> ## Documentation Index
> Fetch the complete documentation index at: https://nixtlaverse.nixtla.io/llms.txt
> Use this file to discover all available pages before exploring further.
> BiTCN: Bidirectional Temporal Convolutional Network for forecasting. Parameter-efficient architecture with forward-backward encoding for probabilistic predictions.
# BiTCN
Bidirectional Temporal Convolutional Network (BiTCN) is a forecasting
architecture based on two temporal convolutional networks (TCNs). The
first network (‘forward’) encodes future covariates of the time series,
whereas the second network (‘backward’) encodes past observations and
covariates. This method allows to preserve the temporal information of
sequence data, and is computationally more efficient than common RNN
methods (LSTM, GRU, …). As compared to Transformer-based methods, BiTCN
has a lower space complexity, i.e. it requires orders of magnitude less
parameters.
This model may be a good choice if you seek a small model (small amount
of trainable parameters) with few hyperparameters to tune (only 2).
**References**
* [Olivier Sprangers, Sebastian Schelter, Maarten de
Rijke (2023). Parameter-Efficient Deep Probabilistic Forecasting.
International Journal of Forecasting 39, no. 1 (1 January 2023): 332–45.
URL:
https://doi.org/10.1016/j.ijforecast.2021.11.011.](https://doi.org/10.1016/j.ijforecast.2021.11.011)
* [Shaojie Bai, Zico Kolter, Vladlen Koltun. (2018). An Empirical
Evaluation of Generic Convolutional and Recurrent Networks for Sequence
Modeling. Computing Research Repository, abs/1803.01271. URL:
https://arxiv.org/abs/1803.01271.](https://arxiv.org/abs/1803.01271)
* [van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O.,
Graves, A., Kalchbrenner, N., Senior, A. W., & Kavukcuoglu, K. (2016).
Wavenet: A generative model for raw audio. Computing Research
Repository, abs/1609.03499. URL: http://arxiv.org/abs/1609.03499.
arXiv:1609.03499.](https://arxiv.org/abs/1609.03499)
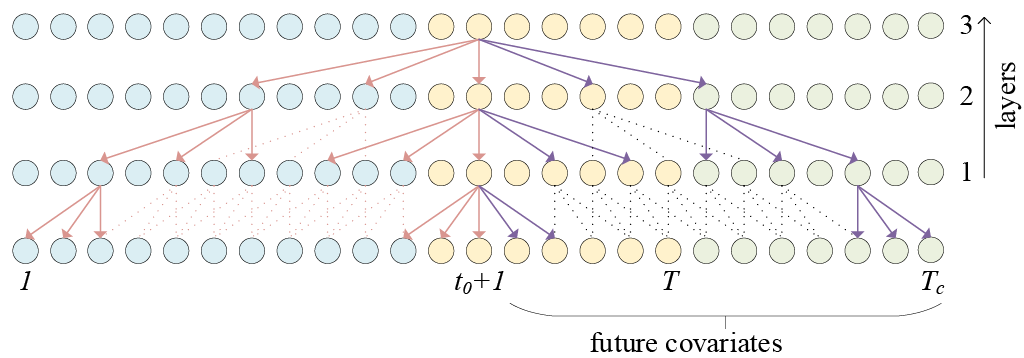 *Figure 1. Visualization of a stack of dilated causal convolutional layers.*
## 1. BiTCN
### `BiTCN`
```python theme={null}
BiTCN(
h,
input_size,
hidden_size=16,
dropout=0.5,
futr_exog_list=None,
hist_exog_list=None,
stat_exog_list=None,
exclude_insample_y=False,
loss=MAE(),
valid_loss=None,
max_steps=1000,
learning_rate=0.001,
num_lr_decays=-1,
early_stop_patience_steps=-1,
val_monitor="ptl/val_loss",
val_check_steps=100,
batch_size=32,
valid_batch_size=None,
windows_batch_size=1024,
inference_windows_batch_size=1024,
start_padding_enabled=False,
training_data_availability_threshold=0.0,
step_size=1,
scaler_type="identity",
random_seed=1,
drop_last_loader=False,
alias=None,
optimizer=None,
optimizer_kwargs=None,
lr_scheduler=None,
lr_scheduler_kwargs=None,
dataloader_kwargs=None,
**trainer_kwargs
)
```
Bases:
*Figure 1. Visualization of a stack of dilated causal convolutional layers.*
## 1. BiTCN
### `BiTCN`
```python theme={null}
BiTCN(
h,
input_size,
hidden_size=16,
dropout=0.5,
futr_exog_list=None,
hist_exog_list=None,
stat_exog_list=None,
exclude_insample_y=False,
loss=MAE(),
valid_loss=None,
max_steps=1000,
learning_rate=0.001,
num_lr_decays=-1,
early_stop_patience_steps=-1,
val_monitor="ptl/val_loss",
val_check_steps=100,
batch_size=32,
valid_batch_size=None,
windows_batch_size=1024,
inference_windows_batch_size=1024,
start_padding_enabled=False,
training_data_availability_threshold=0.0,
step_size=1,
scaler_type="identity",
random_seed=1,
drop_last_loader=False,
alias=None,
optimizer=None,
