiments/ray)
we show how to forecast 1 million time series under 30 minutes using
[Ray](https://github.com/ray-project/ray).
* If you are interested in SOTA Deep Learning models, check
[`NeuralForecast`](https://github.com/nixtla/neuralforecast).