optimizer_kwargs=None,
lr_scheduler=None,
lr_scheduler_kwargs=None,
dataloader_kwargs=None,
**trainer_kwargs
)
```
Bases: [BaseModel](#neuralforecast.common._base_model.BaseModel)
BiTCN
Bidirectional Temporal Convolutional Network (BiTCN) is a forecasting architecture based on two temporal convolutional networks (TCNs). The first network ('forward') encodes future covariates of the time series, whereas the second network ('backward') encodes past observations and covariates. This is a univariate model.
**Parameters:**
| Name | Type | Description | Default |
| -------------------------------------- | ------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------- |
| `h` | [int](#int) | forecast horizon. | *required* |
| `input_size` | [int](#int) | considered autorregresive inputs (lags), y=\[1,2,3,4] input\_size=2 -> lags=\[1,2]. | *required* |
| `hidden_size` | [int](#int) | units for the TCN's hidden state size. Default: 16. | 16 |
| `dropout` | [float](#float) | dropout rate used for the dropout layers throughout the architecture. Default: 0.1. | 0.5 |
| `futr_exog_list` | [list](#list) | future exogenous columns. | None |
| `hist_exog_list` | [list](#list) | historic exogenous columns. | None |
| `stat_exog_list` | [list](#list) | static exogenous columns. | None |
| `exclude_insample_y` | [bool](#bool) | the model skips the autoregressive features y\[t-input\_size:t] if True. Default: False. | False |
| `loss` | [Module](#torch.nn.Module) | PyTorch module, instantiated train loss class from [losses collection](./losses.pytorch.html). | [MAE](#neuralforecast.losses.pytorch.MAE)() |
| `valid_loss` | [Module](#torch.nn.Module) | PyTorch module, instantiated valid loss class from [losses collection](./losses.pytorch.html). | None |
| `max_steps` | [int](#int) | maximum number of training steps. Default: 1000. | 1000 |
| `learning_rate` | [float](#float) | Learning rate between (0, 1). Default: 1e-3. | 0.001 |
| `num_lr_decays` | [int](#int) | Number of learning rate decays, evenly distributed across max\_steps. Default: -1. | -1 |
| `early_stop_patience_steps` | [int](#int) | Number of validation iterations before early stopping. Default: -1. | -1 |
| `val_monitor` | [str](#str) | metric to monitor for early stopping. Valid options: "ptl/val\_loss", "valid\_loss", "train\_loss". Default: "ptl/val\_loss". | 'ptl/val\_loss' |
| `val_check_steps` | [int](#int) | Number of training steps between every validation loss check. Default: 100. | 100 |
| `batch_size` | [int](#int) | number of different series in each batch. Default: 32. | 32 |
| `valid_batch_size` | [int](#int) | number of different series in each validation and test batch, if None uses batch\_size. Default: None. | None |
| `windows_batch_size` | [int](#int) | number of windows to sample in each training batch, default uses all. Default: 1024. | 1024 |
| `inference_windows_batch_size` | [int](#int) | number of windows to sample in each inference batch, -1 uses all. Default: 1024. | 1024 |
| `start_padding_enabled` | [bool](#bool) | if True, the model will pad the time series with zeros at the beginning, by input size. Default: False. | False |
| `training_data_availability_threshold` | [Union](#Union)\[[float](#float), [List](#List)\[[float](#float)]] | minimum fraction of valid data points required for training windows. Single float applies to both insample and outsample; list of two floats specifies \[insample\_fraction, outsample\_fraction]. Default 0.0 allows windows with only 1 valid data point (current behavior). Default: 0.0. | 0.0 |
| `step_size` | [int](#int) | step size between each window of temporal data. Default: 1. | 1 |
| `scaler_type` | [str](#str) | type of scaler for temporal inputs normalization see [temporal scalers](https://github.com/Nixtla/neuralforecast/blob/main/neuralforecast/common/_scalers.py). Default: 'identity'. | 'identity' |
| `random_seed` | [int](#int) | random\_seed for pytorch initializer and numpy generators. Default: 1. | 1 |
| `drop_last_loader` | [bool](#bool) | if True `TimeSeriesDataLoader` drops last non-full batch. Default: False. | False |
| `alias` | [str](#str) | optional, Custom name of the model. Default: None. | None |
| `optimizer` | Subclass of 'torch.optim.Optimizer' | optional, user specified optimizer instead of the default choice (Adam). | None |
| `optimizer_kwargs` | [dict](#dict) | optional, list of parameters used by the user specified `optimizer`. | None |
| `lr_scheduler` | Subclass of 'torch.optim.lr\_scheduler.LRScheduler' | optional, user specified lr\_scheduler instead of the default choice (StepLR). | None |
| `lr_scheduler_kwargs` | [dict](#dict) | optional, list of parameters used by the user specified `lr_scheduler`. | None |
| `dataloader_kwargs` | [dict](#dict) | optional, list of parameters passed into the PyTorch Lightning dataloader by the `TimeSeriesDataLoader`. | None |
| `**trainer_kwargs` | [int](#int) | keyword trainer arguments inherited from [PyTorch Lighning's trainer](https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.trainer.trainer.Trainer.html?highlight=trainer). | {} |
References
* [Olivier Sprangers, Sebastian Schelter, Maarten de Rijke (2023). Parameter-Efficient Deep Probabilistic Forecasting. International Journal of Forecasting 39, no. 1 (1 January 2023): 333-345.](https://doi.org/10.1016/j.ijforecast.2021.11.011)
#### `BiTCN.fit`
```python theme={null}
fit(
dataset, val_size=0, test_size=0, random_seed=None, distributed_config=None
)
```
Fit.
The `fit` method, optimizes the neural network's weights using the
initialization parameters (`learning_rate`, `windows_batch_size`, ...)
and the `loss` function as defined during the initialization.
Within `fit` we use a PyTorch Lightning `Trainer` that
inherits the initialization's `self.trainer_kwargs`, to customize
its inputs, see [PL's trainer arguments](https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.trainer.trainer.Trainer.html?highlight=trainer).
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the `model` is not saving training checkpoints to protect
disk memory, to get them change `enable_checkpointing=True` in `__init__`.
**Parameters:**
| Name | Type | Description | Default |
| ------------- | ---------------------------------------------------- | -------------------------------------------------------------------------------------- | ----------------- |
| `dataset` | [TimeSeriesDataset](#TimeSeriesDataset) | NeuralForecast's `TimeSeriesDataset`, see [documentation](./tsdataset.html). | *required* |
| `val_size` | [int](#int) | Validation size for temporal cross-validation. | 0 |
| `random_seed` | [int](#int) | Random seed for pytorch initializer and numpy generators, overwrites model.**init**'s. | None |
| `test_size` | [int](#int) | Test size for temporal cross-validation. | 0 |
**Returns:**
| Type | Description |
| ---- | ----------- |
| None | |
#### `BiTCN.predict`
```python theme={null}
predict(
dataset,
test_size=None,
step_size=1,
random_seed=None,
quantiles=None,
h=None,
explainer_config=None,
**data_module_kwargs
)
```
Predict.
Neural network prediction with PL's `Trainer` execution of `predict_step`.
**Parameters:**
| Name | Type | Description | Default |
| ---------------------- | ---------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------ | ----------------- |
| `dataset` | [TimeSeriesDataset](#TimeSeriesDataset) | NeuralForecast's `TimeSeriesDataset`, see [documentation](./tsdataset.html). | *required* |
| `test_size` | [int](#int) | Test size for temporal cross-validation. | None |
| `step_size` | [int](#int) | Step size between each window. | 1 |
| `random_seed` | [int](#int) | Random seed for pytorch initializer and numpy generators, overwrites model.**init**'s. | None |
| `quantiles` | [list](#list) | Target quantiles to predict. | None |
| `h` | [int](#int) | Prediction horizon, if None, uses the model's fitted horizon. Defaults to None. | None |
| `explainer_config` | [dict](#dict) | configuration for explanations. | None |
| `**data_module_kwargs` | [dict](#dict) | PL's TimeSeriesDataModule args, see [documentation](https://pytorch-lightning.readthedocs.io/en/1.6.1/extensions/datamodules.html#using-a-datamodule). | {} |
**Returns:**
| Type | Description |
| ---- | ----------- |
| None | |
### Usage Example
```python theme={null}
import pandas as pd
import matplotlib.pyplot as plt
from neuralforecast import NeuralForecast
from neuralforecast.losses.pytorch import GMM
from neuralforecast.models import BiTCN
from neuralforecast.utils import AirPassengersPanel, AirPassengersStatic
Y_train_df = AirPassengersPanel[AirPassengersPanel.ds=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True) # 12 test
fcst = NeuralForecast(
models=[
BiTCN(h=12,
input_size=24,
loss=GMM(n_components=7, level=[80,90]),
max_steps=100,
scaler_type='standard',
futr_exog_list=['y_[lag12]'],
hist_exog_list=None,
stat_exog_list=['airline1'],
windows_batch_size=2048,
val_check_steps=10,
early_stop_patience_steps=-1,
),
],
freq='ME'
)
fcst.fit(df=Y_train_df, static_df=AirPassengersStatic)
forecasts = fcst.predict(futr_df=Y_test_df)
# Plot quantile predictions
Y_hat_df = forecasts.reset_index(drop=False).drop(columns=['unique_id','ds'])
plot_df = pd.concat([Y_test_df, Y_hat_df], axis=1)
plot_df = pd.concat([Y_train_df, plot_df])
plot_df = plot_df[plot_df.unique_id=='Airline1'].drop('unique_id', axis=1)
plt.plot(plot_df['ds'], plot_df['y'], c='black', label='True')
plt.plot(plot_df['ds'], plot_df['BiTCN-median'], c='blue', label='median')
plt.fill_between(x=plot_df['ds'][-12:],
y1=plot_df['BiTCN-lo-90'][-12:].values,
y2=plot_df['BiTCN-hi-90'][-12:].values,
alpha=0.4, label='level 90')
plt.legend()
plt.grid()
```
## 2. Auxilary functions
### `TCNCell`
```python theme={null}
TCNCell(
in_channels,
out_channels,
kernel_size,
padding,
dilation,
mode,
groups,
dropout,
)
```
Bases: [Module](#torch.nn.Module)
Temporal Convolutional Network Cell, consisting of CustomConv1D modules.
### `CustomConv1d`
```python theme={null}
CustomConv1d(
in_channels,
out_channels,
kernel_size,
padding=0,
dilation=1,
mode="backward",
groups=1,
)
```
Bases: [Module](#torch.nn.Module)
Forward- and backward looking Conv1D